合 MPP数据库之StarRocks介绍
Apache Doris 和 DorisDB、StarRocks之间的关系
Doris最早是解决百度凤巢统计报表的专用系统,随着百度业务的飞速发展对系统进行了多次迭代,逐渐承担起百度内部业务的统计报表和多维分析需求。2013 年,我们把 Doris 进行了 MPP 框架的升级,并将新系统命名为 Palo ,2017 年我们以百度 Palo 的名字在 GitHub 上进行了开源,2018 年贡献给 Apache 基金会时,由于与国外数据库厂商重名,因此选择用回最初的名字,这就是 Apache Doris 的由来。- 2020 年 2 月,百度 Doris 团队的个别同学离职创业,基于 Apache Doris做了自己的商业化闭源产品 DorisDB ,这就是 StarRocks 的前身。
【总结】Doris属于百度的,Apache Doris是有百度贡献给Apache 的,DorisDB是百度前员工基于Apache Doris做的商业版本属于另外的公司,后面因为版权的问题,将DorisDB改名为StarRocks,所以StarRocks和DorisDB是属于一个产品,一个公司的。不知道小伙伴,还记不记得另外一个产品的经历跟Doris的经历非常的相似,那就是presto。这里主要讲StarRocks,因为StarRocks更新迭代很快,活跃度也高。
Apache Doris GitHub地址:https://github.com/apache/doris
Apache Doris 官网文档:https://doris.apache.org/docs/get-starting/get-starting.html
StarRocks GitHub地址:https://github.com/StarRocks/starrocks
StarRocks官方文档:https://docs.starrocks.com/zh-cn/main/introduction/StarRocks_intro
StarRocks概述
StarRocks是一款高性能分析型数据仓库,使用向量化、MPP(Massively Parallel Processing:大规模并行处理) 架构、可实时更新的列式存储引擎等技术实现多维、实时、高并发的数据分析。StarRocks 既支持从各类实时和离线的数据源高效导入数据,也支持直接分析数据湖上各种格式的数据。StarRocks 兼容 MySQL 协议,可使用 MySQL 客户端和常用 BI 工具对接。同时 StarRocks 具备水平扩展,高可用,高可靠,易运维等特性。广泛应用于实时数仓、OLAP 报表、数据湖分析等场景。
1)特征
- 原生向量化 SQL 引擎: StarRocks 采用向量化技术,充分利用 CPU 的并行计算能力,在多维分析中实现亚秒级的查询返回,比之前的系统快 5 到 10 倍。
- 标准 SQL: StarRocks 支持 ANSI SQL 语法(完全支持 TPC-H 和 TPC-DS)。它还与 MySQL 协议兼容。可以使用各种客户端和 BI 软件来访问 StarRocks。
- 智能查询优化: StarRocks 可以通过 CBO(Cost Based Optimizer)优化复杂查询。有了更好的执行计划,数据分析效率会大大提高。
- 实时更新: StarRocks的更新模型可以根据主键进行upsert/delete操作,在并发更新的同时实现高效查询。
- 智能物化视图: StarRocks的物化视图可以在数据导入过程中自动更新,在执行查询时自动选择。
- 直接查询数据湖中的数据:StarRocks 允许直接访问来自 Apache Hive™、Apache Iceberg™ 和 Apache Hudi™ 的数据,而无需导入。
- 资源管理:该特性允许 StarRocks 限制查询的资源消耗,实现同一集群内租户之间的资源隔离和高效使用。
- 易于维护:简单的架构使 StarRocks 易于部署、维护和横向扩展。StarRocks 敏捷调整查询计划,在集群扩容或扩容时均衡资源,在节点故障下自动恢复数据副本。
- 列式存储:StarRocks实现了列式存储引擎,数据以按列的方式进行存储。通过这样的方式,相同类型的数据连续存放。一方面,数据可以使用更加高效的编码方式,获得更高的压缩比,降低存储成本。另一方面,也降低了系统读取数据的IO总量,提升了查询性能。此外,在大部分OLAP场景中,查询只会涉及部分列。相对于行存,列存只需要读取部分列的数据,能够极大地降低磁盘IO吞吐。
- 原子性:StarRocks的存储引擎在数据导入时能够保证每一次操作的ACID。一个批次的导入数据生效是原子性的,要么全部导入成功,要么全部失败。并发进行的各个事务相互之间互不影响,对外提供Snapshot Isolation的事务隔离级别。
- 支持Upsert 类操作:StarRocks存储引擎不仅能够提供高效的 Append 操作,也能高效的处理 Upsert 类操作。使用
Delete-and-insert的实现方式,通过主键索引快速过滤,消除了读取时 Sort merge 操作,同时还可以充分利用其他二级索引。可以在大量更新的场景下,仍然可以保证查询的极速性能。
2)适用场景
StarRocks 可以满足企业级用户的多种分析需求,包括 OLAP 多维分析、定制报表、实时数据分析和 Ad-hoc 数据分析等。
1、OLAP 多维分析
利用 StarRocks 的 MPP 框架和向量化执行引擎,用户可以灵活的选择雪花模型,星型模型,宽表模型或者预聚合模型。适用于灵活配置的多维分析报表,业务场景包括:
- 用户行为分析
- 用户画像、标签分析、圈人
- 高维业务指标报表
- 自助式报表平台
- 业务问题探查分析
- 跨主题业务分析
- 财务报表
- 系统监控分析
2、实时数据仓库
StarRocks 设计和实现了 Primary-Key 模型,能够实时更新数据并极速查询,可以秒级同步 TP 数据库的变化,构建实时数仓,业务场景包括:
- 电商大促数据分析
- 物流行业的运单分析
- 金融行业绩效分析、指标计算
- 直播质量分析
- 广告投放分析
- 管理驾驶舱
- 探针分析APM(Application Performance Management)
3、高并发查询
StarRocks 通过良好的数据分布特性,灵活的索引索引以及物化视图等特性,可以解决面向用户侧的分析场景,业务场景包括:
- 广告主报表分析
- 零售行业渠道人员分析
- SaaS 行业面向用户分析报表
- Dashboard 多页面分析
4、统一分析
- 通过使用一套系统解决多维分析、高并发查询、预计算、实时分析查询等场景,降低系统复杂度和多技术栈开发与维护成本。
- 使用StarRocks 来统一数据湖和数据仓库,将高并发和实时要求性很高的业务放在StarRocks中分析,把数据湖上的分析使用StarRocks外表查询,统一使用 StarRocks 管理湖仓数据。
StarRocks架构
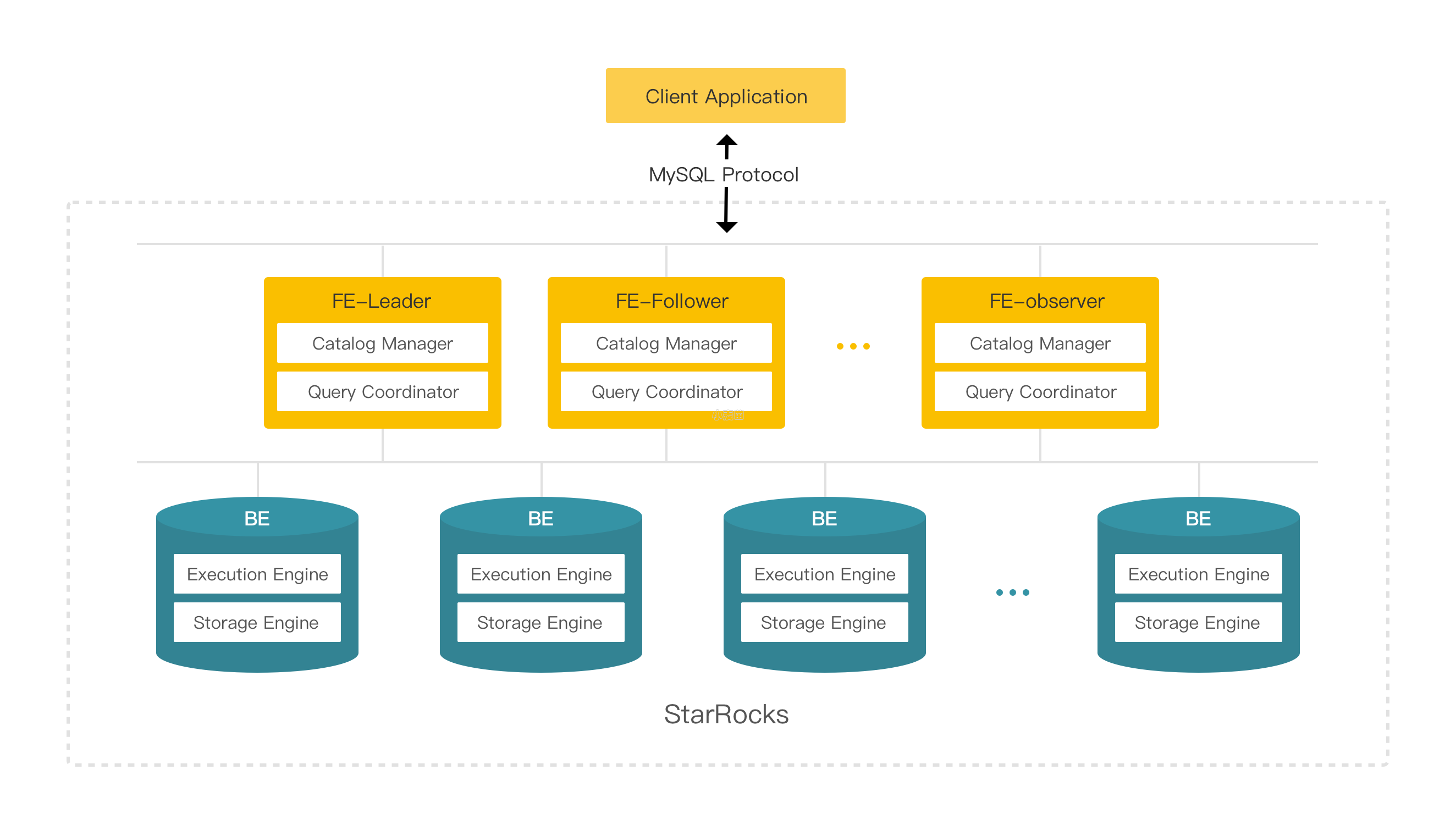
StarRocks的架构简洁,整个系统的核心只有FE(Frontend)和 BE(Backend)两类进程,不依赖任何外部组件,方便部署与维护。同时,FE和BE模块都可以在线水平扩展,元数据和数据都有副本机制,确保整个系统无单点。
1)FE(Frontend)
Frontend是StarRocks的前端节点,负责管理元数据,管理客户端连接,进行查询规划,查询调度等工作。每个 FE 节点都会在内存保留一份完整的元数据,这样每个 FE 节点都能够提供无差别的服务。
FE 有三种角色:Leader FE,Follower FE 和 Observer FE。Follower 会通过类 Paxos 的 Berkeley DB Java Edition(BDBJE)协议自动选举出一个 Leader。三者区别如下:
- Leader
- Leader 从 Follower 中自动选出,进行选主需要集群中有半数以上的 Follower 节点存活。如果 Leader 节点失败,Follower 会发起新一轮选举。
- Leader FE 提供元数据读写服务。只有 Leader 节点会对元数据进行写操作,Follower 和 Observer 只有读取权限。Follower 和 Observer 将元数据写入请求路由到 Leader 节点,Leader 更新完数据后,会通过 BDB JE 同步给 Follower 和 Observer。必须有半数以上的 Follower 节点同步成功才算作元数据写入成功。
- Follower
- 只有元数据读取权限,无写入权限。通过回放 Leader 的元数据日志来异步同步数据。
- 参与 Leader 选举,必须有半数以上的 Follower 节点存活才能进行选主。
- Observer
- 主要用于扩展集群的查询并发能力,可选部署。
- 不参与选主,不会增加集群的选主压力。
- 通过回放 Leader 的元数据日志来异步同步数据。
2)BE(Backend)
Backend是StarRocks的后端节点,负责数据存储以及SQL执行等工作。
- 数据存储方面,StarRocks 的 BE 节点都是完全对等的,FE 按照一定策略将数据分配到对应的 BE 节点。BE 负责将导入数据写成对应的格式存储下来,并生成相关索引。
- 在执行 SQL 计算时,一条 SQL 语句首先会按照具体的语义规划成逻辑执行单元,然后再按照数据的分布情况拆分成具体的物理执行单元。物理执行单元会在对应的数据存储节点上执行,这样可以实现本地计算,避免数据的传输与拷贝,从而能够得到极致的查询性能。
在进行 Stream load 导入时,FE 会选定一个 BE 节点作为 Coordinator BE,负责将数据分发到其他 BE 节点。导入的最终结果由 Coordinator BE 返回给用户。
数据管理
StarRocks 使用列式存储,采用分区分桶机制进行数据管理。一张表可以被划分成多个分区,如将一张表按照时间来进行分区,粒度可以是一天,或者一周等。一个分区内的数据可以根据一列或者多列进行分桶,将数据切分成多个 Tablet。Tablet 是 StarRocks 中最小的数据管理单元。每个 Tablet 都会以多副本 (replica) 的形式存储在不同的 BE 节点中。您可以自行指定 Tablet 的个数和大小。 StarRocks 会管理好每个 Tablet 副本的分布信息。
下图展示了 StarRocks 的数据划分以及 Tablet 多副本机制。图中,表按照日期划分为 4 个分区,第一个分区进一步切分成 4 个 Tablet。每个 Tablet 使用 3 副本进行备份,分布在 3 个不同的 BE 节点上。
Table数据划分 + Tablet三副本的数据分布如下图:
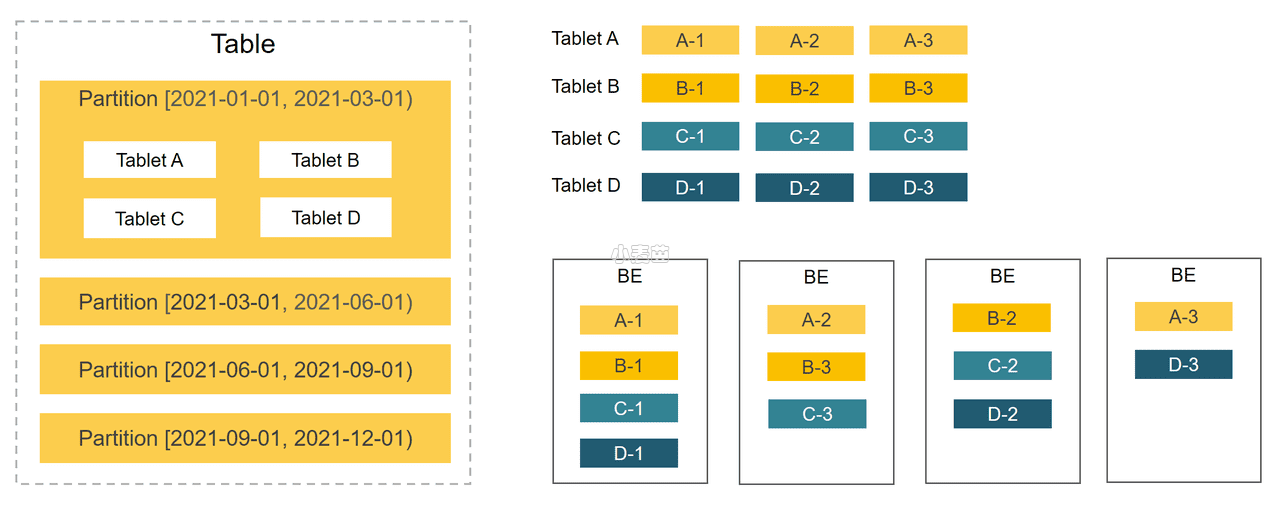
- 在StarRocks里,一张表的数据会被拆分成多个Tablet,而每个Tablet都会以多副本的形式存储在BE节点中。
- StarRocks通过分区、分桶两种划分方式将Table划分成Tablet。
- 通过分区机制(Sharding),一张表可以被划分成多个分区,如将一张表按照时间来进行分区,粒度可以是一天,或者一周等。
- 一个分区内的数据可以根据一列、或者多列进行分桶,将数据切分成多个Tablet。
- 用户可以自行指定分桶的大小。StarRocks会管理好每个Tablet副本的分布信息。
- 由于一张表被切分成了多个Tablet,StarRocks在执行SQL语句时,可以对所有Tablet实现并发处理,从而充分的利用多机、多核提供的计算能力。
- 在BE节点规模发生变化时,比如在扩容、缩容时,StarRocks可以做到无需停止服务,直接完成节点的增减。
- StarRocks支持Tablet多副本存储,默认副本数为三个。多副本够保证数据存储的高可靠,以及服务的高可用。
由于一张表被切分成了多个 Tablet,StarRocks 在执行 SQL 语句时,可以对所有 Tablet 实现并发处理,从而充分的利用多机、多核提供的计算能力。用户也可以利用 StarRocks 数据的切分方式,将高并发请求压力分摊到多个物理节点,从而可以通过增加物理节点的方式来扩展系统支持高并发的能力。
Tablet 的分布方式与具体的物理节点没有相关性。在 BE 节点规模发生变化时,比如在扩容、缩容时,StarRocks 可以做到无需停止服务,直接完成节点的增减。节点的变化会触发 Tablet 的自动迁移。当节点增加时,一部分 Tablet 会在后台自动被均衡到新增的节点,从而使得数据能够在集群内分布的更加均衡。在节点减少时,下线机器上的 Tablet 会被自动均衡到其他节点,从而自动保证数据的副本数不变。管理员能够非常容易地实现 StarRocks 的弹性伸缩,无需手工进行任何数据的重分布。
StarRocks 支持 Tablet 多副本存储,默认副本数为三个。多副本能够保证数据存储的高可靠以及服务的高可用。在使用三副本的情况下,一个节点的异常不会影响服务的可用性,集群的读、写服务仍然能够正常进行。另外,增加副本数还有助于提高系统的高并发查询能力。
产品特性
MPP 分布式执行框架
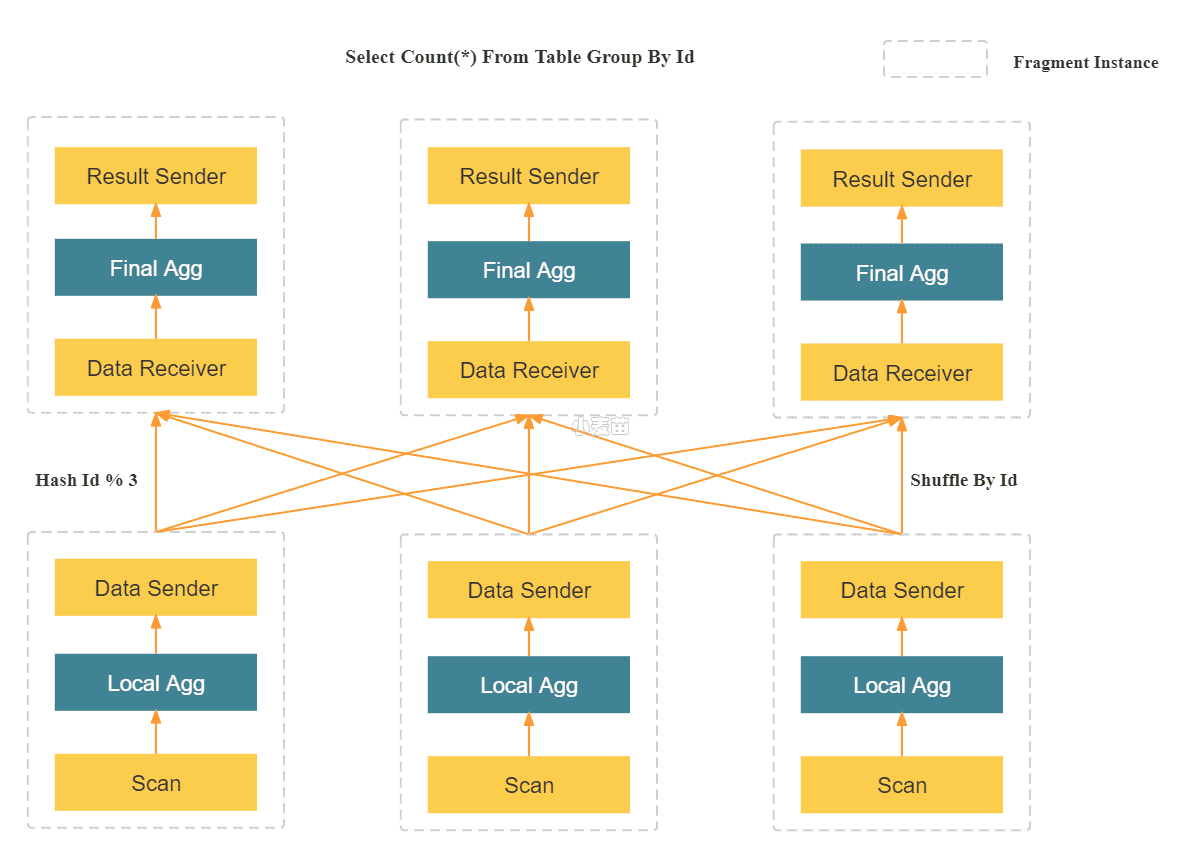
StarRocks 采用 MPP (Massively Parallel Processing) 分布式执行框架。在 MPP 执行框架中,一条查询请求会被拆分成多个物理计算单元,在多机并行执行。每个执行节点拥有独享的资源(CPU、内存)。MPP 执行框架能够使得单个查询请求可以充分利用所有执行节点的资源,所以单个查询的性能可以随着集群的水平扩展而不断提升。
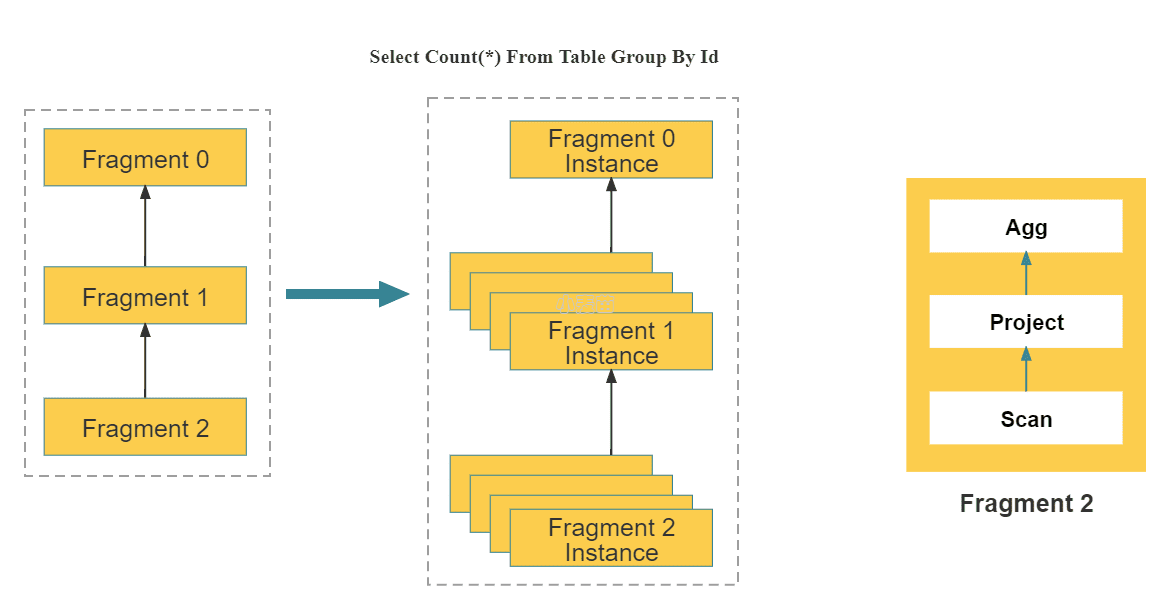
如上图所示,StarRocks 会将一个查询在逻辑上切分为多个逻辑执行单元(Query Fragment)。按照每个逻辑执行单元需要处理的计算量,每个逻辑执行单元会由一个或者多个物理执行单元来具体实现。物理执行单元是最小的调度单位。一个物理执行单元会被调度到集群某个 BE 上执行。一个逻辑执行单元可以包括一个或者多个执行算子,如图中的 Fragment 包括了 Scan,Project,Aggregate。每个物理执行单元只处理部分数据。由于每个逻辑执行单元处理的复杂度不一样,所以每个逻辑执行单元的并行度是不一样的,即,不同逻辑执行单元可以由不同数目的物理执行单元来具体执行,以提高资源使用率,提升查询速度。