合 GreenPlum性能优化系列
- 架构设计
- 服务器配置(硬件选型)
- CPU主频与核数
- CPU开启超线程
- 参数调优
- 数据库参数
- gp_vmem_protect_limit
- shared_buffers
- max_connections
- max_prepared_transactions
- work_mem
- temp_buffers
- maintenance_work_mem
- max_statement_mem
- statement_mem
- effective_cache_size
- gp_resqueue_priority_cpucores_per_segment
- gp_enable_global_deadlock_detector
- log_statement
- gp_workfile_limit_files_per_query
- gp_autostats_mode、gp_autostats_on_change_threshold
- optimizer
- max_files_per_process
- gp_fts_probe_threadcount
- client_encoding
- client_min_messages
- cpu_index_tuple_cost
- gp_resqueue_memory_policy
- runaway_detector_activation_percent
- gp_vmem_protect_segworker_cache_limit
- gp_vmem_idle_resource_timeout
- gp_workfile_compression
- gp_resource_group_memory_limit
- gp_hashjoin_tuples_per_bucket
- gp_interconnect_setup_timeout
- gp_vmem_protect_segworker_cache_limit
- gp_max_partition_level
- 内核参数调整
- swap
- 透明大页
- vm.overcommit_memory和vm.overcommit_ratio
- 共享内存设置
- 网络参数调整
- 内联网络--万兆网络
- 磁盘和I/O参数
- 磁盘IO性能
- RAID卡性能
- 磁盘配置
- 磁盘读写(RAID)
- 数据盘的磁盘预读配置为16384
- 调度器
- OS文件和进程的最大数量
- 内核转储
- 文件系统
- GreenPlum使用tcp还是udp好
- 每台主机上的Segment实例数量
- 经验之谈
- 数据模型设计的重要性
- 表存储
- Greenplum参数优化工具
- SQL优化
- 一些SQL优化内容
- 参考
架构设计
集群规划中影响性能的因素
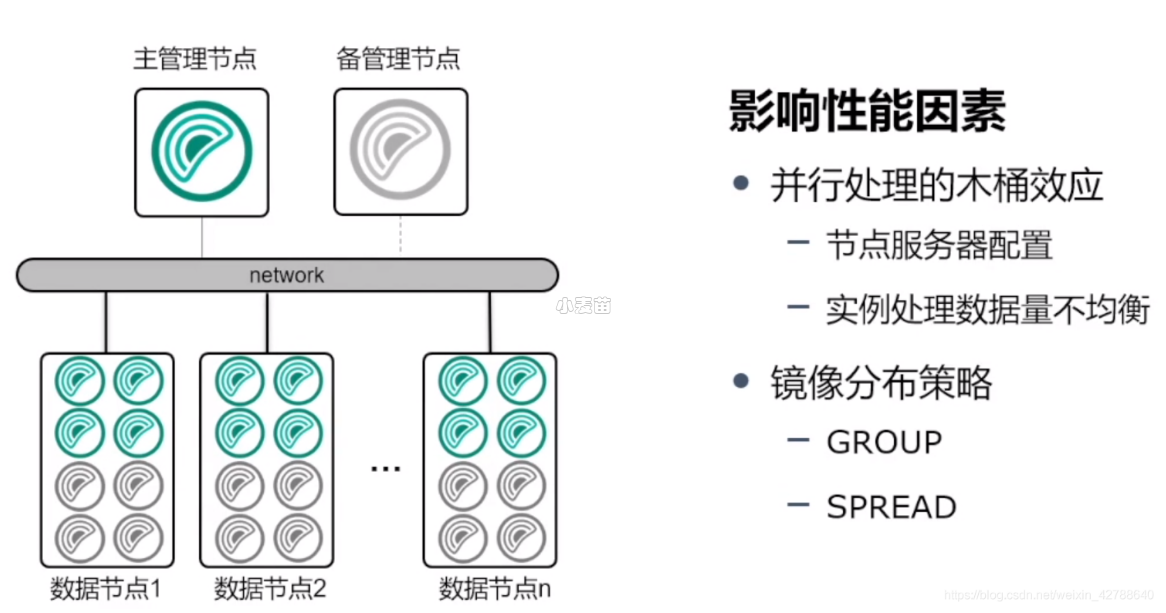
1、并行处理时,用户查询的处理速度取决于集群里最慢的数据库实例的完成时间。所以,当各节点服务器硬件配置不一样时,配置高的机器处理速度快,配置低的机器处理慢,此时短板就是配置较差的机器,影响整体性能。如果想再硬件上提升数据库性能,就需要均衡各个节点的服务器配置才有用。
2、实例处理数据量不均衡(表倾斜)。这可能是建表时分布键选择不正确,导致数据倾斜到某些节点,导致该实例上的节点要处理的数量高于其他节点,导致处理时间相对于其他节点变慢,最终导致max_statement_mem整个查询速度变慢。这种情况可以通过表的优化来避免。
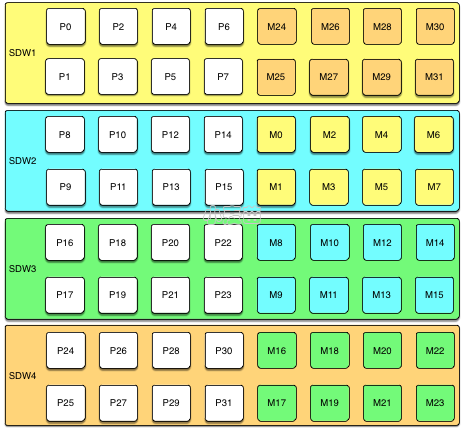
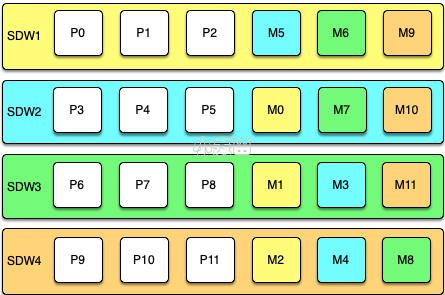
3、镜像的分部策略也可能影响数据库性能。这种情况是在数据库中有主实例down了之后才会体现出来。在下面的架构中,每个节点有8个主实例和8个备实例,采用GROUP策略(默认),将8个备实例全部放在另一台服务器上,如果一台服务器down了,另一台服务器上的镜像就会启动工作,这样的话该节点就相当于16个数据库实例在运行。相比其他运行8个数据库实例的节点,性能下降一半。如果是采用SPREAD策略,则3个备实例是分别处于其他3台服务器上,这种策略相对于GROUP策略的性能下降没有那么严重,但是发生主备同时down的几率更大,更容易导致数据库不可用(只要有1对主备实例都down了就会不可用),相对没有那么稳定,这就需要根据实例需要选择某一个策略。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 | [gpadmin@mdw ~]$ gpstate -m 20231017:13:53:00:013224 gpstate:mdw:gpadmin-[INFO]:-Starting gpstate with args: -m 20231017:13:53:00:013224 gpstate:mdw:gpadmin-[INFO]:-local Greenplum Version: 'postgres (Greenplum Database) 6.25.3 build commit:367edc6b4dfd909fe38fc288ade9e294d74e3f9a Open Source' 20231017:13:53:00:013224 gpstate:mdw:gpadmin-[INFO]:-master Greenplum Version: 'PostgreSQL 9.4.26 (Greenplum Database 6.25.3 build commit:367edc6b4dfd909fe38fc288ade9e294d74e3f9a Open Source) on x86_64-unknown-linux-gnu, compiled by gcc (GCC) 6.4.0, 64-bit compiled on Oct 4 2023 23:27:58' 20231017:13:53:00:013224 gpstate:mdw:gpadmin-[INFO]:-Obtaining Segment details from master... 20231017:13:53:00:013224 gpstate:mdw:gpadmin-[INFO]:-------------------------------------------------------------- 20231017:13:53:00:013224 gpstate:mdw:gpadmin-[INFO]:--Current GPDB mirror list and status 20231017:13:53:00:013224 gpstate:mdw:gpadmin-[INFO]:--Type = Group 20231017:13:53:00:013224 gpstate:mdw:gpadmin-[INFO]:-------------------------------------------------------------- 20231017:13:53:00:013224 gpstate:mdw:gpadmin-[INFO]:- Mirror Datadir Port Status Data Status 20231017:13:53:00:013224 gpstate:mdw:gpadmin-[INFO]:- sdw2 /opt/greenplum/data/mirror/gpseg0 7000 Passive Synchronized 20231017:13:53:00:013224 gpstate:mdw:gpadmin-[INFO]:- sdw2 /opt/greenplum/data/mirror/gpseg1 7001 Passive Synchronized 20231017:13:53:00:013224 gpstate:mdw:gpadmin-[INFO]:- sdw2 /opt/greenplum/data/mirror/gpseg2 7002 Passive Synchronized 20231017:13:53:00:013224 gpstate:mdw:gpadmin-[INFO]:- sdw2 /opt/greenplum/data/mirror/gpseg3 7003 Passive Synchronized 20231017:13:53:00:013224 gpstate:mdw:gpadmin-[INFO]:- sdw3 /opt/greenplum/data/mirror/gpseg4 7000 Passive Synchronized 20231017:13:53:00:013224 gpstate:mdw:gpadmin-[INFO]:- sdw3 /opt/greenplum/data/mirror/gpseg5 7001 Passive Synchronized 20231017:13:53:00:013224 gpstate:mdw:gpadmin-[INFO]:- sdw3 /opt/greenplum/data/mirror/gpseg6 7002 Passive Synchronized 20231017:13:53:00:013224 gpstate:mdw:gpadmin-[INFO]:- sdw3 /opt/greenplum/data/mirror/gpseg7 7003 Passive Synchronized 20231017:13:53:00:013224 gpstate:mdw:gpadmin-[INFO]:- sdw4 /opt/greenplum/data/mirror/gpseg8 7000 Passive Synchronized 20231017:13:53:00:013224 gpstate:mdw:gpadmin-[INFO]:- sdw4 /opt/greenplum/data/mirror/gpseg9 7001 Passive Synchronized 20231017:13:53:00:013224 gpstate:mdw:gpadmin-[INFO]:- sdw4 /opt/greenplum/data/mirror/gpseg10 7002 Passive Synchronized 20231017:13:53:00:013224 gpstate:mdw:gpadmin-[INFO]:- sdw4 /opt/greenplum/data/mirror/gpseg11 7003 Passive Synchronized 20231017:13:53:00:013224 gpstate:mdw:gpadmin-[INFO]:- sdw1 /opt/greenplum/data/mirror/gpseg12 7000 Passive Synchronized 20231017:13:53:00:013224 gpstate:mdw:gpadmin-[INFO]:- sdw1 /opt/greenplum/data/mirror/gpseg13 7001 Passive Synchronized 20231017:13:53:00:013224 gpstate:mdw:gpadmin-[INFO]:- sdw1 /opt/greenplum/data/mirror/gpseg14 7002 Passive Synchronized 20231017:13:53:00:013224 gpstate:mdw:gpadmin-[INFO]:- sdw1 /opt/greenplum/data/mirror/gpseg15 7003 Passive Synchronized 20231017:13:53:00:013224 gpstate:mdw:gpadmin-[INFO]:-------------------------------------------------------------- [gpadmin@mdw ~]$ [gpadmin@mdw ~]$ gpstate -c 20231017:14:00:06:013843 gpstate:mdw:gpadmin-[INFO]:-Starting gpstate with args: -c 20231017:14:00:06:013843 gpstate:mdw:gpadmin-[INFO]:-local Greenplum Version: 'postgres (Greenplum Database) 6.25.3 build commit:367edc6b4dfd909fe38fc288ade9e294d74e3f9a Open Source' 20231017:14:00:06:013843 gpstate:mdw:gpadmin-[INFO]:-master Greenplum Version: 'PostgreSQL 9.4.26 (Greenplum Database 6.25.3 build commit:367edc6b4dfd909fe38fc288ade9e294d74e3f9a Open Source) on x86_64-unknown-linux-gnu, compiled by gcc (GCC) 6.4.0, 64-bit compiled on Oct 4 2023 23:27:58' 20231017:14:00:06:013843 gpstate:mdw:gpadmin-[INFO]:-Obtaining Segment details from master... 20231017:14:00:06:013843 gpstate:mdw:gpadmin-[INFO]:-------------------------------------------------------------- 20231017:14:00:06:013843 gpstate:mdw:gpadmin-[INFO]:--Current GPDB mirror list and status 20231017:14:00:06:013843 gpstate:mdw:gpadmin-[INFO]:--Type = Group 20231017:14:00:06:013843 gpstate:mdw:gpadmin-[INFO]:-------------------------------------------------------------- 20231017:14:00:06:013843 gpstate:mdw:gpadmin-[INFO]:- Status Data State Primary Datadir Port Mirror Datadir Port 20231017:14:00:06:013843 gpstate:mdw:gpadmin-[INFO]:- Primary Active, Mirror Available Synchronized sdw1 /opt/greenplum/data/primary/gpseg0 6000 sdw2 /opt/greenplum/data/mirror/gpseg0 7000 20231017:14:00:06:013843 gpstate:mdw:gpadmin-[INFO]:- Primary Active, Mirror Available Synchronized sdw1 /opt/greenplum/data/primary/gpseg1 6001 sdw2 /opt/greenplum/data/mirror/gpseg1 7001 20231017:14:00:06:013843 gpstate:mdw:gpadmin-[INFO]:- Primary Active, Mirror Available Synchronized sdw1 /opt/greenplum/data/primary/gpseg2 6002 sdw2 /opt/greenplum/data/mirror/gpseg2 7002 20231017:14:00:06:013843 gpstate:mdw:gpadmin-[INFO]:- Primary Active, Mirror Available Synchronized sdw1 /opt/greenplum/data/primary/gpseg3 6003 sdw2 /opt/greenplum/data/mirror/gpseg3 7003 20231017:14:00:06:013843 gpstate:mdw:gpadmin-[INFO]:- Primary Active, Mirror Available Synchronized sdw2 /opt/greenplum/data/primary/gpseg4 6000 sdw3 /opt/greenplum/data/mirror/gpseg4 7000 20231017:14:00:06:013843 gpstate:mdw:gpadmin-[INFO]:- Primary Active, Mirror Available Synchronized sdw2 /opt/greenplum/data/primary/gpseg5 6001 sdw3 /opt/greenplum/data/mirror/gpseg5 7001 20231017:14:00:06:013843 gpstate:mdw:gpadmin-[INFO]:- Primary Active, Mirror Available Synchronized sdw2 /opt/greenplum/data/primary/gpseg6 6002 sdw3 /opt/greenplum/data/mirror/gpseg6 7002 20231017:14:00:06:013843 gpstate:mdw:gpadmin-[INFO]:- Primary Active, Mirror Available Synchronized sdw2 /opt/greenplum/data/primary/gpseg7 6003 sdw3 /opt/greenplum/data/mirror/gpseg7 7003 20231017:14:00:06:013843 gpstate:mdw:gpadmin-[INFO]:- Primary Active, Mirror Available Synchronized sdw3 /opt/greenplum/data/primary/gpseg8 6000 sdw4 /opt/greenplum/data/mirror/gpseg8 7000 20231017:14:00:06:013843 gpstate:mdw:gpadmin-[INFO]:- Primary Active, Mirror Available Synchronized sdw3 /opt/greenplum/data/primary/gpseg9 6001 sdw4 /opt/greenplum/data/mirror/gpseg9 7001 20231017:14:00:06:013843 gpstate:mdw:gpadmin-[INFO]:- Primary Active, Mirror Available Synchronized sdw3 /opt/greenplum/data/primary/gpseg10 6002 sdw4 /opt/greenplum/data/mirror/gpseg10 7002 20231017:14:00:06:013843 gpstate:mdw:gpadmin-[INFO]:- Primary Active, Mirror Available Synchronized sdw3 /opt/greenplum/data/primary/gpseg11 6003 sdw4 /opt/greenplum/data/mirror/gpseg11 7003 20231017:14:00:06:013843 gpstate:mdw:gpadmin-[INFO]:- Primary Active, Mirror Available Synchronized sdw4 /opt/greenplum/data/primary/gpseg12 6000 sdw1 /opt/greenplum/data/mirror/gpseg12 7000 20231017:14:00:06:013843 gpstate:mdw:gpadmin-[INFO]:- Primary Active, Mirror Available Synchronized sdw4 /opt/greenplum/data/primary/gpseg13 6001 sdw1 /opt/greenplum/data/mirror/gpseg13 7001 20231017:14:00:06:013843 gpstate:mdw:gpadmin-[INFO]:- Primary Active, Mirror Available Synchronized sdw4 /opt/greenplum/data/primary/gpseg14 6002 sdw1 /opt/greenplum/data/mirror/gpseg14 7002 20231017:14:00:06:013843 gpstate:mdw:gpadmin-[INFO]:- Primary Active, Mirror Available Synchronized sdw4 /opt/greenplum/data/primary/gpseg15 6003 sdw1 /opt/greenplum/data/mirror/gpseg15 7003 20231017:14:00:06:013843 gpstate:mdw:gpadmin-[INFO]:-------------------------------------------------------------- [gpadmin@mdw ~]$ |
GROUP策略:
SPREAD策略:
服务器配置(硬件选型)
在硬件选型上,我们讲究达到平衡。是要在性能、容量、成本等多个方面综合考虑,取得平衡。不能一味追求容量而忽略了整体性能,忽略了日后维护和扩容的成本;也不能一味追求性能而忽略了成本,而让采购部门望而却步。
CPU主频与核数
就目前来说,一个SQL语句的执行性能,取决于单核的计算能力和有多少个Primary段参与计算。通常对于一个Primary来说,在执行一个任务时,只能利用一个CPU核的计算能力。
现在主流的两路X86服务器,CPU一般都配置64核甚至更高核数。相同核数情况下追求高主频需要很高的成本,性价比很低,基本没有什么选择的空间。所以,要提升集群的整体计算能力,核数是个非常重要的因素。如果有可能,尽量增加CPU核数,配置96核甚至128核以上的CPU,将会带来更好的计算能力。
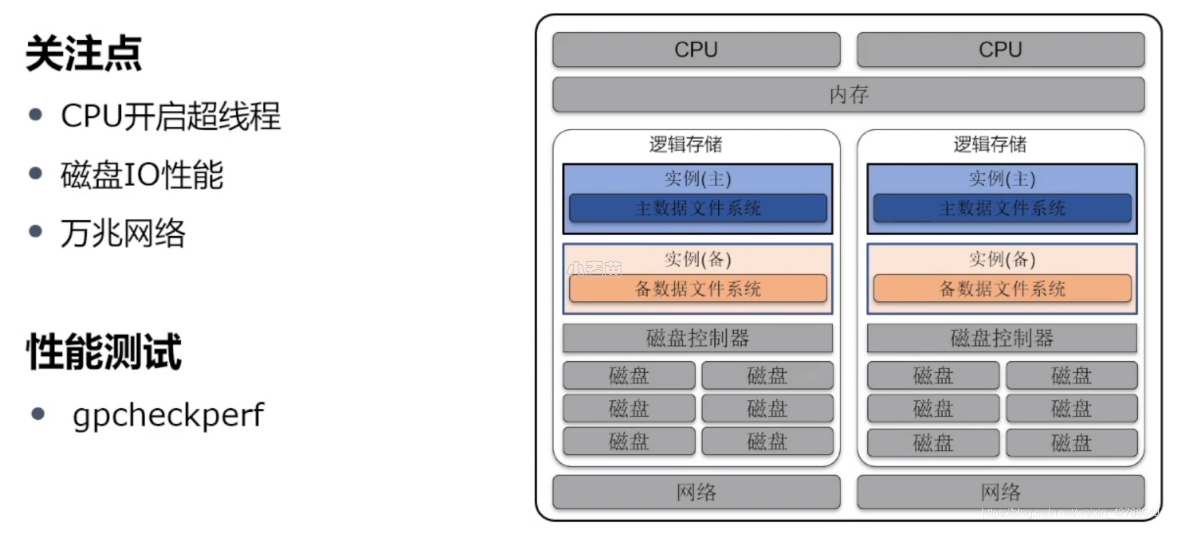
CPU开启超线程
CPU内核只能处理一项任务,但目前CPU处理速度很快,通常使用率达不到100%。在GP数据库,可以通过开启CPU超线程,提高GP数据库的并行处理能力。
lscpu | grep core结果为2表示开启超线程。
详细请参考:https://www.dbaup.com/wulicpuluojicpucpuhexincpuxianchengdeng.html
参数调优
数据库参数
参考:https://www.bookstack.cn/read/greenplum-admin_guide-6.0-zh/27985e397e5e819a.md
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 | -- 以下参数需要重启(注意:standby master的值需要单独修改postgresql.conf文件) -- gp_vmem_protect_limit和gp_resqueue_priority_cpucores_per_segment需要计算 -- max_prepared_transactions需要和max_connections的master配置一样 gpconfig -c gp_vmem_protect_limit -v 16658 -m 102400 gpconfig -c shared_buffers -v 1G -m 8G gpconfig -c max_connections -v 3000 -m 1000 gpconfig -c max_prepared_transactions -v 1000 gpconfig -c track_activity_query_size -v 102400 -m 102400 gpconfig -c gp_resqueue_priority_cpucores_per_segment -v 4 -m 32 gpconfig -c gp_enable_global_deadlock_detector -v on gpstop -M fast -ra gpconfig -s gp_vmem_protect_limit gpconfig -s shared_buffers gpconfig -s max_connections gpconfig -s max_prepared_transactions gpconfig -s track_activity_query_size gpconfig -s gp_resqueue_priority_cpucores_per_segment gpconfig -s gp_enable_global_deadlock_detector -- 以下参数不需要重启(注意:standby master的值需要单独修改postgresql.conf文件) gpconfig -c work_mem -v 2GB gpconfig -c temp_buffers -v 4GB gpconfig -c maintenance_work_mem -v 2GB gpconfig -c effective_cache_size -v 60GB -m 100GB # gpconfig -c statement_mem -v 2GB gpconfig -c max_statement_mem -v 6GB gpconfig -c log_statement -v ddl --masteronly gpconfig -c gp_workfile_compression -v on gpstop -u gpconfig -s work_mem gpconfig -s temp_buffers gpconfig -s maintenance_work_mem gpconfig -s effective_cache_size gpconfig -s statement_mem gpconfig -s max_statement_mem gpconfig -s log_statement gpconfig -s gp_workfile_compression -- 其它 gpconfig -s wal_buffers gpconfig -s optimizer gpconfig -s resource_scheduler gpconfig -s gp_resqueue_priority gpconfig -s gp_interconnect_type gpconfig -s gp_interconnect_tcp_listener_backlog gpconfig -s max_worker_processes gpconfig -s wal_writer_delay gpconfig -s commit_siblings gpconfig -s checkpoint_completion_target gpconfig -s bgwriter_delay gpconfig -s bgwriter_lru_maxpages gpconfig -s fsync |
gp_vmem_protect_limit
Note: 仅当资源管理设置为资源队列时,gp_vmem_protect_limit服务器配置参数才会生效。
控制了每个segment实例为所有运行的查询语句可以分配的内存总量(以MB为单位)。如果查询导致超出此限制,则不会分配内存,查询将失败。
计算gp_vmem_protect_limit 的值:https://greenplum.org/calc/ “Primary Segments Per Server”为所有的实例个数,包括p和m。该参数限制每个Instance上所有语句可以使⽤的内存总量的上限值(以MB为单位)。 如果查询导致超出此限制,则不会分配内存,查询将失败,配置合理可以有效避免OOM的发生。
1 2 3 4 5 6 7 8 9 | #查看现有配置值 gpconfig -s gp_vmem_protect_limit Values on all segments are consistent GUC : gp_vmem_protect_limit Master value: 8192 Segment value: 8192 ## 配置(注意master和segment区分) gpconfig -c gp_vmem_protect_limit -v 16658 -m 102400 |
https://www.bookstack.cn/read/greenplum-admin_guide-6.0-zh/27985e397e5e819a.md#6vehwh
使用gp_vmem_protect_limit设置实例能够为在每个segment数据库中完成的所有 工作分配的最大内存。不要把这个值设置得高于系统上的物理RAM。如果gp_vmem_protect_limit太高,有可能耗尽系统上的内存并且正常的操作可能会失败,导致segment故障。如果gp_vmem_protect_limit被设置为一个安全的较低值,系统上真正的内存耗尽就能避免。查询可能会因为达到限制而失败,但是系统崩溃和 segment故障可以避免,这也是我们想要的行为。
有关计算gp_vmem_protect_limit安全值的步骤,请见 资源队列的segment内存配置。
设置活动segment实例的所有postgres进程可以使用的内存量(以MB为单位)。 如果查询导致超出此限制,则不会分配内存,查询将失败。 请注意,这是一个本地参数,必须为系统中的每个segment(primary和mirror)设置。 设置参数值时,仅指定数值。 例如,要指定4096MB,请使用值4096.不要将单位MB添加到该值。
为了防止内存过度分配,这些计算可以估计安全的gp_vmem_protect_limit值。
首先计算值gp_vmem。 这是主机上可用的Greenplum数据库内存
1 | gp_vmem = ((SWAP + RAM) – (7.5GB + 0.05 * RAM)) / 1.7 |
其中SWAP是主机交换空间,RAM是主机上的RAM,以GB为单位。
接下来,计算max_acting_primary_segments。 这是由于故障而激活mirror时主机上可以运行的primary的最大数量。 例如,如果mirror布置在4个主机块中,每个主机有8个primary,则单个segment主机故障将激活故障主机块中每个剩余主机上的两个或三个mirror。 此配置的max_acting_primary_segments值为11(8个primary加上3个失败时激活的mirror)。
这是gp_vmem_protect_limit的计算。 该值应转换为MB。
1 | gp_vmem_protect_limit = gp_vmem / acting_primary_segments |
对于生成大量工作文件的情况,这是计算工作文件的gp_vmem的计算。
1 | gp_vmem = ((SWAP + RAM) – (7.5GB + 0.05 * RAM - (300KB * total_#_workfiles))) / 1.7 |
有关监视和管理工作文件使用情况的信息,请参阅Greenplum数据库管理员指南。
根据gp_vmem值,您可以计算vm.overcommit_ratio操作系统内核参数的值。 配置每个Greenplum数据库主机时,将设置此参数。
1 | vm.overcommit_ratio = (RAM - (0.026 * gp_vmem)) / RAM |
Note: Red Hat Enterprise Linux中内核参数vm.overcommit_ratio的默认值为50。
| 取值范围 | 默认值 | 设置分类 |
|---|---|---|
| 整数 | 8192 | local system restart |
示例:
1 2 3 4 5 6 7 | gp_vmem(Greenplum数据库可用的主机内存): gp_vmem = ((SWAP + RAM) – (7.5GB + 0.05 * RAM)) / 1.7 = (500 -(7.5+0.05*500))/1.7 = 275G max_acting_primary_segments = 4 (格外加2个容错的primary)=6 gp_vmem_protect_limit = gp_vmem / max_acting_primary_segments = 275/6=46G = 46933MB |
shared_buffers设置一个segment实例用于共享内存缓冲区的内存量,至少为128KB与16KB * max_connections的较大者,6.14版本的默认为125MB。如果连接Greenplum时发生共享内存分配错误,可以尝试增加SHMMAX或SHMALL操作系统参数的值,或者降低shared_buffers或者max_connections参数的值解决此类问题。
数据距离CPU越近效率越高,而离CPU由近到远的主要设备有寄存器、CPU cache、RAM、Disk Drives等。CPU的寄存器和cache是没办法直接优化的,为了避免磁盘访问,只能尽可能将更多有用信息存放在RAM中。Greenplum数据库的RAM主要用于存放如下信息。
- 执行程序
- 程序数据和堆栈
- postgreSQL shared buffer cache
- kernel disk buffer cache
kernel
因此最大化地保持数据库信息在内存中而不影响其他区域才是最佳的调优方式,但这常常不是一件容易的事情。
PostgreSQL并非直接在磁盘上进行数据修改,而是将数据读入shared buffer cache,进而PostgreSQL后台进程修改cache中的数据块,最终再写回磁盘。后台进程如果在cache中找到相关数据,则直接进行操作,如果没找到,则需要从kernel disk buffer cache 或者磁盘中读入。PostgreSQL 默认的shared buffer较小,因为内存不仅仅用于shared buffer cache。
对于shared_buffers参数,刚开始可以设置一个较小的值,比如1G,然后逐渐增加,过程中监控性能提升和swap的情况。
另外一个方法就是观察缓存命中率,如果缓存命中率较低,那么就可以逐步增加shared_buffers参数。
经验:master节点的shared_buffers参数可以稍微大一点,例如8g或更高,而对于segment节点的shared_buffers参数一般配置1g足矣,注意给OS保留足够的内存,尽量不能频繁用到swap,否则会严重影响GP的性能。
max_connections
max_connections服务器参数限制对Greenplum数据库系统的并发访问数量,6.14版本的默认值Master为250,Segment为750。这是一个本地化参数,就是说需要把Master、Standby Master以及所有Segment都修改。建议Segment的值是Master的5-10倍,不过这个规律并非总是如此,在max_connections较大时通常没有这么高的倍数,2-3倍也是允许的,但Segment上的值不能小于Master。
增加此参数值可能会导致Greenplum数据库请求更多的共享内存。
max_connections = 300 #(master、standby)
max_connections = 1500 #(segment)
1 2 3 4 5 | #查看现有配置值: gpconfig -s max_connections #修改配置 gpconfig -c max_connections -v 6000 -m 2000 |
增加此参数时,还必须增加max_prepared_transactions。
如果配置过小,会话数满,则可能会报错:
1 2 3 4 5 6 7 8 | 20240430:13:25:07:3400256 gpconfig:mdw:gpadmin-[ERROR]:-FATAL: too many sessions DETAIL: Could not acquire resources for additional sessions. HINT: Disconnect some sessions and try again. 20240430:13:25:07:3400256 gpconfig:mdw:gpadmin-[ERROR]:-Failed to connect to database, exiting without action. This script can only be run when the database is up. Failed to connect to database, exiting without action. This script can only be run when the database is up. |
max_prepared_transactions
max_prepared_transactions设置同时处于准备状态的事务数,6.14版本的默认值为250。Greenplum内部使用准备事务保证跨Segment的数据完整性。该参数值必须大于等于max_connections,并且在Master和Segment上应该设置成相同的值。
这个参数只有在启动数据库时,才能被设置。它决定能够同时处于prepared状态的事务的最大数目(参考PREPARE TRANSACTION命令)。如果它的值被设为0。则将数据库将关闭prepared事务的特性。它的值通常应该和max_connections的值一样大。每个事务消耗600字节(b)共享内存。
1 2 3 4 5 6 7 8 | #查看现有配置值: gpconfig -s max_prepared_transactions Values on all segments are consistent GUC : max_prepared_transactions Master value: 250 Segment value: 250 #修改配置 gpconfig -c max_prepared_transactions -v 2000 |
设置可以同时处于准备状态的最大事务数。 Greenplum在内部使用准备好的事务来确保各个segment的数据完整性。 该值必须至少与master上的max_connections值一样大。 segment实例应设置为与master相同的值。
work_mem
work_mem(物理内存的2%~5%),每个segment实例用作sort、hash操作的内存大小。对于128G内存的segment实例来说,可以配置3G的work_mem。
当PostgreSQL对大表进行排序时,数据库会按照此参数指定大小进行分片排序,将中间结果存放在临时文件中,这些中间结果的临时文件最终会再次合并排序,所以增加此参数可以减少临时文件个数进而提升排序效率。当然如果设置过大,会导致swap的发生,所以设置此参数时仍需谨慎。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | #查看现有配置值 gpconfig -s work_mem Values on all segments are consistent GUC : work_mem Master value: 32MB Segment value: 32MB #修改配置 gpconfig -c work_mem -v 2GB 另一种写法:SET work_mem TO '64MB' #配置成功返回: gpadmin-[INFO]:-completed successfully with parameters |
参数work_mem在后期版本中可能会被废弃,不建议配置。WARNING "work_mem": setting is deprecated, and may be removed in a future release.
temp_buffers
即临时缓冲区,拥有数据库访问临时数据,在访问比较到大的临时表时,对性能提升有很大帮助。
1 2 3 4 5 6 7 8 9 | #查看现有配置值: gpconfig -s temp_buffers Values on all segments are consistent GUC : temp_buffers Master value: 1024 Segment value: 1024 #修改配置 gpconfig -c temp_buffers -v 4096 |
temp_buffers即临时缓冲区,用于数据库访问临时表数据,Greenplum默认值为32M。可以在单独的session中对该参数进行设置,在访问比较大的临时表时,对性能提升有很大帮助。
maintenance_work_mem
指定要在维护操作中使用的最大内存量,例如CREATE INDEX, VACUUM等时用到,segment用于VACUUM,CREATE INDEX等操作的内存大小,缺省是16兆字节(16MB)。因为在一个数据库会话里, 任意时刻只有一个这样的操作可以执行,并且一个数据库安装通常不会有太多这样的工作并发执行, 把这个数值设置得比work_mem更大是安全的。 更大的设置可以改进清理和恢复数据库转储的速度。
1 2 3 4 5 6 7 8 | #查看现有配置值 gpconfig -s maintenance_work_mem GUC : maintenance_work_mem Master value: 64MB Segment value: 64MB #修改配置 gpconfig -c maintenance_work_mem -v 256MB |
max_statement_mem
设置每个查询最大使用的内存量,该参数是防止statement_mem参数设置的内存过大导致的内存溢出.
1 2 3 4 5 6 7 8 9 10 | #查看现有配置值 gpconfig -s max_statement_mem Values on all segments are consistent GUC : max_statement_mem Master value: 2000MB Segment value: 2000MB #修改配置 gpconfig -c max_statement_mem -v 6GB |
设置查询的最大内存限制。 由于将statement_mem设置得太高,有助于在查询处理期间避免segment主机上的内存不足错误。 当gp_resqueue_memory_policy=auto时, statement_mem和资源队列内存限制控制查询内存使用量。 考虑到单个segment主机的配置,请按如下方式计算此设置:
1 | (seghost_physical_memory) / (average_number_concurrent_queries) |
更改max_statement_mem和statement_mem时, 必须先更改max_statement_mem,或者先在postgresql.conf文件中列出。
statement_mem
设置每个查询在segment主机中可用的内存,该参数设置的值不能超过max_statement_mem设置的值,如果配置了资源队列,则不能超过资源队列设置的值。 如果查询需要额外的内存,则使用磁盘上的临时溢出文件。
估算公式:( gp_vmem_protect_limitGB * .9 ) / max_expected_concurrent_queries ,例如:将gp_vmem_protect_limit设置为8192MB(8GB)并假设最多包含10%缓冲的40个并发查询
1 | (8GB * .9) / 40 = .18GB = 184MB |
配置参数:
1 2 3 4 5 6 7 8 9 | #查看现有配置值 gpconfig -s statement_mem Values on all segments are consistent GUC : statement_mem Master value: 125MB Segment value: 125MB #修改配置 gpconfig -c statement_mem -v 512MB |
1、参数statement_mem在6.24.4版本中测试的有问题,不能配置该参数,否则会导致GP不能启动。但在6.25.1中测试又正常了。
effective_cache_size
这个参数告诉PostgreSQL的优化器有多少内存可以被用来缓存数据,以及帮助决定是否应该使用索引,6.14版本的默认值为16GB。这个数值越大,优化器使用索引的可能性也越大。因此这个数值应该设置成shared_buffers加上可用操作系统缓存两者的总量。通常这个数值会超过系统内存总量的50%以上(master节点,可以设为物理内存的85%)。
设置优化器假设磁盘高速缓存的大小用于查询语句的执行计划判断,主要用于判断使用索引的成本,此参数越大越有机会选择索引扫描,越小越倾向于选择顺序扫描,此参数只会影响执行计划的选择。此参数仅用于估算目的,不影响Greenplum服务器实例分配的共享内存大小。
1 2 3 4 5 6 7 8 9 | #查看现有配置值: gpconfig -s effective_cache_size Values on all segments are consistent GUC : effective_cache_size Master value: 512MB Segment value: 512MB #修改配置 gpconfig -c effective_cache_size -v 60GB -m 100GB |
gp_resqueue_priority_cpucores_per_segment
master和每个segment的可以使用的cpu个数,每个segment的分配线程数;
指定每个segment实例分配的CPU单元数。 例如,如果Greenplum数据库群集具有配置有四个segment的10核心segment主机,请将segment实例的值设置为2.5。 对于master实例,值为10。 master主机通常只运行master实例,因此主机的值应反映所有可用CPU内核的使用情况。
设置每个Segment实例使用的CPU核数,6.14版本默认值为4。建议专用Master、Standby Master主机上设置为CPU核数,Segment主机上设置为CPU核数/(primary+mirror数量)。仅当使用基于资源队列时,才会强制执行该配置参数。
设置不正确可能导致CPU使用率不足或查询优先级不按设计工作。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | #查看现有配置值 gpconfig -s gp_resqueue_priority_cpucores_per_segment Values on all segments are consistent GUC : gp_resqueue_priority_cpucores_per_segment Master value: 4 Segment value: 4 gpconfig -s checkpoint_segments #修改配置 gpconfig -c gp_resqueue_priority_cpucores_per_segment -v 8 # 查询CPU个数 gpssh -f all_host lscpu | grep "] CPU(s):" |
gp_enable_global_deadlock_detector
gp_enable_global_deadlock_detector 控制是否启用Greenplum数据库全局死锁检测器来管理堆表上的并发更新和删除操作,以提高性能,默认设置为off,全局死锁检测器被禁用。启用全局死锁检测器允许并发更新,全局死锁检测器确定何时存在死锁,并通过取消与所涉及的最年轻事务关联的一个或多个后端进程来打破死锁。
log_statement
log_statement 参数控制日志中记录哪些SQL语句,6.14版本的可选值为NONE、DDL、MOD、ALL,默认值为ALL。DDL记录所有数据定义命令,如CREATE、ALTER和DROP命令。MOD记录所有DDL语句,以及INSERT、UPDATE、DELETE、TRUNCATE和COPY FROM,还会记录PREPARE和EXPLAIN ANALYZE语句。
gp_workfile_limit_files_per_query
SQL查询分配的内存不足,Greenplum数据库会创建溢出文件(也叫工作文件)。在默认情况下,一个SQL查询最多可以创建 100000 个溢出文件,这足以满足大多数查询。
该参数决定了一个查询最多可以创建多少个溢出文件。0 意味着没有限制。限制溢出文件数据可以防止失控查询破坏整个系统。
1 2 3 4 5 6 | # 查看现有配置值 gpconfig -s gp_workfile_limit_files_per_query Values on all segments are consistent GUC : gp_workfile_limit_files_per_query Master value: 100000 Segment value: 100000 |
设置gp_workfile_limit_files_per_query以限制每个查询允许使用的临时溢出文件 (工作文件)的最大数量。当查询要求的内存比它能分配的更多时,它将创建溢出文件。当上述限制被超过时,查询 会被中止。默认值为零,允许无限多的溢出文件并且可能会填满文件系统。
gp_autostats_mode、gp_autostats_on_change_threshold
参数gp_autostats_mode的可选值为:
- none: 禁用自动统计收集。
- on_no_stats:当任意一个CREATE TABLE AS SELECT、INSERT或者COPY命令在没有现存统计信息的表上执行时,on_no_stats模式会为该表触发一次分析操作。实际上默认情况下,我们对空表写入数据后, Greenplum 也会自动帮我们收集统计信息,不过之后再写入数据,就需要手动收集统计信息了。
- on_change:当任意一个CREATE TABLE AS SELECT、UPDATE、DELETE、INSERT或者COPY命令在表上执行并且被影响的行数超过gp_autostats_on_change_threshold配置参数所定义的阈值时, on_change模式会为该表触发一次分析操作。该动作是立即执行的。
通过on_change模式,只有受影响的行数超过gp_autostats_on_change_threshold配置参数所定义的阈值时才会触发ANALYZE。 这个参数的默认值是一个非常高的值2147483647(21亿),它实际上禁用了自动统计收集。 用户必须将该阈值设置得较低来启用它。on_change模式可能会触发大型的、预期之外的分析操作,它们可能会中断系统,因此不推荐在全局范围内设置它。 在一个会话中它可能会有用,例如在一次装载后自动分析一个表。
1 2 3 4 5 6 | gpconfig -c gp_autostats_mode -v on_change gpconfig -c gp_autostats_on_change_threshold -v 1000000 gpstop -u gpconfig -s gp_autostats_mode gpconfig -s gp_autostats_on_change_threshold |
optimizer
若数据量很小,但查询SQL复杂,若启用optimizer,则往往会报这个错,所以,此时可以在SQL级别禁用该参数。
表示运行SQL查询时启用或禁用GPORCA优化器。 默认on。 如果禁用GPORCA,则Greenplum数据库仅使用Postgres查询优化器(Legacy query) 。
GPORCA与Postgres查询优化器共存。 启用GPORCA后,Greenplum数据库会尽可能使用GPORCA为查询生成执行计划。 如果无法使用GPORCA,则使用Postgres查询优化器。
可以为数据库系统,单个数据库或会话或查询设置optimizer参数。
1 | set optimizer=0; |
在实操中发现,对于数据量比较小的复杂查询任务,开启该参数会降低查询速度或导致内存不足报错。对于数据量较大的查询任务,则可以起到查询优化的作用。
建议根据查询语句的类别进行定义该参数。
参考:https://www.dbaup.com/greenplumzhongdegporcayouhuaqi.html
https://www.dbaup.com/greenplumbaocuoerror-canceling-query-because-of-high-vmem-usage.html
max_files_per_process
设置每个服务器进程允许同时打开的最大文件数目。缺省是1000。 如果内核强制一个合理的每进程限制,那么你不用操心这个设置。 但是在一些平台上(特别是大多数BSD系统), 内核允许独立进程打开比个系统真正可以支持的数目大得多得文件数。 如果你发现有"Too many open files"这样的失败现像,那么就尝试缩小这个设置。 这个值只能在服务器启动的时候设置。
1 2 3 4 5 6 7 8 | #查看现有配置值: gpconfig -s max_files_per_process Values on all segments are consistent GUC : max_files_per_process Master value: 1000 Segment value: 1000 #修改配置 gpconfig -c max_files_per_process -v 1000 |
gp_fts_probe_threadcount
设置ftsprobe线程数,此参数建议大于等于每台服务器segments的数目。
1 2 3 4 5 6 | # 查看现有配置值: gpconfig -s gp_fts_probe_threadcount Values on all segments are consistent GUC : gp_fts_probe_threadcount Master value: 16 Segment value: 16 |
client_encoding
设置客户端字符集,默认和数据库encoding相同。
client_min_messages
控制发送至客户端的信息级别,每个级别包含更低级别的消息,越是低的消息级别发送至客户端的信息越少。例如,warning级包括warning、error、fatal、panic等级别的信息,而panic则只包括panic级别的信息。此参数主要用于错误调试。
1 2 3 | gpconfig -c client_min_messages -v WARNING gpconfig -s client_min_messages gpstop -u |
cpu_index_tuple_cost
设置执行计划评估每一个索引行扫描的CPU成本。同类参数还包括cpu_operator_cost、cpu_tuple_cost、cursor_tuple_fraction。
gp_resqueue_memory_policy
一般不建议修改该值。
Note: 仅当资源管理设置为资源队列时,gp_resqueue_memory_policy服务器配置参数才会生效。
gp_resqueue_memory_policy有none, auto, eager_free三种。
当设置为None,memory management与4.1版本GP相同。
当设置为auto,查询内存使用被statement_mem和资源队列memory_limit所限
默认为 eager_free,当设置为eager_free时,将会最大程度的使用内存,但不超过max_statement_mem和资源队列的memory_limit两个参数决定。如果当前用户不是普通用户或没有设置资源队列的memory_limit,那么内存的消耗只受max_statement_mem这个数值限定,该数值默认为2000MB。
分配算法eager_free利用了并非所有运算符同时执行的事实(在Greenplum Database 4.2及更高版本中)。 查询计划分为几个阶段,Greenplum数据库急切地释放在该阶段执行结束时分配给前一阶段的内存, 然后将急切释放的内存分配给新阶段。
参数gp_resqueue_memory_policy=eager_free时,表示数据库在评估SQL对内存的申请渴望时,分阶段统计,也就是说一个SQL可能总共需要申请1G内存,但是每个阶段只申请100MB,所以需要的内存实际上是100MB。
使用eager_free策略,可以降低QUERY报内存不足的可能性。