合 内存分配中的NUMA
简介
numa是一种关于多个cpu如何访问内存的架构模型,现在的cpu基本都是numa架构,linux内核2.5开始支持numa。
内存访问分为两种体系结构:一致性内存访问(UMA)和非一致性内存访问(NUMA)。NUMA指CPU对不同内存单元的访问时间可能不一样,因而这些物理内存被划分为几个节点,每个节点里的内存访问时间一致,NUMA体系结构主要存在大型机器、alpha等,嵌入式的基本都是UMA。UMA也使用了节点概念,只是永远都只有1个节点。
NUMA(Non-Uniform Memory Access)是相对UMA来说的,两者都是CPU的设计架构,早期CPU设计为UMA结构,如下图所示:
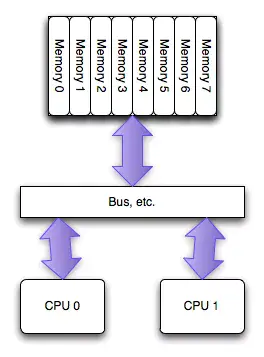
为了缓解多核CPU读取同一块内存所遇到的通道瓶颈问题,芯片工程师又设计了NUMA结构,如下图所示:
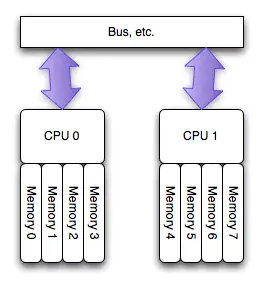
如图所示,NUMA使得每个CPU都有自己专属的内存区域。 NUMA 服务器的基本特征是 Linux 将系统的硬件资源划分为多个节点(Node),每个节点上有单独的 CPU、内存和 I/O 槽口等。CPU 访问自身 Node 内存的速度将远远高于访问远地内存(系统内其它节点的内存)的速度,这也是非一致内存访问 NUMA 的由来。
只有当CPU访问自身直接attach内存对应的物理地址时,才会有较短的响应时间(Local Access)。而如果需要访问其他CPU attach的内存的数据时,就需要通过inter-connect通道访问,响应时间就相比之前变慢了(Remote Access)。NUMA这种特性可能会导致CPU内存使用不均衡,部分CPU的local内存不够使用,频繁需要回收,进而可能发生大量swap,系统响应延迟会严重抖动。而与此同时其他部分CPU的local内存可能都很空闲。这就会产生一种怪现象:使用free命令查看当前系统还有部分空闲物理内存,系统却不断发生swap,导致某些应用性能急剧下降。
NUMA这种架构可以很好解决UMA的问题,即不同CPU有专属内存区,为了实现CPU之间的”内存隔离”,还需要软件层面两点支持:
- 内存分配需要在请求线程当前所处CPU的专属内存区域进行分配。如果分配到其他CPU专属内存区,势必隔离性会受到一定影响,并且跨越总线的内存访问性能必然会有一定程度降低。
- 一旦local内存(专属内存)不够用,优先淘汰local内存中的内存页,而不是去查看远程内存区是否会有空闲内存借用。
NUMA中,虽然内存直接访问在CPU上,但是由于内存被平均分配在了各个CPU上。只有当CPU访问自身直接访问内存对应的物理地址时,才会有较短的响应时间(后称Local Access)。而如果需要访问其他CPU attach的内存的数据时,就需要通过互联通道访问,响应时间就相比之前变慢了(后称Remote Access)。所以NUMA(Non-Uniform Memory Access)就此得名。
在NUMA架构(多CPU)下,每个node(物理CPU)都有自己的本地内存,在分析内存的时候需要分析每个node的情况:
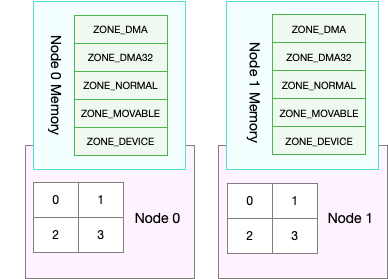
/proc/sys/vm/zone_reclaim_mode设置NUMA本地内存的回收策略,当node本地内存不足时,默认可以从其它node寻找空闲内存,也可以从本地回收。
numa架构简单点儿说就是,一个物理cpu(一般包含多个逻辑cpu或者说多个核心)构成一个node,这个node不仅包括cpu,还包括一组内存插槽,也就是说一个物理cpu以及一块内存构成了一个node。每个cpu可以访问自己node下的内存,也可以访问其他node的内存,但是访问速度是不一样的,自己node下的更快。
numactl --hardware命令可以查看node状况。通过numactl启动程序,可以指定node绑定规则和内存使用规则。可以通过cpunodebind参数使进程使用固定node上的cpu,使用localalloc参数指定进程只使用cpu所在node上分配的内存。如果分配的node上的内存足够用,这样可以减少抖动,提供性能。如果内存紧张,则应该使用interleave参数,否则进程会因为只能使用部分内存而out of memory或者使用swap区造成性能下降。
NUMA的内存分配策略有localalloc、preferred、membind、interleave。
- localalloc规定进程从当前node上请求分配内存;
- preferred比较宽松地指定了一个推荐的node来获取内存,如果被推荐的node上没有足够内存,进程可以尝试别的node。
- membind可以指定若干个node,进程只能从这些指定的node上请求分配内存。
- interleave规定进程从指定的若干个node上以RR(Round Robin 轮询调度)算法交织地请求分配内存。
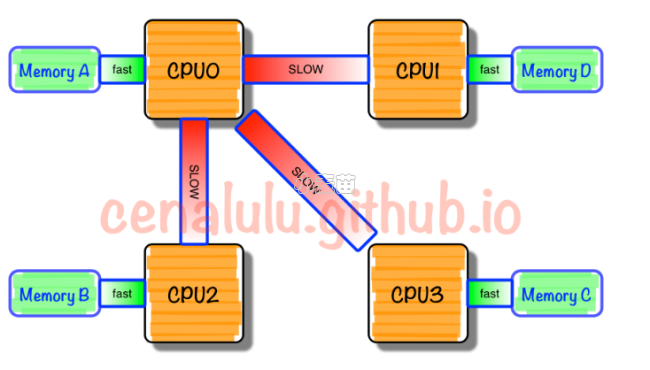
在目前主流服务器上,一般都拥有多个CPU节点,而一个CPU节点,会拥有10~20个物理核心。如果一个服务器拥有多个CPU节点,那么我们也称这个服务器拥有多个CPU Socket,Socket简单理解,就是一个CPU节点,如下图所示:
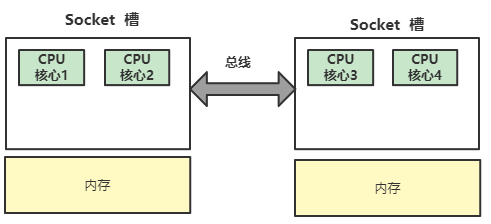
如图为4核心CPU的架构,其中,CPU核心1、2在同一个Socket中,CPU核心3、4在另外一个Socket中。Socket之间,通过CPU总线来连接,每个Socket控制一块内存。
单节点物理CPU输出
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 | [root@oracle-rac1 ~]# lscpu Architecture: x86_64 CPU op-mode(s): 32-bit, 64-bit Byte Order: Little Endian CPU(s): 8 On-line CPU(s) list: 0-7 Thread(s) per core: 2 Core(s) per socket: 4 Socket(s): 1 NUMA node(s): 1 Vendor ID: GenuineIntel CPU family: 6 Model: 85 Model name: Intel(R) Xeon(R) Gold 6278C CPU @ 2.60GHz Stepping: 7 CPU MHz: 2600.000 BogoMIPS: 5200.00 Hypervisor vendor: KVM Virtualization type: full L1d cache: 32K L1i cache: 32K L2 cache: 1024K L3 cache: 36608K NUMA node0 CPU(s): 0-7 Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc rep_good nopl xtopology nonstop_tsc eagerfpu pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch invpcid_single ssbd ibrs ibpb stibp ibrs_enhanced fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm mpx avx512f avx512dq rdseed adx smap clflushopt clwb avx512cd avx512bw avx512vl xsaveopt xsavec xgetbv1 arat avx512_vnni md_clear spec_ctrl intel_stibp flush_l1d arch_capabilities [root@oracle-rac1 ~]# [root@oracle-rac1 ~]# lscpu -e CPU NODE SOCKET CORE L1d:L1i:L2:L3 ONLINE 0 0 0 0 0:0:0:0 yes 1 0 0 0 0:0:0:0 yes 2 0 0 1 1:1:1:0 yes 3 0 0 1 1:1:1:0 yes 4 0 0 2 2:2:2:0 yes 5 0 0 2 2:2:2:0 yes 6 0 0 3 3:3:3:0 yes 7 0 0 3 3:3:3:0 yes |
多节点物理CPU输出
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | [root ~]# lscpu Architecture: x86_64 CPU op-mode(s): 32-bit, 64-bit Byte Order: Little Endian CPU(s): 24 On-line CPU(s) list: 0-23 Thread(s) per core: 2 Core(s) per socket: 6 Socket(s): 2 NUMA node(s): 2 Vendor ID: GenuineIntel CPU family: 6 Model: 62 Model name: Intel(R) Xeon(R) CPU E5-2620 v2 @ 2.10GHz Stepping: 4 CPU MHz: 2399.926 CPU max MHz: 2600.0000 CPU min MHz: 1200.0000 BogoMIPS: 4190.02 Virtualization: VT-x L1d cache: 32K L1i cache: 32K L2 cache: 256K L3 cache: 15360K NUMA node0 CPU(s): 0-5,12-17 NUMA node1 CPU(s): 6-11,18-23 |
重点关注:
CPU(s): 24Socket(s): 2Thread(s) per core: 2 Core(s) per socket: 6NUMA node(s): 2NUMA node0 CPU(s): 0-5,12-17 NUMA node1 CPU(s): 6-11,18-23
使用lscpu查看当前服务器的CPU情况,可以看出:
1、当前服务器有2个CPU处理器(2个物理CPU),Sockets=2
2、每个socket上有6个物理核心,Cores per socket=6
3、每个物理核心有2个逻辑线程(即逻辑CPU),Threads per core=2
4、累计2*6*2=24个逻辑线程(即逻辑CPU),其中
NUMA node0的CPU核编号是0~5,12~17
NUMA node1的CPU核编号是6~11,18~23
5、上述NUMA编号中,0和12、1和13、...5和17,分别为一个物理核心上的2个逻辑线程。
画图更容易理解:
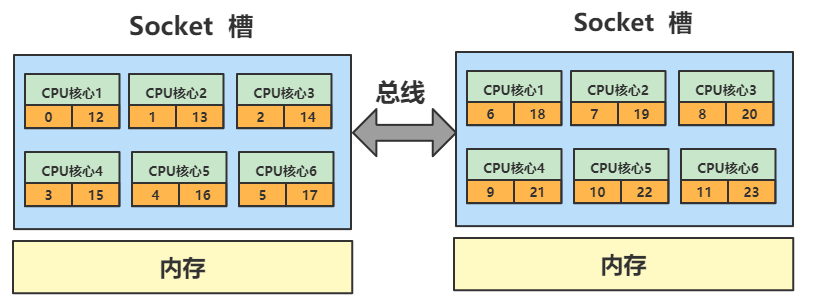
再给出一个华为云裸金属上的cpu架构,如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 | [root@dg ~]# lscpu Architecture: x86_64 CPU op-mode(s): 32-bit, 64-bit Byte Order: Little Endian CPU(s): 56 On-line CPU(s) list: 0-55 Thread(s) per core: 2 Core(s) per socket: 14 Socket(s): 2 NUMA node(s): 2 Vendor ID: GenuineIntel CPU family: 6 Model: 85 Model name: Intel(R) Xeon(R) Gold 5120 CPU @ 2.20GHz Stepping: 4 CPU MHz: 2200.000 BogoMIPS: 4405.34 Virtualization: VT-x L1d cache: 32K L1i cache: 32K L2 cache: 1024K L3 cache: 19712K NUMA node0 CPU(s): 0-13,28-41 NUMA node1 CPU(s): 14-27,42-55 [root@dg ~]# lscpu -e CPU NODE SOCKET CORE L1d:L1i:L2:L3 ONLINE 0 0 0 0 0:0:0:0 yes 1 0 0 1 1:1:1:0 yes 2 0 0 2 2:2:2:0 yes 3 0 0 3 3:3:3:0 yes 4 0 0 4 4:4:4:0 yes 5 0 0 5 5:5:5:0 yes 6 0 0 6 6:6:6:0 yes 7 0 0 7 7:7:7:0 yes 8 0 0 8 8:8:8:0 yes 9 0 0 9 9:9:9:0 yes 10 0 0 10 10:10:10:0 yes 11 0 0 11 11:11:11:0 yes 12 0 0 12 12:12:12:0 yes 13 0 0 13 13:13:13:0 yes 14 1 1 14 14:14:14:1 yes 15 1 1 15 15:15:15:1 yes 16 1 1 16 16:16:16:1 yes 17 1 1 17 17:17:17:1 yes 18 1 1 18 18:18:18:1 yes 19 1 1 19 19:19:19:1 yes 20 1 1 20 20:20:20:1 yes 21 1 1 21 21:21:21:1 yes 22 1 1 22 22:22:22:1 yes 23 1 1 23 23:23:23:1 yes 24 1 1 24 24:24:24:1 yes 25 1 1 25 25:25:25:1 yes 26 1 1 26 26:26:26:1 yes 27 1 1 27 27:27:27:1 yes 28 0 0 0 0:0:0:0 yes 29 0 0 1 1:1:1:0 yes 30 0 0 2 2:2:2:0 yes 31 0 0 3 3:3:3:0 yes 32 0 0 4 4:4:4:0 yes 33 0 0 5 5:5:5:0 yes 34 0 0 6 6:6:6:0 yes 35 0 0 7 7:7:7:0 yes 36 0 0 8 8:8:8:0 yes 37 0 0 9 9:9:9:0 yes 38 0 0 10 10:10:10:0 yes 39 0 0 11 11:11:11:0 yes 40 0 0 12 12:12:12:0 yes 41 0 0 13 13:13:13:0 yes 42 1 1 14 14:14:14:1 yes 43 1 1 15 15:15:15:1 yes 44 1 1 16 16:16:16:1 yes 45 1 1 17 17:17:17:1 yes 46 1 1 18 18:18:18:1 yes 47 1 1 19 19:19:19:1 yes 48 1 1 20 20:20:20:1 yes 49 1 1 21 21:21:21:1 yes 50 1 1 22 22:22:22:1 yes 51 1 1 23 23:23:23:1 yes 52 1 1 24 24:24:24:1 yes 53 1 1 25 25:25:25:1 yes 54 1 1 26 26:26:26:1 yes 55 1 1 27 27:27:27:1 yes |
大家可以自己分析。
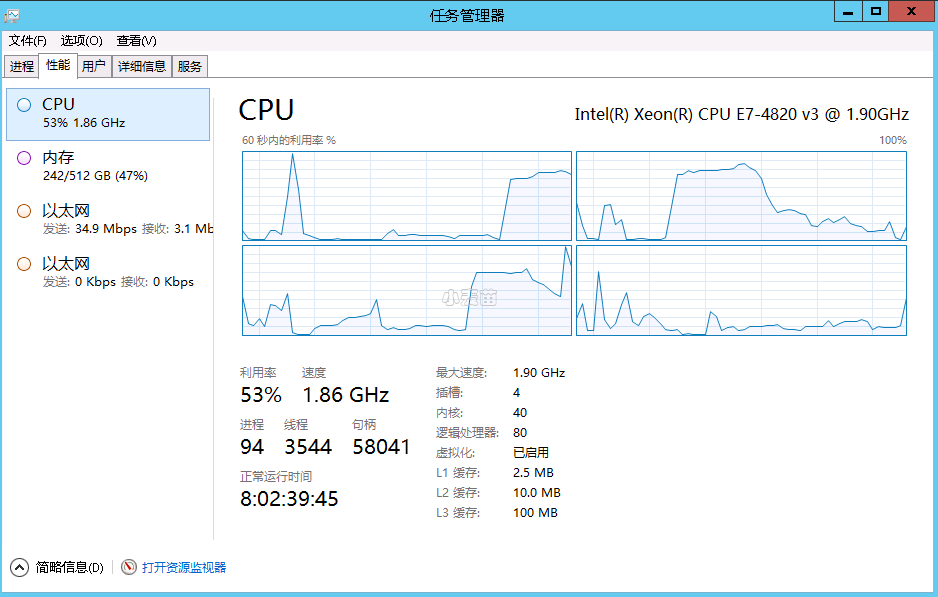
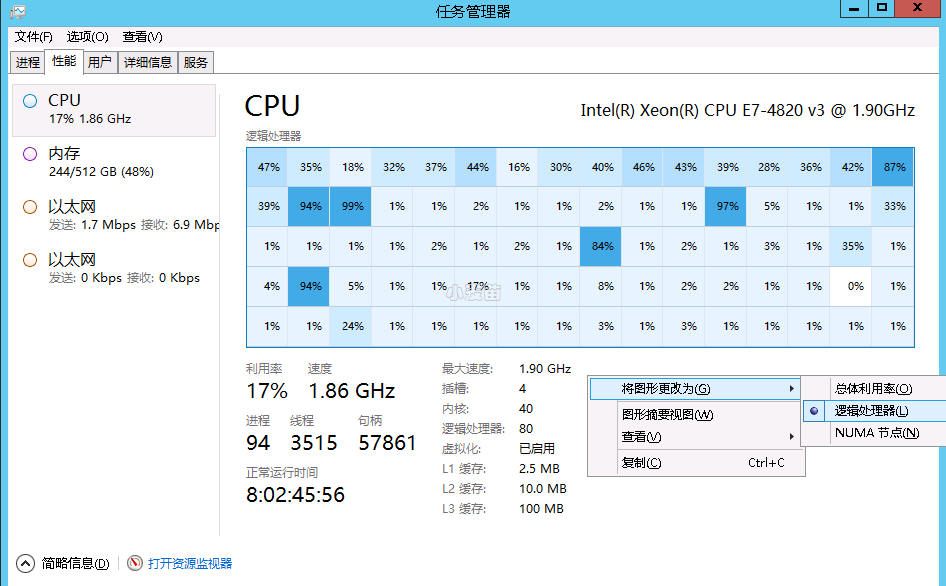
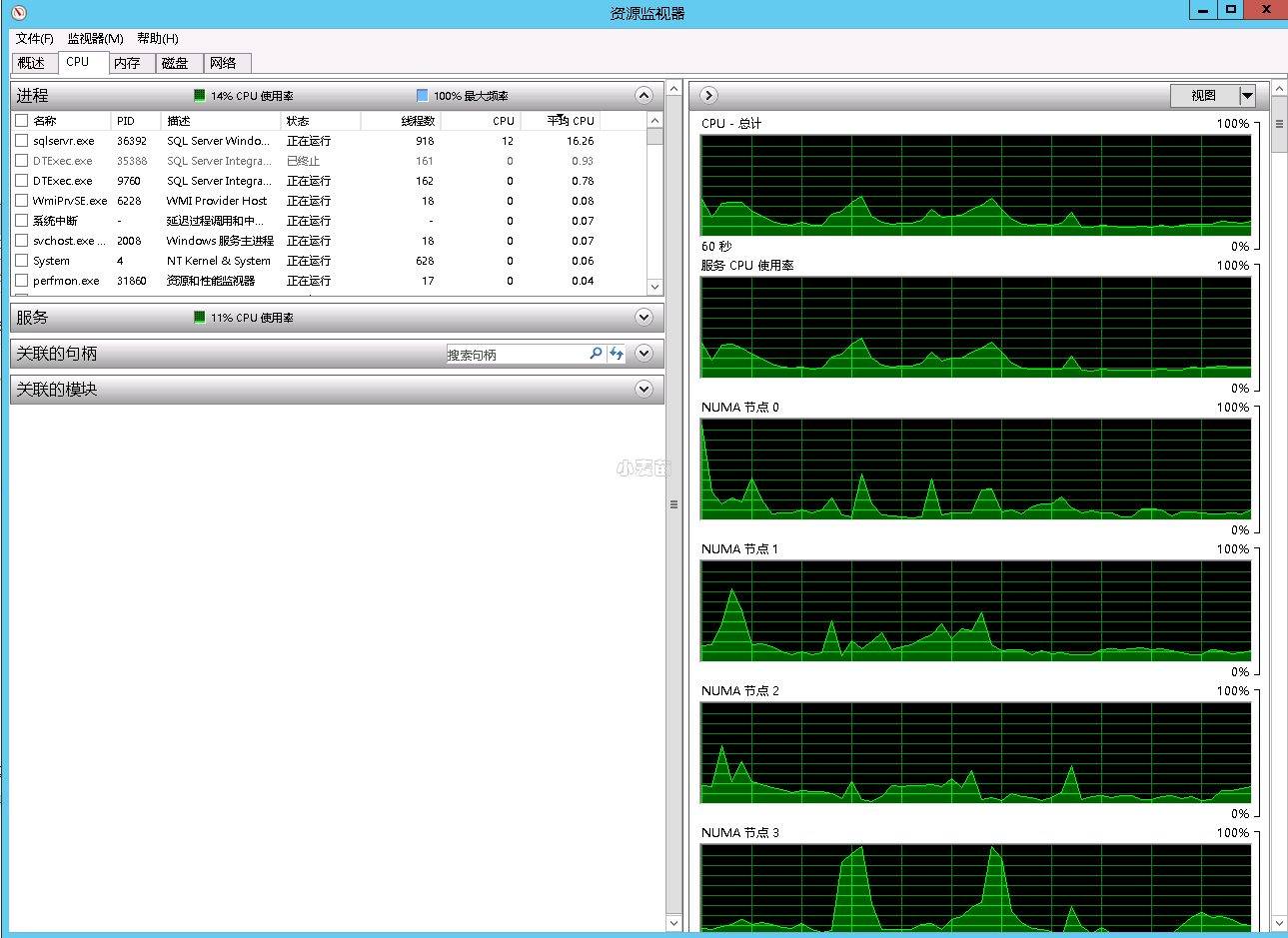
Windows上的NUMA