合 Greenplum数据库高可用性概述
Tags: GreenPlum高可用整理自网络整理自官网GPDB概述Group mirroringSpread mirroring
简介
当Greenplum数据库 集群不允许数据丢失时,master和segment镜像功能必须启用。没有镜像就不能保证系统和数据的 高可用,此时Pivotal会尽最大的努力恢复故障集群。当用户启用并且正确地配置Greenplum高可用特性时,Greenplum数据库支持高度可用的、容错的数据库服务。 要保证达到要求的服务等级,每个组件都必须有一个备用组件以保证在它失效时及时顶上。
Greenplum数据库系统的高可用可以通过提供容错硬件平台实现,可以通过启用Greenplum数据库高可用特性实现, 也可以通过执行定期监控和运维作业来确保整个系统所有组件保持健康来实现。
硬件平台的最终故障,可能因为常见的持久运行故障或非预期的运行环境。异常断电会导致组件临时不可用。系统可以 通过为可能故障的节点配置冗余备份节点来保证异常出现时仍能够不间断提供服务。在一些情况下,系统冗余的成本高于 用户的服务终端容忍度。此时,高可用的目标可以改为确保服务能在预期的时间内恢复。
Greenplum数据库的容错和高可用通过以下几种方式实现:
磁盘存储(硬件级别RAID)
Greenplum数据库部署最佳实践是采用硬件级别的RAID为单盘失败的情况提供高性能的磁盘冗余,避免只采用 数据库级别的容错机制。该方式可以在磁盘级别提供低级别的冗余保护。
源于Greenplum数据库的非共享MPP架构,每台master和segment主机都有它们自己独立的内存和磁盘存储空间, 每个master和segment实例都有它们自己独立的数据目录。为了兼顾可靠性和高性能,Pivotal推荐采用8到24块 磁盘的硬件RAID存储解决方案。当采用RAID5或RAID6时,大量的磁盘会提升I/O吞吐量,因为条带会增加并行的 磁盘I/O。有一个失效磁盘时,RAID控制器能够继续工作,因为它在每个磁盘上都保存了校验数据,这样它能够重构 阵列中任何失效磁盘上的数据。如果配置了热备盘(或者配置了能够用新磁盘替代故障磁盘的操作器),控制器能够 自动重建故障磁盘。
在RAID1模式下,实际上就是镜像一组磁盘,因此如果出现某块磁盘故障,替代磁盘立即可用,并且性能与出现磁盘 故障之前无二。在RAID5模式下,故障磁盘上的每一个数据I/O都必须从剩余活动磁盘上重建出来,直到故障磁盘重建 完成,因此会出现一段时间的性能下降。如果磁盘数据重建期间,Greenplum数据库master和segment配置了镜像 实例,您可以将任何受到影响的Greenplum数据库实例切换为它们的镜像以保证性能最优。
RAID磁盘阵列仍然可能会出现单点故障,例如整个RAID卷故障。在硬件级别上,可以通过RAID控制器提供的镜像功 能或操作系统提供的镜像功能来防范磁盘阵列故障。
定期监控每台主机的可用磁盘空间是很重要的。可以通过查询gptoolkit模式下的外部表 gp_disk_free来查看segment节点的磁盘可用空间。该视图会运行Linux命令df。 在执行占用大量磁盘空间的操作(例如copy大表)前要确保检查可用磁盘空间。
最佳实践
- 使用带有8到24个磁盘的硬件RAID存储方案。
- 使用RAID 1、5或6,这样磁盘阵列能容忍一个故障磁盘。
- 在磁盘阵列中配置一个热备盘以允许在检测到磁盘失效时自动开始重建。
- 通过镜像RAID磁盘组防止整个磁盘阵列的故障和重建期间的性能衰退。
- 定期监控磁盘利用率并且在需要时增加额外的磁盘空间。
- 监控segment数据倾斜以确保所有segment节点的数据均匀分布、空间合理利用。
数据存储总和校验
Greenplum数据库采用总和校验机制在文件系统上验证从磁盘加载到内存的数据没有被破坏。
Greenplum数据库有两种存储用户数据的方式:堆表和追加优化表。两种存储模型均采用总和校验机制 验证从文件系统读取的数据,默认配置下,二者采用总和校验机制验证错误的方式基本类似。
Greenplum数据库master和segment实例在他们所管理的自有内存中更新页上的数据。当内存页被更新 并刷新到磁盘时,会执行总和校验并保存起来。当下次该页数据从磁盘读取时,先进行总和校验,只有成功 通过验证的数据才能进入管理内存。如果总和校验失败,就意味着文件系统有损坏等情况发生,此时Greenplum 数据库会生成错误并中断该事务。
默认的总和校验设置能提供最好的保护,可以防止未检测到的磁盘损坏影响到数据库实例及其镜像Segment节点。
堆表的总和校验机制在Greenplum数据库采用gpinitsystem初始化时默认启用。我们可以通过设置 gpinitsystem配置文件中的HEAP_CHECKSUM参数为off来禁用堆表的总和校验 功能,但是我们强烈不推荐这么做,详见gpinitsystem。
一旦集群初始化完成,就不能改变堆表总和校验机制在该集群上的状态,除非重新初始化系统并重载数据库。
可以通过查看只读服务器配置参数 data_checksums 来查看 堆表的总和校验是否开启。
1 | $ gpconfig -s data_checksums |
当启动Greenplum数据库集群时,gpstart工具会检查堆表的总和校验机制在master和所有segment 上是启用了还是禁用了。如果有任何异常,集群会启动失败。详情请见gpstart。
在一些情况下,为了保证数据及时恢复有必要忽略堆表总和校验产生的错误,设置ignore_checksum_failure系统配置参数为on会使在堆表总和校验失败时只生成一个警告信息,数据页仍然可以被夹在到管理内存中。 如果该页被更新并存到磁盘,损坏的数据会被复制到镜像segment节点。因为该操作会导致数据丢失,所以只有在启用数据 恢复时才允许设置ignore_checksum_failure参数为on。
追加优化存储表的总和校验可以在使用CREATE TABLE命令创建表时定义。默认的存储选项在 gp_default_storage_options服务器配置参数中定义。checksum 存储选项默认被启用并且强烈不建议禁用它。
如果想要禁用追加优化表上的总和校验机制,你可以
- 在创建表时,修改gp_default_storage_options配置参数包含checksum=false 或
- 增加checksum=false选项到CREATE TABLE语句的WITH storage_options语法部分。
注意CREATE TABLE允许为每一个单独的分区表设置包括checksums在内的存储选项。
查看CREATE TABLE命令参考和gp_default_storage_options配置文件参考语法和示例。
Segment镜像
Greenplum数据库将数据存储在多个segment实例中,每一个实例都是Greenplum数据库的一个PostgreSQL实例, 数据依据建表语句中定义的分布策略在segment节点中分布。启用segment镜像时,每个segment实例都由一对 primary和mirror组成。镜像segment采用基于预写日志(WAL)流复制的方式保持与主segment 的数据一致。详情请见Segment镜像概述。
镜像实例通常采用gpinitsystem或gpexpand工具进行初始化。 作为最佳实践,为了保证单机失败镜像通常运行在与主segment不同的主机上。将镜像分配到不同的主机上也有不同 的策略。当搭配镜像和主segment的放置位置时,要充分考虑单机失败发生时处理倾斜最小化的场景。
Greenplum数据库的每一个segment实例都在master实例的协调下存储和管理数据库数据的一部分。如果任何未配置 镜像的segment故障,数据库可能不得不被关闭然后恢复,并且在最近备份之后发生的事务可能会丢失。因此,镜像 segment是高可用方案的一个不可或缺的元素
Segment镜像是主segment的热备。Greenplum数据库会检测到segment何时不可用并且自动激活其镜像。在正常操作 期间,当主segment实例活动时,数据以两种方式从主segment复制到镜像segment:
- 在事务被提交之前,事务提交日志被从主segment复制到镜像segment。这会确保当镜像被激活时,主segment 上最后一个成功的事务所作的更改会出现在镜像上。当镜像被激活时,日志中的事务会被应用到镜像中的表上。
- 第二种,segment镜像使用物理文件复制来更新堆表。Greenplum服务器在磁盘上以打包了元组的固定尺寸块 的形式存储表数据。为了优化磁盘I/O,块被缓冲在内存中,直到缓存被填满并且一些块必须被挤出去为新更新 的块腾出空间。当块被从缓存中挤出时,它会被写入到磁盘并且通过网络复制到镜像。因为缓冲机制,镜像上的 表更新可能落后于主segment。不过,由于事务日志也被复制,镜像会与主segment保持一致。如果镜像被激活, 激活过程会用事务提交日志中未应用的更改更新表。
当活动的主segment不能访问其镜像时,复制会停止并且主segment的状态会改为“Change Tracking”。主segment 会把没有被复制到镜像的更改保存在一个系统表中,等到镜像重新在线时这些更改会被复制到镜像。
Master会自动检测segment故障并且激活镜像。故障时正在进行的事务会使用新的主segment重新开始。根据镜像被 部署在主机上的方式,数据库系统可能会不平衡直到原始的主segment被恢复。例如,如果每台segment主机有四个主 segment和四个镜像segment,并且在一台主机上有一个镜像segment被激活,那台主机将有五个活动的主segment。 查询直到最后一个Segment完成其工作才算结束,因此性能可能会退化直至原始的主segment被恢复使得系统恢复平衡。
当Greenplum数据库运行时,管理员通过运行gprecoverseg工具执行恢复。这个工具会定位 故障的segment、验证它们是否有效并且与当前活动的segment对比事务状态以确定segment离线期间发生的更改。 gprecoverseg会与活动segment同步更改过的数据库文件并且将该segment重新拉回到在线 状态。
在故障期间,有必要在segment主机上保留足够的内存和CPU资源,以允许承担了主segment觉得的镜像实例能提供 对应的活动负载。为Greenplum数据库配置内存中提供的配置 segment主机内存的公式包括一个因子,它代表故障期间任一主机上的最大主segment数量。segment主机上的镜像 布置会影响这一因子以及系统在故障时将如何应对。Segment镜像选项的讨论请见Segment镜像配置。
Segment镜像概述
当Greenplum数据库高可用性被启用时,有两种类型的Segment:primarySegment 和mirrorSegment。每个主Segment都有一个对应的镜像Segment。主Segment从 Master接收请求来对该Segment的数据库做更改并且接着把那些更改复制到对应的镜像。 如果主Segment变成不可用,镜像segment会切换为主segment,不可用的主segment会切换为 镜像segment。故障出现时正在进行的事务会回滚并且必须重启数据库。接下来管理员必须恢复镜像segment,并 允许镜像segment与当前主segment进行同步,最后需要交换主segment和镜像segment的角色,让他们处于自己 最佳的角色状态。
如果segment镜像未启用,当出现segment实例故障时,Greenplum数据库系统会关闭。管理员必须手工恢复所有 失败的segment实例然后才能重新启动数据库。
如果现有系统已经启用了segment镜像,当主segment实例正在生成一个快照时,主segment实例继续为用户提供服务。 当主segment快照完成并向镜像segment实例部署时,主segment的变化也会被记录。当快照完全部署到镜像segment 后,镜像segment会同步这些变化并采用WAL流复制的方式与主segment保持一致。Greenplum数据库的WAL复制使用 walsender和walreceiver复制进程。 walsender进程是主segment的进程。walreceiver进程是镜像segment 的进程。
当数据库变化出现时,日志捕获到该变化然后将变化流向镜像segment,以保证镜像与其对应的主segment一致。在WAL 复制期间,数据库变化在被应用之前先写入日志中,以确保任何正在处理的数据的完整性。
当Greenplum数据库检测到主segment故障时,WAL复制进程停止,镜像segment自动接管成为活动主segment。如果 主segment活动时,镜像segment故障或变得不可访问,主segment会追踪数据库变化并记录在日志中,当镜像恢复后 应用到镜像节点。有关segment故障检测和故障处理的详细信息,请见 检测故障的Segment。
Greenplum数据库系统表包含镜像和复制的详细信息。
- 系统表 gp_segment_configuration包含主segment、镜像segment、主master和standby master实例的当前配置和 状态信息。
- 系统视图gp_stat_replication包含Greenplum数据库master和segment镜像功能使用的walsender 进程的复制状态统计信息。
最佳实践
- 为所有segment设置镜像。
- 将主segment及其镜像放置在不同主机上以防止主机失效。
- 镜像可以放在一组单独的主机上或者主segment所在的主机上。
- 设置监控,当主segment故障时在系统监控应用中发送通知或者通过邮件通知。
- 即使恢复失效的segment,使用gprecoverseg工具来恢复冗余并且让系统回到最佳的 平衡状态。
关于Segment镜像配置
镜像segment实例可以根据配置的不同在集群主机中按不同的方式分布。作为最佳实践,主segment和它对应的镜像 放在不同的主机上。每台主机必须有相同的主和镜像segment。当你使用Greenplum工具gpinitsystem或 gpaddmirrors创建segment镜像时,可以设定segment镜像方式:以分组的方式镜像(默认)或 以打散的方式镜像。采用gpaddmirrors命令时,可以先创建gpaddmirrors 配置文件,然后将文件放在命令行读取执行。
以分组的方式镜像是默认的镜像方式。该方式每台主机的主segment对应的镜像都整体放在另一台主机上, 如果有一台主机故障,另外一台接管该主机服务的镜像所在的机器的活动segment数量便会翻倍。 图表 Figure 1 显示了以分组的方式配置segment镜像。
Figure 1. 以分组的方式在Greenplum数据库中分布镜像 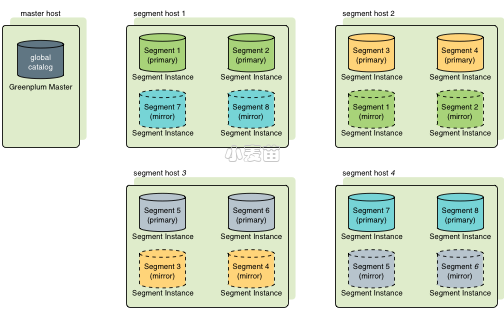
以打散的方式镜像 将每一个主机的镜像分散到多台主机上,保证每一个机器上至多只有一个 镜像提升为主segment,这种方式可以防止单台主机故障后,另外的主机压力骤增。以打散方式镜像 分布要求集群主机数量多于每台主机上segment的数量。图表Figure 2显示了如何以打散的方式配置segment镜像。
Figure 2. 以打散的方式在Greenplum数据库中分布镜像 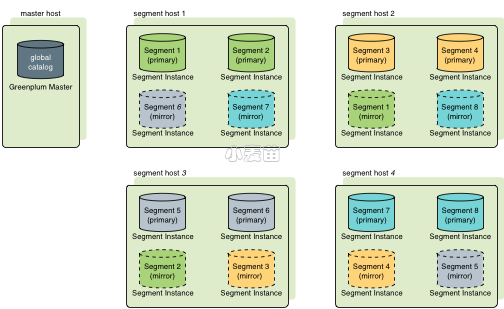
Segment镜像配置
Segment镜像允许数据库查询在主Segment故障或者不可用时转移到备份segment上。Pivotal要求在其支持的 Greenplum数据库生产环境中必须配置镜像。
为了确保高可用,主segment及其镜像必须位于不同主机上。Greenplum数据库系统中的每一台主机都有相同数量 的主segment和镜像segment。多宿主主机应该在每个接口上有相同数量的主segment和镜像segment。这能确保 所有主segment运行时,segment主机和网络资源的负载均衡,并且提供最多的资源承担查询处理。
当segment变得不可用时,它位于另一台主机上的镜像segment会变成活动的主segment继续处理请求。主机上的 额外负载会导致倾斜以及性能下降,但是最起码可以保证系统继续可用。数据库查询会等待系统中所有segment都 返回结果后结束,所以当台主机上将镜像提升为主segment和在系统中每台机器都增加一个segment实例是相同的 效果。
在故障场景下,每台主机上替代故障segment的镜像实例不超过一个时,整个数据库系统的性能下降最小。如果多个 segment或主机故障,性能下降的影响受那台唤起镜像实例最多的机器影响。将一台主机的镜像散布在其余的主机上 可以最小化任意单主机故障时的性能下降。
也有必要考虑集群对多主机故障的容忍能力,以及通过增加主机来扩展集群时如何维护镜像配置。没有一种镜像配置 是放之四海而皆准的解决方案。
您可以采用两种镜像标准配置方式中的任意一种来在主机上配置镜像方式,也可以设计您自己的镜像配置方案。
两种标准的镜像配置方式分别是group mirroring和spread mirroring:
- Group mirroring — 每台主机镜像另外机器的主segment。这是 gpinitsystem和gpaddmirrors的默认选项。
- Spread mirroring — 镜像分散分布在另外的机器上。这要求集群中的主机数量多于每台主机上的 segment实例数量。
您可以设计一个客户镜像配置文件然后使用Greenplum工具gpaddmirrors或 gpmovemirrors进行 配置。
Block mirroring一种自定义镜像配置,它把集群中的主机划分成相等尺寸的块并且在块内的主机上均匀 地分布镜像。如果一个主segment故障,其在同一个块的另一主机上的镜像会变成活动的主segment。如果一台segment 主机故障,在该块中其他每一台主机上的镜像segment都会变成活动segment。
以下部分比较group, spread, 和block mirroring镜像配置。
Group Mirroring
Group mirroring是最容易设置的镜像配置,并且是Greenplum的默认镜像配置。组镜像的扩展代价最低,因为 可以通过增加仅仅两台主机来完成扩展。在扩展之后无需移动镜像来维持镜像配置的一致性。
下面的图显示了一个在四台主机上带有八个主segment的group mirroring配置。
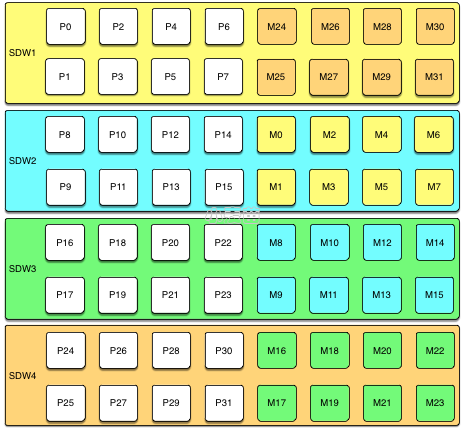
除非同一个segment实例的主segment和镜像都出现故障,最多可以有一半的主机故障并且集群将继续运行,只要 资源(CPU、内存和IO)足以满足需求。
任何主机故障将会让性能退化一半以上,因为具有镜像的主机将承担两倍的活动主segment。如果用户的资源利用 通常会超过50%,用户将不得不调整其负载,直至故障主机被恢复或者替换。如果用户通常的资源利用低于50%,则 集群会继续以退化的性能水平运行,直至故障被修复。
Spread Mirroring
通过spread mirroring,每台主机的主要Segment的镜像被散布在若干台主机上,涉及到的主机数量与每台主机上 segment数量相同。在集群初始化时设置spread mirroring很容易,但是要求集群中的主机数至少为每台主机上的 segment数加一。