
原 Oracle之library cache系列等待事件分析方法总结(持续更新)
Tags: Oracle原创总结版本数高(High Version Count)library cache lock游标失效library cache: mutex Xversion_rpt解析失败cursor: pin S wait on X游标共享cursor: pin S
- 相关等待事件介绍
- 1、library cache lock
- 2、library cache: mutex X
- 3、enq: TX - row lock contention
- 4、cursor: mutex S和cursor: mutex X
- 5、cursor: pin S wait on X和cursor: pin S
- cursor: pin S wait on X
- cursor: pin S
- 游标不能共享(version count过高)的一些原因
- 游标解析失败
- 游标失效(INVALIDATE)介绍
- 其它分析
- AWR报告分析
- Version Count 、游标失效、游标Reloads示例
- library cache: mutex X示例
- SQL AREA BUILD
- Systemstate dump示例SQL AREA BUILD
- CURSOR_SHARING=SIMILAR参数说明
- 等待事件解决方案
- 相关SQL
- version_rpt3_25.sql脚本内容
- 相关案例
- 参考
相关等待事件介绍
library cache lock和library cache: mutex X常常伴随出现,且会出现少量的cursor: mutex S和cursor: mutex X和cursor: pin S wait on X和cursor: pin S等待事件。
1、library cache lock
library cache lock是Oracle内存结构中的一种内部锁机制,用于保护库缓存(Library Cache)中的共享SQL和PL/SQL代码对象的并发访问。库缓存是Oracle数据库中用于存储已解析过的SQL语句和执行计划、PL/SQL程序单元以及其他可共享的数据库对象的地方。当多个会话试图访问或修改库缓存中的同一对象时,Oracle会使用library cache lock来确保数据的一致性和并发控制。例如,在执行SQL解析、执行计划生成、PL/SQL编译、以及执行计划共享等操作时,会涉及到library cache lock的获取和释放。
产生library cache lock的一些原因:
登录密码错误或密码为空尝试过多:对于正常的系统,由于密码的更改,可能存在某些被遗漏的客户端,不断重复尝试使用错误密码登录数据库,从而引起数据库内部长时间的”library cache lock”或”row cache lock”的等待,这种情况主要是由于从Oracle11g开始的密码延迟验证和密码区分大小写等新特性引起的。这种现象在Oracle 10.2和11.1中体现的等待事件为:”row cache lock”,而在Oracle 11.2中体现的等待事件为:”library cache lock”。可以通过审计功能进行查询,参考:https://www.dbaup.com/zaioraclezhongruhechaxunmimashurucuowudedengluyonghu.html、https://www.dbaup.com/oracleyonghumimaxilie.html 。如果遇到这一类问题,可以通过Event 28401关闭这个特性,从而消除此类影响,以下命令将修改设置在参数文件中:
1ALTER SYSTEM SET EVENT = '28401 TRACE NAME CONTEXT FOREVER, LEVEL 1' SCOPE = SPFILE;核心热表统计信息变化:例如索引重建,分区表全局索引维护,任意DDL语句,任意DCL语句如grant语句,手动或自动收集统计信息,等等
过多的子游标,游标version count过高引起,单个 SQL 语句可以生成大量子游标。 在这种情况下,会在生成子游标的会话之间发生对相同资源(latches 或者 mutexes)的争用。
确认方法:AWR / Statspack 报告; 查看 "SQL ordered by Version Count" 部分. 如果有SQL语句的version数超过了500,则可能引发这个问题。或者,也可以查询
V$SQLAREA视图确认是否有version_count 大于500的SQL语句。查询 V$SQL_SHARED_CURSOR 视图检查SQL没有共享的原因。每次生成child cursor,需要在library cache object中装载新对象,就需要获取相关library cache object handle对象的x lock,latch层面还需要获取latch shared pool和latch library cache cache(在oracle 11g后latch library cache lock被library cache mutex代替)。如果不断产生大量子游标,则会导致在申请新cursor时出现library cache lock等待;当然一般子游标过多肯定也会伴随着latch shared pool和latch library cache或者library cache mutex x等待。
例如,根据主键进行更新或查询的SQL语句,其执行计划肯定只有1条,所以,完全可以使用绑定执行计划来减少version count。
审计被启用:审计由于需要申请 library cache lock 可能会导致产生冲突。尤其是在RAC环境中,library cache lock 是跨所有实例对整个数据库进行的,影响更大。 如果不必要,考虑禁用审计。请参考:https://www.dbaup.com/oracle-12czhongdetongyishenji.html和https://www.dbaup.com/oraclezhongdeshenjiyijidengludengchuddlchufaqijilubiaoshenjideng.html
RAC环境中的非共享SQL:RAC环境中的非共享SQL语句容易导致 Library cache lock 等待。 在单实例中,非共享SQL更容易发生 library cache 或者 shared pooll latch 的竞争,而在RAC环境中,竞争主要发生在 Library cache lock。 考虑修改SQL为绑定变量方式,或在会话级别配置
cursor_sharing=force大量使用行触发器:频繁的触发行触发器会导致比正常情况更多的 Library cache 活动,原因是需要检查是否正在读取发生修改的表。在触发器处理的过程中,可能会引用发生修改的表,即由触发器SQL修改的表。这会让数据库处于不一致的状态,导致ORA-4091的错误。为了检查这一点,每一次查找这些表都会获取 Library cache lock。是否发生取决于触发了多少行触发器,而不是定义了多少行触发器。 拥有一个触发 10000 次的触发器比拥有 100 个仅触发一次的触发器更有可能导致这个问题。
shared pool对象被频繁的age in和age out:shared pool不足、ASMM动态管理带来的SGA抖动、较大内存的PL/SQL和cursor object存储在shared pool中,每次重新装载进来都需要进行空间整理,此时会导致相关对象被age out
对象被编译:编译会对该对象的library cache object handle持有library cache lock x模式和library cache pin x模式,此时如果还有并发的相关SQL涉及到存储过程,执行存储过程需要持有library cache lock null和library cache pin s,则会出现library cache pin等待,如果有并发的编译或者DDL则可能出现library cache lock等待。
JDBC bug导致:在Oracle 11g 版本中可能出现由于JDBC bug导致sql绑定变量无法共享,过期游标过多的情况,此时如果发生大量并发业务,很有可能造成异常library cache lock等待事件,造成数据库突发性能问题。
SQL解析问题,p3参数多对应于“SQL AREA BUILD”,有如下几种情况:
a、存储过程解析错误或某频繁SQL语句解析错误,主要发生在SQL AREA BUILD上,在12.2之前可以通过配置
ALTER SYSTEM SET EVENTS '10035 trace name context forever, level 1';进行跟踪解析失败的SQL,从12.2开始对同一条SQL语句默认解析错误超过100(隐含参数_kks_parse_error_warning控制)的话就会在告警日志中显示,然后我们在告警日志中搜索"PARSE ERROR"、“parse errors” 就可以看到相关的SQL解析失败的语句,最后进行错误的SQL处理即可。 可以参考:https://dbaup.com/oraclejiexicuowudegenzongbanfa.html b、共享的SQL语句过期:如果共享池太小,共享游标将从library cache中移除,下次使用时需要重新加载。重新加载时需要硬解析,这会导致CPU资源消耗和锁的竞争。解决方法:增加共享池大小或使用ASMM自动调整或将频繁使用的较大的PL/SQL对象或者游标保持在共享池中(Pin)。可以使用 DBMS_SHARED_POOL.KEEP() procedure 将较大的且经常使用的 PL/SQL 对象和 SQL 语句游标保持在共享池中,并防止它们过期。 可以消除重复重新加载相同对象的需求并减少共享池的碎片。
c、跨越多个会话进行对象编译:一个或者多个会话在编译对象(通常时PL/SQL)的同时,其他会话为了执行或者编译同一个对象,pin住了它,那么这些会话将会以共享模式(执行)或者独占模式(编译或者更改对象)下等待library cache pin。解决方案: 避免在数据库繁忙的时间段或者多个会话同时编译对象,避免同时从多个会话或者业务高峰期编译有依赖关系的对象。
d、发生大量的硬解析,并发的SQL硬解析则会出现library cache lock竞争(对象在table的library cache object handle的library cache lock) 。可能有如下几点原因:
① 没有使用绑定变量,导致shared pool对象被频繁的age in和age out:类似的SQL语句,若只是条件的值不一样,即where条件使用的是常量(Literals),解决办法就是要么修改SQL为绑定变量方式要么在会话级别配置
cursor_sharing=force ② 由于shared pool不足导致SQL被挤出去。
③ Library cache object invalidations失效:当对对象(如表或视图)进行DDL 或收集统计信息时,依赖于它们的游标将失效。这里的DDL包括truncate表、索引重建、monitoring和nomonitoring索引,grant、alter操作等等, 这将导致游标在下一次执行时被硬解析,并会影响 CPU 和发生锁竞争。如果存在并发的DDL操作和DML,而DDL一直未完成,此时DDL会持有该对象的library cache object handle的X Lock,DML会请求该对象的ibrary cache object handle的S lock模式,此时DML就会被hang住。
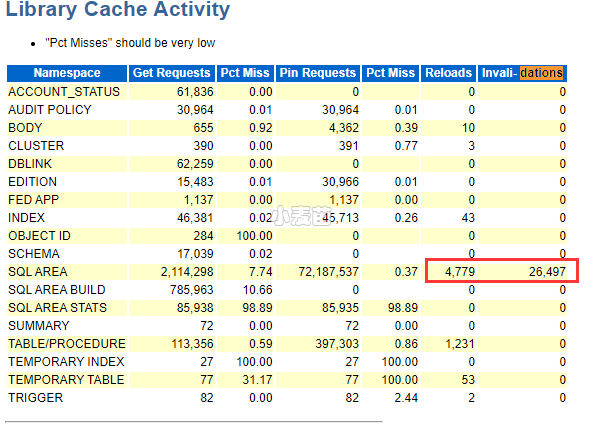
此时,AWR 或者 statspack 报告:
123- Library Cache statistics 部分显示 reloads 数很高并且 (每小时几千次) invalidations ( Invali- dations)也很高。- "% SQL with executions>1" 超过 60%, 表明SQL语句共享率较高。- 确认 Dictionary Statistics 部分中的“Modification Requests”的值是否为0,这意味着一些对象上有DDL在执行。
Library cache object 失效过多的解决方法:
- 不要在数据库繁忙的时间段执行DDL或DCL:DDL 或DCL语句使库缓存对象失效,并会涉及到许多依赖对象,比如游标。 对象失效后需要同时进行多次硬解析,对库缓存、共享池、字典缓存、CPU使用产生很大影响。 这里的DDL包括truncate表、索引重建、monitoring和nomonitoring索引,grant操作等等都会引起游标失效。
- 不要在数据库繁忙的时间段收集统计信息:收集统计信息(ANALYZE或者DBMS_STATS)会使库缓存对象失效,并会涉及到许多依赖对象,比如游标。 对象失效后需要同时进行多次硬解析,对库缓存、共享池、字典缓存、CPU使用产生很大影响。
- 不要在数据库繁忙的时间段执行 TRUNCATE 操作: 参考:Truncate - Causes Invalidations in the LIBRARY CACHE (Doc ID 123214.1)
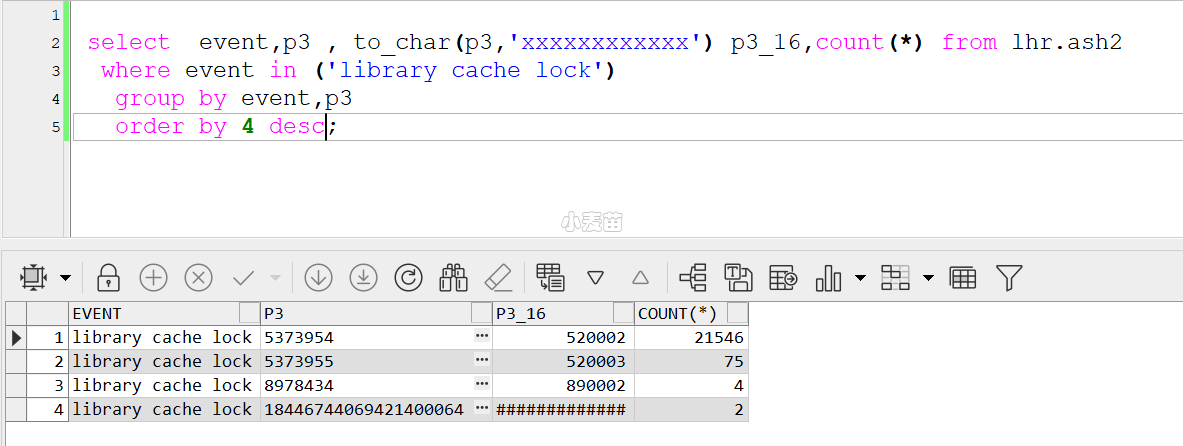
library cache lock的P3参数进行解析获取内部等待:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | -- 对于library cache lock等待事件,这里的p3值一般是5373954,16进制为00520002,前面的4位0052代表namespace,后面的4位0002代表mode,而0052的10进制为82,82对应的NAMESPACE为SQL AREA BUILD select event,p3 , to_char(p3,'xxxxxxxxxxxx') p3_16,count(*) from lhr.ash2 where event in ('library cache lock') group by event,p3 order by 4 desc; select to_char(5373954,'xxxxxxxxxxxx') p3_hex, to_number('0052','xxxx')from dual; SELECT distinct KGLHDNSP,KGLHDNSD FROM X$KGLOB D WHERE KGLHDNSD like '%SQL AREA%' ORDER BY KGLHDNSP; select distinct indx,kglstdsc from x$kglst d where kglstdsc like '%SQL AREA%' ORDER BY indx; 0 SQL AREA 75 SQL AREA STATS 82 SQL AREA BUILD -- 通常是由于大量解析导致,或SQL AREA上的问题,如SQL解析失败 |
或从ASH的15分钟报告也可以查到等待事件的参数值:
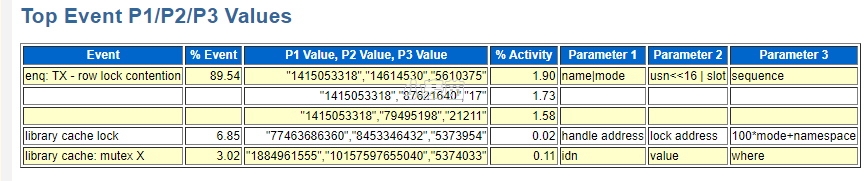
此外,也可以通过Systemstate dump的报告获取到,“handle address=0x743bb3e98, lock address=0x743baf088, 100*mode+namespace=0x520002 ===========> namespace is 0x52 (dec:82), sql area build”
关于library cache lock相关等待可参考
'library cache lock' Waits: Causes and Solutions (Doc ID 1952395.1)
'library cache lock' 等待事件: 原因和解决方案 (Doc ID 2896611.1)

2、library cache: mutex X
库缓存(library cache )是用来保存解析过的 cursor 相关的内存结构,在 library cache 中有许多内存结构需要 library cache: mutex X 的保护。
library cache: mutex X 表示会话在获取库缓存(Library Cache)中特定资源的互斥锁(Mutex)时遇到了等待。库缓存是Oracle数据库中存储已解析过的SQL语句、执行计划和PL/SQL单元等共享资源的地方,互斥锁用于确保并发访问这些共享资源时的一致性。当多个会话试图同时访问或修改库缓存中的相同对象(例如,SQL语句的执行计划或PL/SQL包体)时,只有一个会话能够获得互斥锁并执行操作,其他会话则会等待互斥锁的释放,这时就会出现 library cache: mutex X 的等待事件。
在以前的 Oracle 版本中,获取 library cache Mutex 与获取 library cache latches 的目的相似。在 10g 中,为 library cache 中的特定操作引入了 Mutex。从 11g 开始,Mutex 取代了 library cache latches。只要某个会话以独占模式持有 library cache mutex 并且其他会话需要等待释放 Mutex,就会出现此等待事件。
12c 以后该等待又被细分为如下:
● library cache: mutex X – 用于保护 handle。
● library cache: bucket mutex X – 用于保护 library cache 中的 hash buckets。
● library cache: dependency mutex X – 用于保护依赖。
等待 library cache: mutex X 与之前版本的 latch:library cache 等待相同。library cache: mutex X 可以被很多因素引起,例如:(包括应用问题,执行计划不能共享导致的高版本的游标等),本质上都是某个进程持有 library cache: mutex X 太长时间,导致后续的进程必须等待该资源。如果在 library cache 的 latch 或者 mutex 上有等待,说明解析时有很大的压力,解析 SQL 的时间变长(由于 library cache 的 latch 或者 mutex 的等待)会使整个数据库的性能下降。
由于引起 library cache: mutex X 的原因多种多样,因此找到引起问题的根本原因很重要,才能使用正确的解决方案。
3个参数的值:
P1 = "idn" = 唯一的Mutex标识符
P2 = "value" = 持有Mutex的会话ID
P3 = "where" = 等待 Mutex 的代码中的位置(内部标识符)
系统范围等待:
在系统范围级别,有两个视图可用于帮助诊断此等待:
GV$MUTEX_SLEEP(对于非 RAC 为 V$MUTEX_SLEEPS)和 GV$MUTEX_SLEEP_HISTORY(对于非 RAC 为 V$MUTEX_SLEEP_HISTORY)
在实例启动后,这些视图在实例范围内跟踪 Mutex 的使用情况。由于这些视图显示了自启动以来的总数,在出现问题时,您可以获取短时间间隔内值的差异,因此这些数据是非常有意义的。了解这些信息最简单的方法是查看 AWR 或 statspack 报告的“Mutex Sleep Summary”部分。
产生library cache: mutex X的常见原因:
● 大量的硬解析:过于频繁的硬解析,会导致该等待。
● 高版本的游标:当发生 High version count 时,大量的子游标需要检索,从而会引起该等待。由于SQL的子游标过多引起SQL解析时遍历library cache object handle链表需要很长时间,造成了library cache: mutex x等待。
● 游标失效:游标失效是指,保存在 library cache 中的游标由于某些改变导致不可用,而从 library cache 中删除。例如:游标相关对象的统计信息收集;游标关联表,视图等对象的修改等。发生游标失效会导致接下来的进程需要重新载入该游标。当游标失效过多时,会导致 'library cache: mutex X' 等待。在11g里,由于bug 16400122,若某个SQL执行很频繁,且存在SQL基线,则会导致每6.5天高频率SQL游标被invalidate的问题。
● 游标重载:游标重新载入是指本来已经存在于 library cache 中,但是当再次查找时已经被移出 library cache(例如:由于内存压力),这时就需要重新解析并且载入该游标。游标重新载入操作不是一件好事,它表明您正在做一件本来不需要做的事情,如果您设置的 library cache 大小适当,是可以避免游标重新载入的。游标重新载入的时候是不可以被进程使用的,这种情况会导致 library cache: mutex X 等待。
● cursor_sharing=similar和session_cached_cursors配置不当。对于 11G,确认 cursor_sharing 不是 similar,因为该值已经不建议使用,并且会引起 mutex X 等待。可以参考:Document 1169017.1 ANNOUNCEMENT: Deprecating the cursor_sharing = ‘SIMILAR’ setting
● 如果数据库从 10G 升级到 11G 后,遇到 mutex 的问题,请考虑升级到 11.2.0.2.2 以上的 PSU 来修复未发布的 Bug12431716,很多关于 mutex 的修复已经包含在该 Bug 中。诊断 11G 之后的 library cache: mutex X 问题诊断,参照如下文档:Document 2051456.1 Troubleshooting Databases Hang Due to Heavy Contention for 'library cache: mutex X' Waits (Oracle 11.2 and Later)
● shared pool配置过小
● 某些已知的 Bug,例如:
○ “SELECT ANY TABLE”导致的,Bug 32356628 - Significant increase in library cache: mutex x wait time after upgrading database to 19c (Doc ID 32356628.8)
○ Bug 32219835 - Performance Degraded with Library Cache: Mutex x with Database Vault enabled 19c (Doc ID 32219835.8)
○ Bug 8431767 - High "library cache: mutex X" when using Application Context (Doc ID 8431767.8)
○ Bug 16400122 - Spikes in library cache mutex contention for SQL using SQL Plan Baseline (Doc ID 16400122.8)
3、enq: TX - row lock contention
enq: TX - row lock contention表明在并发事务处理过程中,不同会话因为试图修改(INSERT、UPDATE或DELETE)同一行数据而产生了行级锁争用。在Oracle中,事务(Transaction,TX)为了保证数据一致性,会在修改数据时对相应的行施加行级锁(Row Lock)。当一个会话已经获得了某一行的排他锁(Exclusive Lock),而其他会话也需要对该行进行修改操作时,它们将会进入等待状态,直到持有该行锁的会话提交(COMMIT)或回滚(ROLLBACK)事务,释放该行锁。
产生enq: TX - row lock contention的常见原因:
● 真正的业务逻辑上的行锁冲突,如一条记录被多个人同时修改。这种锁对应的请求模式是6。
● 唯一键冲突,如主键字段相同的多条记录同时插入。这种锁对应的请求模式是4。这也是应用逻辑问题。
● BITMAP索引的更新冲突,就是多个会话同时更新BITMAP索引的同一个数据块。此时会话请求锁的对应的请求模式是4。
行锁冲突案例可以参考:https://www.dbaup.com/oracledengdaishijianduiliedengdaizhitx-row-lock-contention.html
4、cursor: mutex S和cursor: mutex X
cursor: mutex S 和 cursor: mutex X 是Oracle数据库中两种不同类型的等待事件,它们都与游标相关的互斥锁(mutex)有关,主要区别在于锁的粒度和目的:
cursor: mutex S (Shared Mutex):
•目的:cursor: mutex S 等待事件发生在会话试图以共享模式获取游标相关的互斥锁时。这种模式的锁主要用于读取操作,允许多个会话同时以只读方式访问相同的游标资源,而不改变其状态。
•粒度:通常与保护游标状态或元数据(如游标统计信息)的共享访问有关,确保在不修改游标的情况下,多个会话可以并发地执行相同的SQL语句。
•并发性:较高,因为多个会话可以同时持有共享锁,只要没有会话要求排他锁进行写入操作。
cursor: mutex X (Exclusive Mutex):
cursor: mutex X 表示会话在获取游标相关的互斥锁(Mutex)时遇到了等待。互斥锁是用来保护共享资源,确保在同一时间只有一个会话可以访问或修改资源。
在并发环境下,多个会话可能同时尝试访问或修改同一个游标对象,为了避免数据不一致性和并发问题,Oracle使用互斥锁来控制对游标的访问。当多个会话需要获取同一流程或游标的互斥锁时,除第一个成功获取锁的会话外,其他会话会陷入等待状态,表现为等待事件 cursor: mutex X。
•目的:cursor: mutex X 等待事件发生在会话请求对游标资源的排他访问权时。这种模式的锁用于修改游标的状态或执行涉及游标内容的更新操作,如硬解析、执行计划变更、游标重用策略调整等。
•粒度:通常与需要独占控制的游标内部结构或执行计划相关,确保在修改期间不会与其他会话的读取或写入操作冲突。
•并发性:较低,因为一旦一个会话持有排他锁,其他所有会话(无论是请求共享还是排他锁)必须等待该锁被释放才能继续操作。
总结差异:
•访问模式:cursor: mutex S 表示共享访问,适用于读取操作,允许多个会话并发访问;cursor: mutex X 表示排他访问,适用于写入或修改操作,同一时刻仅允许一个会话持有。
•并发影响:cursor: mutex S 有助于提高并发性,因为它允许并发读取;而 cursor: mutex X 可能导致阻塞,因为它阻止了其他会话在同一时间内访问相同游标资源。
•应用场景:cursor: mutex S 通常与游标共享、执行计划共享等读取操作相关;cursor: mutex X 与硬解析、执行计划变更、游标状态更新等写入或修改操作相关。
在数据库性能调优中,高频率的 cursor: mutex S 或 cursor: mutex X 等待事件可能表明存在游标管理或SQL执行计划相关的问题,如过度的硬解析、游标版本过多、并发争用严重等。解决这些问题通常需要分析具体的应用逻辑、SQL语句、会话行为以及数据库配置,采取诸如减少硬解析、使用绑定变量、优化SQL、调整共享池参数等措施来降低锁竞争和改善系统性能。
产生cursor: mutex X和cursor: mutex S的常见原因:
•并发会话在解析、执行或关闭相同SQL语句的游标时。
•应用程序中存在大量的并发打开和关闭游标操作。
•PL/SQL块内部对游标进行了并发访问。
•LANGUAGE_MISMATCH原因导致:
a、Database Hang With 'cursor: mutex X' Contention Due To High Version Count Under LANGUAGE_MISMATCH (Doc ID 2542447.1)、数据库挂起 由于 LANGUAGE_MISMATCH 的 High Version Count 导致 'cursor:mutex X' 争用 (Doc ID 2577528.1)
• 其它已知bug:
a、cdb和pdb的字符集不一致导致bug25054064,Bug 25054064 - Cursor Has High Version Count In PDB Whose Character Set Is Different From CDB$ROOT (Doc ID 25054064.8),也会导致LANGUAGE_MISMATCH:
1 | select * from v$nls_parameters where parameter like 'NLS_CHARACTERSET'; |
5、cursor: pin S wait on X和cursor: pin S
cursor: pin S wait on X
cursor: pin S wait on X会话等待此事件是在它尝试获取共享模式的 Mutex 锁时,其他会话在相同游标对象上以独占方式持有 Mutex 锁。通常,等待“Cursor: pin S wait on X”是症状而非原因。其中可能需要进行底层的优化或者是已知问题。
游标等待与某种形式的解析相关联。 当会话尝试在共享模式下获取 mutex pin 资源,但另一个会话在同一个游标对象上以独占方式持有该 mutex pin 资源时,就可能会发生此等待事件。通常,等待“cursor: pin S wait on X”等待是一种症状,而不是原因。 可能存在潜在的调优要求或是遭遇了已知问题。
常见原因:
首先,要保证 shared pool 的大小设置正确。
一般来说,如果 shared pool 大小不足或者承受负载的能力不足,就可能表现为“cursor: pin S wait on X”等待。如果使用了自动内存管理模式,那么这通常不是问题,详见:
Document 443746.1 Automatic Memory Management (AMM) on 11g
频繁硬解析
如果硬解析的频率很高的话,在 mutex pin 上就会发生竞争。子游标版本数过高
当子游标版本数过高时,需要检查一长串版本,这可能会导致对该事件的争用。已知的 BUG
解析错误,详见以下文档:
Document 1353015.1 How to Identify Hard Parse Failures
How to Determine the Blocking Session for Event: 'cursor: pin S wait on X' (Doc ID 786507.1)
cursor: pin S
会话在申请共享模式下特定游标上的特定 Mutex 时,虽然没有并行的排他持有者,但无法立即获取 Mutex,这时会等待“cursor: pin S”。这看上去有些不合理,因为用户可能会不理解为什么在没有排他模式持有者的情况下会存在这种等待。出现这种等待的原因是,为了在共享模式下获取 Mutex(或释放Mutex),会话必须增加(或减少)Mutex 引用计数,这需要对 Mutex 结构本身进行独占原子更新。如果有并行会话在尝试对 Mutex 进行这样的更新,则一次只有一个会话能够实际增加(或减少)引用计数。如果由于其他并行请求使得某个会话无法立即进行这种原子更新,则会出现等待“cursor: pin S”。
在 RAC 环境中,Mutex 只作用于本地实例。
参数:
P1 = idn
P2 = value
P3 = where(10.2 中为 where|sleeps)
idn 是 Mutex 标识符值,与正在等待以获取 Mutex 的 SQL语句的 HASH_VALUE 相匹配。可以用以下格式的查询找到使用对应 IDN 的 SQL 语句:
1 2 | SELECT sql_id, sql_text, version_count FROM V$SQLAREA where HASH_VALUE=&IDN; |
如果游标显示的 SQL_TEXT 格式为“table_x_x_x_x”,则这是特殊的内部游标,有关将此类游标映射到对象的详细信息,请参阅 Document 1298471.1。
P1RAW 是采用十六进制值的相同值,可用于在跟踪文件中搜索与该 hash(散列)值匹配的 SQL。
value
Mutex value (includes details of holder)
本人提供Oracle(OCP、OCM)、MySQL(OCP)、PostgreSQL(PGCA、PGCE、PGCM)等数据库的培训和考证业务,私聊QQ646634621或微信dbaup66,谢谢!
