合 MSSQL中的锁和阻塞
Tags: MSSQLSQL Server整理自网络整理自官网锁阻塞
- 了解并解决 SQL Server 阻塞定问题
- 目标
- 什么是阻塞
- 应用程序和阻塞
- 对阻塞问题进行疑难解答
- 收集阻塞信息
- 收集来自 DMV 的信息
- 从扩展事件收集信息
- 识别并解决常见的阻塞场景
- 分析阻塞数据
- 常见的阻塞场景
- 详细的阻止方案
- 方案 1:由正常运行的查询导致的阻塞,执行时间较长
- 方案 2:由具有未提交的事务的休眠 SPID 导致的阻塞
- 方案 3:由 SPID 导致的阻塞,其相应的客户端应用程序未提取所有结果行直至完成
- 方案 4:由分布式客户端/服务器死锁导致的阻塞
- 示例 A:具有单一客户端线程的客户端/服务器分布式死锁
- 示例 B:客户端/服务器分布式死锁(每个连接都有一个线程)
- 方案 5:由处于回滚状态的会话导致的阻塞
- 方案 6:孤立事务导致的阻塞
- 解决SQL Server中锁升级导致的阻塞问题
- 摘要
- 确定锁升级是否导致阻塞
- 防止锁升级
- 禁用锁升级
- 锁定升级阈值
- 建议
- 排查由编译锁引起的阻塞问题
- 摘要
- 更多信息
- 导致编译锁的其他方案
- sys.partitions (Transact-SQL)
- 权限
- 示例
- 确定对象使用的空间并显示相关的分区信息
- 并发事务:死锁跟踪
- 并发事务:死锁跟踪之确定死锁锁定的资源
- 6种跟踪死锁的方法总结
- 方法一:Windows 性能计数器监控
- 方法二:打开profiler跟踪事件 locks: deadlock graph
- 方法三:打开1222或者1204标志记录死锁,在sqlserver日志查看
- 方法四:扩展事件
- 方法五:系统扩展事件会话system_health自动记录
- 方法六:Service Broker Event Notifications
- SQL Server中的HOBT
- 锁介绍
- 锁的全面认识
- 锁的互斥(兼容性)
- 锁与事务关系
- 锁的持续时间
- 锁的升级
- 锁的超时
- 资源等待lck
- 自旋锁
- 为什么我们需要自旋锁?
- 自旋锁与故障排除
- 自己阻塞自己
- -2进程死锁无法终止问题
- 锁排查之SQL整理
- HOBT
- LCK_M_S
- PAGEIOLATCH_SH
- 总结
- 参考
了解并解决 SQL Server 阻塞定问题
目标
本文介绍 SQL Server 中的阻塞,并演示如何对阻塞问题进行疑难解答并解决阻塞问题。
在本文中,术语连接是指数据库的单个登录会话。 在许多 DMV 中,每个连接都显示为会话 ID (SPID) 或 session_id。 每个这种 SPID 通常都称为一个进程,尽管在通常意义上它不是单独的进程上下文。 相反,每个 SPID 都包含服务来自给定客户端的单个连接请求所需的服务器资源和数据结构。 单个客户端应用程序可能包含一个或多个连接。 从 SQL Server 的角度来看,单客户端计算机上单客户端应用程序的多个连接与多客户端应用程序或多客户端计算机的多个连接之间没有区别;它们是最小单元。 无论源客户端如何,一个连接都可以阻塞另一个连接。
备注
本文重点介绍 SQL Server 实例,包括 Azure SQL 托管实例。 有关对 Azure SQL 数据库中阻塞问题进行疑难解答的特定信息,请参阅了解并解决 Azure SQL 数据库阻塞问题。
什么是阻塞
阻塞是任何具有基于锁定并发的关系数据库管理系统 (RDBMS) 不可避免的设计特征。 如前所述,在 SQL Server 中,当一个会话持有特定资源的锁,第二个 SPID 尝试在同一资源上获取冲突锁类型时,会发生阻塞。 通常,第一个 SPID 锁定资源的时间范围较小。 当所属会话释放锁时,第二个连接可以自由其在获取资源上的锁并继续处理。 此处所述锁定是正常行为,一天可能会发生多次,不会对系统性能产生明显影响。
查询的持续时间和事务上下文决定其持有锁的时间,从而决定它们对其他查询的影响。 如果查询未在事务中执行(并且未使用锁提示),则仅在实际读取 SELECT 语句时(而不是在查询期间)才会在资源上持有 SELECT 语句的锁。 对于 INSERT、UPDATE 和 DELETE 语句,在查询期间回持有锁,既确保数据一致性,又允许在必要时回滚查询。
对于在事务中执行的查询, 持有锁的持续时间由查询类型、事务隔离级别以及是否在查询中使用锁提示来确定。 有关锁定、锁定提示和事务隔离级别的说明,请参阅以下文章:
以下原因会导致锁定和阻塞持续到对系统性能产生不利影响:
- SPID 在释放一组资源之前,会在一段较长的时间内持有这些资源的锁。 这种类型的阻塞会随着时间推移自行解析,但可能导致性能下降。
- SPID 持有一组资源的锁,并且从不释放它们。 这种类型的阻塞不会自行解析,并且会无限期地阻止访问受影响的资源。
在第一个场景中,情况可能非常不稳定,因为不同的 SPID 会随着时间推移阻塞不同资源,从而形成移动目标。 这些情况很难通过 SQL Server Management Studio 将问题缩小到单个查询来进行故障排除。 相比之下,第二种情况会出现一致状态,从而更轻松地进行诊断。
应用程序和阻塞
遇到阻塞问题时,可能会倾向于关注服务器端优化和平台问题。 但是,只关注数据库可能无法解决问题,但能够更好地吸收时间和精力来检查客户端应用程序及其提交的查询。 无论应用程序对数据库调用公开的可见性级别如何,阻塞问题仍然经常需要检查应用程序提交的确切 SQL 语句,以及应用程序在查询取消、连接管理、提取所有结果行等方面的确切行为。 如果开发工具不允许对连接管理、查询取消、查询超时、结果提取等进行显式控制,则阻塞问题可能无法解决。 在为 SQL Server 选择应用程序开发工具之前,应仔细研究这种可能性,尤其是对于性能敏感的 OLTP 环境。
在数据库和应用程序的设计和构造阶段,请注意数据库性能。 特别是,应针对每个查询评估资源使用量、隔离级别和事务路径长度。 每个查询和事务都应尽可能是轻量级查询和事务。 必须执行良好的连接管理规则,如果没有它,应用程序在用户数较少的情况下其性能虽可接受,但随着用户数增加,性能可能会显著下降。
通过适当的应用程序和查询设计,SQL Server 能够在一台服务器上同时支持数千个用户,并且几乎没有阻塞。
对阻塞问题进行疑难解答
无论遇到哪种阻塞情况,对阻塞问题的疑难解答方法都是相同的。 这些逻辑分离适用于本文的其余部分内容。 理念是查找队头阻止程序并确定该查询正在执行的操作以及它阻止的原因。 一旦识别出有问题的查询(即是什么长时间持有锁),下一步是分析并确定阻塞发生的原因。 弄清楚原因后,就可以通过重新设计查询和事务做出更改。
疑难解答步骤:
- 识别主阻塞会话(队头阻止程序)
- 查找导致阻塞的查询和事务(是什么长时间持有锁)
- 分析/理解发生长时间阻塞的原因
- 通过重新设计查询和事务来解决阻塞问题
现在,让我们深入探讨如何通过相应的数据捕获来精确定位主阻塞会话。
收集阻塞信息
为了降低对阻塞问题进行疑难解答的难度,数据库管理员可以使用 SQL 脚本持续监视 SQL Server 上的锁定和阻塞状态。 要收集此数据,有两种免费方法。
第一种是查询动态管理对象 (DMO) 并存储结果,以便日后进行比较。 本文中引用的某些对象是动态管理视图 (DMV),有些是动态管理函数 (DMF)。
第二种是使用扩展事件 (XEvents) 或 SQL 探查器跟踪来捕获正在执行的内容。 由于 SQL 跟踪和 SQL Server 探查器已弃用,因此本疑难解答指南将重点介绍 XEvents。
收集来自 DMV 的信息
引用 DMV 来对阻塞问题进行疑难解答旨在识别阻塞链和 SQL 语句头部的 SPID(会话 ID)。 查找被阻塞的受害者 SPID。 如果任何 SPID 被另一个 SPID 阻塞,则调查拥有该资源的 SPID(阻塞 SPID)。 该所有者 SPID 是否也被阻塞? 可以浏览阻塞链以查找头部阻止程序,然后调查其保持锁定的原因。
为此,可以使用下列方法之一:
- 在 SQL Server Management Studio (SSMS) “对象资源管理器”中,右键单击顶级服务器对象,依次展开“报表”、“标准报表”,然后选择“活动 - 所有阻塞事务”。 此报表显示阻塞链头的当前事务。 如果展开事务,报表将显示被头部事务阻止的事务。 此报表还将显示“阻塞中的 SQL 语句”和“已阻塞的 SQL 语句”。
- 在 SSMS 中打开“活动监视器”,并引用“发起阻止方”列。 在此处查找有关活动监视器的详细信息。
通过 DMV 还可获取更详细的基于查询的方法:
sp_who命令和sp_who2命令是显示所有当前会话的较旧命令。 DMVsys.dm_exec_sessions在更易于查询和筛选的结果集中返回更多数据。 将在其他查询的核心中找到sys.dm_exec_sessions。- 如果已标识特定会话,则可以使用
DBCC INPUTBUFFER(<session_id>)来查找会话提交的最后一个语句。 在更易于查询和筛选的结果集中,可以使用sys.dm_exec_input_buffer动态管理函数 (DMF) 返回类似的结果,从而提供 session_id 和 request_id。 例如,要返回由 session_id 66 和 request_id 0 提交的最新查询:
SQL
1 | SELECT * FROM sys.dm_exec_input_buffer (66,0); |
- 请参阅
sys.dm_exec_requests并引用blocking_session_id列。 当blocking_session_id= 0 时,会话不会被阻止。 虽然sys.dm_exec_requests仅列出当前正在执行的请求,但任何连接(无论是否活动)都将列在sys.dm_exec_sessions中。 在下一个查询的sys.dm_exec_requests和sys.dm_exec_sessions之间构建此通用联接。 请记住,要通过sys.dm_exec_requests返回,查询必须使用 SQL Server 主动执行。 - 运行此示例查询,使用 sys.dm_exec_sql_text 或 sys.dm_exec_input_buffer DMV 查找主动执行的查询及其当前 SQL 批文本或输入缓冲区文本。 如果
sys.dm_exec_sql_text的text列返回的数据为 NULL,则当前未执行查询。 在这种情况下,sys.dm_exec_input_buffer的event_info列将包含传递给 SQL 引擎的最后一个命令字符串。 此查询还可用于标识阻止其他会话的会话,包括每个 session_id 阻止的 session_ids 列表。
SQL
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | WITH cteBL (session_id, blocking_these) AS (SELECT s.session_id, blocking_these = x.blocking_these FROM sys.dm_exec_sessions s CROSS APPLY (SELECT isnull(convert(varchar(6), er.session_id),'') + ', ' FROM sys.dm_exec_requests as er WHERE er.blocking_session_id = isnull(s.session_id ,0) AND er.blocking_session_id <> 0 FOR XML PATH('') ) AS x (blocking_these) ) SELECT s.session_id, blocked_by = r.blocking_session_id, bl.blocking_these , batch_text = t.text, input_buffer = ib.event_info, * FROM sys.dm_exec_sessions s LEFT OUTER JOIN sys.dm_exec_requests r on r.session_id = s.session_id INNER JOIN cteBL as bl on s.session_id = bl.session_id OUTER APPLY sys.dm_exec_sql_text (r.sql_handle) t OUTER APPLY sys.dm_exec_input_buffer(s.session_id, NULL) AS ib WHERE blocking_these is not null or r.blocking_session_id > 0 ORDER BY len(bl.blocking_these) desc, r.blocking_session_id desc, r.session_id; |
- 运行 Microsoft 支持部门提供的更详细的示例查询,以识别多个会话阻塞链的头部,包括阻塞链中涉及的会话的查询文本。
SQL
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 | WITH cteHead ( session_id,request_id,wait_type,wait_resource,last_wait_type,is_user_process,request_cpu_time ,request_logical_reads,request_reads,request_writes,wait_time,blocking_session_id,memory_usage ,session_cpu_time,session_reads,session_writes,session_logical_reads ,percent_complete,est_completion_time,request_start_time,request_status,command ,plan_handle,sql_handle,statement_start_offset,statement_end_offset,most_recent_sql_handle ,session_status,group_id,query_hash,query_plan_hash) AS ( SELECT sess.session_id, req.request_id, LEFT (ISNULL (req.wait_type, ''), 50) AS 'wait_type' , LEFT (ISNULL (req.wait_resource, ''), 40) AS 'wait_resource', LEFT (req.last_wait_type, 50) AS 'last_wait_type' , sess.is_user_process, req.cpu_time AS 'request_cpu_time', req.logical_reads AS 'request_logical_reads' , req.reads AS 'request_reads', req.writes AS 'request_writes', req.wait_time, req.blocking_session_id,sess.memory_usage , sess.cpu_time AS 'session_cpu_time', sess.reads AS 'session_reads', sess.writes AS 'session_writes', sess.logical_reads AS 'session_logical_reads' , CONVERT (decimal(5,2), req.percent_complete) AS 'percent_complete', req.estimated_completion_time AS 'est_completion_time' , req.start_time AS 'request_start_time', LEFT (req.status, 15) AS 'request_status', req.command , req.plan_handle, req.[sql_handle], req.statement_start_offset, req.statement_end_offset, conn.most_recent_sql_handle , LEFT (sess.status, 15) AS 'session_status', sess.group_id, req.query_hash, req.query_plan_hash FROM sys.dm_exec_sessions AS sess LEFT OUTER JOIN sys.dm_exec_requests AS req ON sess.session_id = req.session_id LEFT OUTER JOIN sys.dm_exec_connections AS conn on conn.session_id = sess.session_id ) , cteBlockingHierarchy (head_blocker_session_id, session_id, blocking_session_id, wait_type, wait_duration_ms, wait_resource, statement_start_offset, statement_end_offset, plan_handle, sql_handle, most_recent_sql_handle, [Level]) AS ( SELECT head.session_id AS head_blocker_session_id, head.session_id AS session_id, head.blocking_session_id , head.wait_type, head.wait_time, head.wait_resource, head.statement_start_offset, head.statement_end_offset , head.plan_handle, head.sql_handle, head.most_recent_sql_handle, 0 AS [Level] FROM cteHead AS head WHERE (head.blocking_session_id IS NULL OR head.blocking_session_id = 0) AND head.session_id IN (SELECT DISTINCT blocking_session_id FROM cteHead WHERE blocking_session_id != 0) UNION ALL SELECT h.head_blocker_session_id, blocked.session_id, blocked.blocking_session_id, blocked.wait_type, blocked.wait_time, blocked.wait_resource, h.statement_start_offset, h.statement_end_offset, h.plan_handle, h.sql_handle, h.most_recent_sql_handle, [Level] + 1 FROM cteHead AS blocked INNER JOIN cteBlockingHierarchy AS h ON h.session_id = blocked.blocking_session_id and h.session_id!=blocked.session_id --avoid infinite recursion for latch type of blocking WHERE h.wait_type COLLATE Latin1_General_BIN NOT IN ('EXCHANGE', 'CXPACKET') or h.wait_type is null ) SELECT bh.*, txt.text AS blocker_query_or_most_recent_query FROM cteBlockingHierarchy AS bh OUTER APPLY sys.dm_exec_sql_text (ISNULL ([sql_handle], most_recent_sql_handle)) AS txt; |
- 若要捕获长时间运行或未提交的事务,请使用另一组 DMV 来查看当前打开的事务,包括 sys.dm_tran_database_transactions、 sys.dm_tran_session_transactions、 sys.dm_exec_connections 和
sys.dm_exec_sql_text有几个 DMV 与跟踪事务相关联,要了解更多,请参阅此处的事务 DMV。
SQL
1 2 3 4 5 6 7 8 | SELECT [s_tst].[session_id], [database_name] = DB_NAME (s_tdt.database_id), [s_tdt].[database_transaction_begin_time], [sql_text] = [s_est].[text] FROM sys.dm_tran_database_transactions [s_tdt] INNER JOIN sys.dm_tran_session_transactions [s_tst] ON [s_tst].[transaction_id] = [s_tdt].[transaction_id] INNER JOIN sys.dm_exec_connections [s_ec] ON [s_ec].[session_id] = [s_tst].[session_id] CROSS APPLY sys.dm_exec_sql_text ([s_ec].[most_recent_sql_handle]) AS [s_est]; |
引用 sys.dm_os_waiting_tasks 位于 SQL Server 线程/任务层。 这会返回有关请求当前遇到的 SQL wait_type 的信息。 例如
sys.dm_exec_requests,只有活动请求才由其返回sys.dm_os_waiting_tasks。备注
要了解更多有关等待类型(包括一段时间内聚合的等待统计信息)的详细信息,请参阅 DMV sys.dm_db_wait_stats
- 使用sys.dm_tran_locks DMV,获取有关查询放置了哪些锁定的更多详细信息。 此 DMV 可以返回产品 SQL Server 实例上的大量数据,并且可用于诊断当前保存的锁定。
由于存在内联sys.dm_os_waiting_tasks,以下查询将输出限制为sys.dm_tran_locks仅限于当前被阻止的请求、等待状态及其锁定:
SQL
1 2 3 4 5 6 7 8 9 | SELECT table_name = schema_name(o.schema_id) + '.' + o.name , wt.wait_duration_ms, wt.wait_type, wt.blocking_session_id, wt.resource_description , tm.resource_type, tm.request_status, tm.request_mode, tm.request_session_id FROM sys.dm_tran_locks AS tm INNER JOIN sys.dm_os_waiting_tasks as wt ON tm.lock_owner_address = wt.resource_address LEFT OUTER JOIN sys.partitions AS p on p.hobt_id = tm.resource_associated_entity_id LEFT OUTER JOIN sys.objects o on o.object_id = p.object_id or tm.resource_associated_entity_id = o.object_id WHERE resource_database_id = DB_ID() AND object_name(p.object_id) = '<table_name>'; |
借助 DMV,随时间推移存储查询结果将提供数据点,使您能够在指定的时间间隔内查看阻塞,以确定持久阻塞或趋势。 CSS 排查此类问题的导航工具是使用 PSSDiag 数据收集器。 此工具使用“SQL Server Perf 统计信息”随时间从上面引用的 DMV 收集结果集。 由于此工具不断发展,请查看 GitHub 上 DiagManager 的最新公共版本。
从扩展事件收集信息
除了上述信息,通常还需要捕获服务器上活动的跟踪,以彻底调查 SQL Server 中的阻塞问题。 例如,如果会话在事务中执行多个语句,则只会显示提交的最后一个语句。 但是,前面的陈述之一可能是锁定仍未解除的原因之一。 通过跟踪,可以查看当前事务中会话执行的所有命令。
可通过两种方法在 SQL Server 中捕获跟踪:扩展事件 (XEvents)和 Profiler 跟踪。 但是,使用 SQL Server Profiler 的 SQL跟踪已弃用。 XEvents 是一种更新的、卓越的跟踪平台,它的功能性更强,对观测系统的影响更小,并且其界面已集成到 SSMS 中。
预先制作的扩展事件会话已准备好在 SSMS 启动,在 XEvent Profiler 菜单下的对象资源管理器中列出。 要了解更多详细信息,请参阅 XEvent Profiler。 还可以在 SSMS 中创建自己的自定义扩展事件会话,请参阅扩展事件新会话向导。 若要排查阻塞问题,我们通常会捕获:
- 类别错误:
- 注意
- Blocked_process_report**
- Error_reported(通道管理员)
- Exchange_spill
- Execution_warning
**若要配置生成阻塞进程报告的阈值和频率,请使用 sp_configure 命令配置阻塞进程阈值选项,该选项可在几秒内设置完成。 默认情况下,不会生成阻塞的进程报告。
- 类别警告:
- Hash_warning
- Missing_column_statistics
- Missing_join_predicate
- Sort_warning
- 类别执行:
- Rpc_completed
- Rpc_starting
- Sql_batch_completed
- Sql_batch_starting
- 类别锁定
- Lock_deadlock
- 类别会话
- Existing_connection
- 登录
- 注销
识别并解决常见的阻塞场景
通过检查上述信息,可以确定大多数阻塞问题的原因。 本文的其余部分介绍如何使用此信息来识别和解决一些常见的阻塞场景。 本讨论假定已使用阻塞脚本(此前已引用)来捕获有关阻塞 SPID 的信息,并已使用 XEvent 会话捕获应用程序活动。
分析阻塞数据
使用
blocking_these和session_id检查 DMVsys.dm_exec_requests和sys.dm_exec_sessions的输出,以确定阻塞链的头部。 这将最清楚地识别哪些请求被阻止,哪些请求正在被阻止。 进一步查看被阻止和正在被阻止的会话。 阻塞链是否有共同点或根? 它们可能共享一个公用表,且阻塞链中涉及的一个或多个会话正在执行写入操作。检查 DMV
sys.dm_exec_requests和sys.dm_exec_sessions的输出以获取阻塞链头部有关 SPID 的信息。 查找以下列:sys.dm_exec_requests.status
此列显示特定请求的状态。 通常,休眠状态指示 SPID 已完成执行,正在等待应用程序提交另一个查询或批处理。 可运行或正在运行的状态指示 SPID 当前正在处理查询。 下表简要介绍了各种状态值。
状态 含义 背景 SPID 正在运行后台任务,例如死锁检测、日志编写器或检查点。 休眠 SPID 当前未执行。 这通常指示 SPID 正在等待来自应用程序的命令。 正在运行 SPID 当前在计划程序上运行。 可运行 SPID 位于计划程序的可运行队列中,等待获取计划程序时间。 已暂停 SPID 正在等待资源,例如锁或闩锁。 sys.dm_exec_sessions.open_transaction_count
此列告知此会话中的打开的事务数。 如果此值大于 0,则 SPID 位于打开的事务中,并且可能持有事务中任何语句获取的锁。sys.dm_exec_requests.open_transaction_count
同样,此列告知此请求中打开的事务数。 如果此值大于 0,则 SPID 位于打开的事务中,并且可能持有事务中任何语句获取的锁。sys.dm_exec_requests.wait_type、wait_time和last_wait_type
如果sys.dm_exec_requests.wait_type为 NULL,则请求当前未等待任何内容,并且last_wait_type值指示请求遇到的最后一个wait_type。 有关sys.dm_os_wait_stats的详细信息以及最常见等待类型的说明,请参阅 sys.dm_os_wait_stats。wait_time值可用于确定请求是否正在进行。 当针对sys.dm_exec_requests表的查询返回wait_time列中的值小于此前查询sys.dm_exec_requests的wait_time值时,这指示已获取并释放之前的锁,现在正在等待新的锁(假定非零wait_time)。 可以通过比较wait_resource和sys.dm_exec_requests之间的输出来验证这一点,该输出显示请求正在等待的资源。sys.dm_exec_requests.wait_resource此列指示阻止的请求正在等待的资源。 下表列出了常见wait_resource格式及其含义:
Resource 格式 示例 解释 表格 DatabaseID:ObjectID:IndexID TAB: 5:261575970:1 在此案例中,数据库 ID 5 是 pubs 示例数据库, object_id261575970 是标题表,而 1 是聚集索引。Page DatabaseID:FileID:PageID PAGE: 5:1:104 在此案例中,数据库 ID 5 为 pubs,文件 ID 1 是主数据文件,而第 104 页是属于标题表的页面。 要标识页面所属的 object_id,请使用动态管理函数 sys.dm_db_page_info,从 wait_resource中传入 DatabaseID、FileId、PageId。键 DatabaseID:Hobt_id(索引键的哈希值) 键:5:72057594044284928 (3300a4f361aa) 在此案例中,数据库 ID 5 为 Pubs,Hobt_ID 72057594044284928 对应于 object_id 261575970(标题表)的 index_id 2。 使用 sys.partitions目录视图将hobt_id关联到特定index_id和object_id。 无法将索引键哈希解哈希为特定键值。Row DatabaseID:FileID:PageID:Slot(row) RID: 5:1:104:3 在此案例中,数据库 ID 5 为 pubs,文件 ID 1 是主数据文件,第 104 页是属于标题表的页面,而插槽 3 指示该行在页面上的位置。 编译 DatabaseID:FileID:PageID:Slot(row) RID: 5:1:104:3 在此案例中,数据库 ID 5 为 pubs,文件 ID 1 是主数据文件,第 104 页是属于标题表的页面,而插槽 3 指示该行在页面上的位置。 sys.dm_tran_active_transactionssys.dm_tran_active_transactions DMV 包含有关打开事务的数据,这些事务可以加入其他 DMV,以获取等待提交或回滚事务的完整信息。 使用以下查询返回有关已加入其他 DMV(包括sys.dm_tran_session_transactions)的打开事务的信息。 考虑事务的当前状态、transaction_begin_time和其他情况数据,以评估其是否可能是阻塞源。
SQL
123456789101112131415161718192021222324252627SELECT tst.session_id, [database_name] = db_name(s.database_id), tat.transaction_begin_time, transaction_duration_s = datediff(s, tat.transaction_begin_time, sysdatetime()), transaction_type = CASE tat.transaction_type WHEN 1 THEN 'Read/write transaction'WHEN 2 THEN 'Read-only transaction'WHEN 3 THEN 'System transaction'WHEN 4 THEN 'Distributed transaction' END, input_buffer = ib.event_info, tat.transaction_uow, transaction_state = CASE tat.transaction_stateWHEN 0 THEN 'The transaction has not been completely initialized yet.'WHEN 1 THEN 'The transaction has been initialized but has not started.'WHEN 2 THEN 'The transaction is active - has not been committed or rolled back.'WHEN 3 THEN 'The transaction has ended. This is used for read-only transactions.'WHEN 4 THEN 'The commit process has been initiated on the distributed transaction.'WHEN 5 THEN 'The transaction is in a prepared state and waiting resolution.'WHEN 6 THEN 'The transaction has been committed.'WHEN 7 THEN 'The transaction is being rolled back.'WHEN 8 THEN 'The transaction has been rolled back.' END, transaction_name = tat.name, request_status = r.status, tst.is_user_transaction, tst.is_local, session_open_transaction_count = tst.open_transaction_count, s.host_name, s.program_name, s.client_interface_name, s.login_name, s.is_user_processFROM sys.dm_tran_active_transactions tatINNER JOIN sys.dm_tran_session_transactions tst on tat.transaction_id = tst.transaction_idINNER JOIN Sys.dm_exec_sessions s on s.session_id = tst.session_idLEFT OUTER JOIN sys.dm_exec_requests r on r.session_id = s.session_idCROSS APPLY sys.dm_exec_input_buffer(s.session_id, null) AS ib;- 其他列
通过 sys.dm_exec_sessions 和 sys.dm_exec_request 中的其余列也可以深入了解问题的根源。 它们的用处因问题的具体情况而异。 例如,可以确定问题是否仅发生在某些客户端 (
hostname)、某些网络库 (client_interface_name)、SPID 提交的最后批处理何时在sys.dm_exec_sessions中被last_request_start_time、请求通过sys.dm_exec_requests中的start_time的运行时间等。
常见的阻塞场景
下表将常见症状映射到其可能的原因。
wait_type、open_transaction_count 和 status 列是指由 sys.dm_exec_request 返回的信息,而其他列可能由 sys.dm_exec_sessions 返回。 “解决?”列指示阻止是否自行解决,或者是否应通过 KILL 命令终止会话。 有关详细信息,请参阅 KILL (Transact-SQL)。
| 应用场景 | Wait_type | Open_Tran | 状态 | 解析? | 其他症状 |
|---|---|---|---|---|---|
| 1 | 非 NULL | >= 0 | 可运行 | 是,查询完成时。 | 在 sys.dm_exec_sessions、 reads、 cpu_time 和/或 memory_usage 中,列会随时间推移而增加。 完成查询时,查询的持续时间会很长。 |
| 2 | NULL | >0 | 休眠 | 不, 但 SPID 可以终止。 | 此 SPID 的“扩展事件”会话中可能会显示注意信号,指示查询超时或已取消。 |
| 3 | NULL | >= 0 | 可运行 | 不需要。 在客户端提取所有行或关闭连接之前,不会进行解析。 SPID 可以被终止,但可能需要长达 30 秒的时间。 | 如果 open_transaction_count = 0,并且 SPID 在事务隔离级别为默认值 (READ COMMITTED) 时保持锁定,则这可能是一个原因。 |
| 4 | 各不相同 | >= 0 | 可运行 | 不需要。 在客户端取消查询或关闭连接之前,不会进行解析。 SPID 可以被终止,但可能需要长达 30 秒的时间。 | 阻塞链头部的 SPID 在 sys.dm_exec_sessions 中的 hostname 列将与它所阻止的 SPID 之一相同。 |
| 5 | NULL | >0 | 回滚 | 是。 | 此 SPID 的扩展事件会话中可能会显示注意信号,表明发生了查询超时或取消,或者只是发布了回滚语句。 |
| 6 | NULL | >0 | 休眠 | 最终。 当 Windows NT 确定会话不再活动时,连接将断开。 | sys.dm_exec_sessions 中的 last_request_start_time 值比当前时间要早得多。 |
详细的阻止方案
方案 1:由正常运行的查询导致的阻塞,执行时间较长
在此方案中,主动运行的查询已获取锁,并且未释放锁(受事务隔离级别的影响)。 因此,其他会话将等待锁,直到它们被释放。
解决方法:
解决此类阻塞问题的方法是寻找优化查询的方法。 此类阻塞问题可能是性能问题,需要你根据这种情况进行操作。 有关对特定运行缓慢的查询进行故障排除的信息,请参阅如何对 SQL Server 上运行缓慢的查询进行故障排除。 有关详细信息,请参阅监视和优化性能。
来自“查询存储”的 SSMS 内置报表(在 SQL Server 2016 中引入)也是一种强烈推荐且宝贵的工具,可用于识别代价最高昂的查询和不理想的执行计划。
如果有一个长期运行的查询阻止其他用户且无法对其进行优化,请考虑将其从 OLTP 环境移动到专用报告系统。 还可以使用 Always On 可用性组同步“数据库的只读副本”。
备注
查询执行期间的阻塞可能是由查询升级引起的,这种情况下行锁定或页锁定升级到表锁定。 Microsoft SQL Server 会动态确定何时执行锁升级。 防止锁升级的最简单和最安全的方法是保持事务简短,并减少昂贵查询的锁占用量,以免超过锁升级阈值。 有关检测和防止过度锁升级的详细信息,请参阅解决锁升级导致的阻塞问题。
方案 2:由具有未提交的事务的休眠 SPID 导致的阻塞
这种类型的阻塞通常可以通过正在休眠或等待事务嵌套级别(@@TRANCOUNT,来自 sys.dm_exec_requests 的 open_transaction_count)大于零的命令的 SPID 来识别。 如果应用程序遇到查询超时,或者发出取消语句的同时没有发出所需的 ROLLBACK 和/或 COMMIT 语句数,则可能会发生这种情况。 当 SPID 收到查询超时或取消时,它将终止当前查询和批处理,但不会自动回滚或提交事务。 应用程序对此负有责任,因为 SQL Server 不能假定由于单个查询被取消而必须回滚整个事务。 查询超时或取消将在扩展事件会话中显示为 SPID 的注意信号事件。
若要演示未提交的显式事务,请发出以下查询:
SQL
1 2 3 4 5 | CREATE TABLE #test (col1 INT); INSERT INTO #test SELECT 1; GO BEGIN TRAN UPDATE #test SET col1 = 2 where col1 = 1; |
然后,在同一窗口中执行此查询:
SQL
1 2 3 | SELECT @@TRANCOUNT; ROLLBACK TRAN DROP TABLE #test; |
第二个查询的输出结果表明,事务计数为 1。 在提交或回滚事务之前,仍会持有在事务中获取的所有锁。 如果应用程序显式打开并提交事务,则通信或其他错误可能会使会话及其事务处于打开状态。
使用本文前面基于 sys.dm_tran_active_transactions 的脚本来识别实例中当前未提交的事务。
解决方案:
- 此外,此类阻塞问题也可能是性能问题,需要你执行这样的操作。 如果可以缩短查询执行时间,则不会出现查询超时或取消的情况。 应用程序要能够处理超时或取消的情况(如果出现),这点很重要,但你也可以从检查查询的性能中获益。
应用程序必须正确管理事务嵌套级别,否则可能会在以这种方式取消查询后导致阻塞问题。 比如以下几种情况:
- 在客户端应用程序的错误处理程序中,在出现任何错误后执行
IF @@TRANCOUNT > 0 ROLLBACK TRAN,即使客户端应用程序不相信某个事务已打开。 需要检查打开的事务,因为批处理期间调用的存储过程可能在客户端应用程序不知情的情况下启动事务。 某些条件(例如取消查询)会阻止该过程越过当前语句执行,因此即使该过程具有检查IF @@ERROR <> 0和中止事务的逻辑,在这种情况下也不会执行此回滚代码。 - 如果在打开连接的应用程序中使用连接池,并在将连接释放回池之前运行一些查询(例如基于 Web 的应用程序),则暂时禁用连接池可能有助于缓解问题,直到修改客户端应用程序以适当地处理错误。 通过禁用连接池,释放连接将导致物理断开 SQL Server 连接,从而导致服务器回滚所有打开的事务。
- 将
SET XACT_ABORT ON用于连接,或用于在任何开始事务且未在错误后进行清理的存储过程。 如果出现运行时错误,此设置将中止任何打开的事务,并将控制权返回给客户端。 有关详细信息,请查看设置 XACT_ABORT (Transact-SQL)。
备注
- 在客户端应用程序的错误处理程序中,在出现任何错误后执行
连接在从连接池重复使用之前不会重置,因此用户可以打开事务,然后释放与连接池的连接,但在几秒之内可能不会重复使用,在此期间事务将保持打开状态。 如果未重复使用连接,则当连接超时并从连接池中删除时,事务将中止。 因此,客户端应用程序最好中止其错误处理程序中的事务,或使用 SET XACT_ABORT ON 来避免这种潜在的延迟。
注意
在 SET XACT_ABORT ON 之后,不会执行导致错误的语句之后的 T-SQL 语句。 这可能会影响现有代码的预期流。
方案 3:由 SPID 导致的阻塞,其相应的客户端应用程序未提取所有结果行直至完成
将查询发送到服务器后,所有应用程序必须立即提取所有结果行才能完成。 如果应用程序未提取所有结果行,则锁可能会停留在表上,从而阻止其他用户。 如果使用的应用程序以透明方式将 SQL 语句提交到服务器,则应用程序必须提取所有结果行。 如果没有提取所有结果行(并且无法将其配置为执行此操作),则可能无法解决阻塞问题。 为避免出现此问题,可以将行为不佳的应用程序限制为报表或决策支持数据库(独立于主 OLTP 数据库)。
解决方法:
必须重写应用程序才能提取所有结果行直至完成。 这不排除在查询的 ORDER BY 子句中使用 OFFSET 和 FETCH 来执行服务器端分页。
方案 4:由分布式客户端/服务器死锁导致的阻塞
与传统的死锁不同,使用 RDBMS 锁定管理器无法检测分布式死锁。 这是因为死锁中涉及的资源只有一个是 SQL Server 锁。 死锁的另一端处于客户端应用程序级别,SQL Server 对此没有控制权。 下面两个示例说明如何执行此操作,以及应用程序可以避免这种情况的可能方法。
示例 A:具有单一客户端线程的客户端/服务器分布式死锁
如果客户端有多个打开的连接和单个执行线程,则可能会出现以下分布式死锁。 注意,此处使用的术语 dbproc 指的是客户端连接结构。
控制台
1 2 3 4 5 6 7 8 9 10 11 | SPID1------blocked on lock------->SPID2 /\ (waiting to write results back to client) | | | | | Server side | ================================|================================== | <-- single thread --> | Client side | \/ dbproc1 <------------------- dbproc2 (waiting to fetch (effectively blocked on dbproc1, awaiting next row) single thread of execution to run) |
在上面所示案例中,单一客户端应用程序线程有两个打开的连接。 它在 dbproc1 上异步提交 SQL 操作。 这意味着它不会等待调用返回,然后再继续。 然后,应用程序在 dbproc2 上提交另一个 SQL 操作,并等待结果以开始处理返回的数据。 当数据开始返回(以最先响应的 dbproc 为准--假定是 dbproc1),它将处理完在该 dbproc 上返回的所有数据。 它从 dbproc1 提取结果,直到 SPID1 被 SPID2 持有的锁阻塞(因为这两个查询在服务器上异步运行)。 此时,dbproc1 将无限期地等待更多数据。 不会在锁上阻止 SPID2,而是尝试将数据发送到其客户端 dbproc2。 但是,dbproc2 在应用程序层的 dbproc1 上被有效阻止,因为 dbproc1 正在使用应用程序的单个执行线程。 这会导致死锁,同时 SQL Server 无法检测或解析,因为所涉及的资源中只有一个是 SQL Server 资源。
示例 B:客户端/服务器分布式死锁(每个连接都有一个线程)
即使客户端上每个连接都存在单独的线程,此分布式死锁的变体也可能仍会出现,如下所示。
控制台
1 2 3 4 5 6 7 8 9 10 11 | SPID1------blocked on lock-------->SPID2 /\ (waiting on net write) Server side | | | | | INSERT |SELECT | ================================|================================== | <-- thread per dbproc --> | Client side | \/ dbproc1 <-----data row------- dbproc2 (waiting on (blocked on dbproc1, waiting for it insert) to read the row from its buffer) |
这种情况类似于示例 A,不同的是 dbproc2 和 SPID2 正在运行 SELECT 语句,以便执行行处理(一次一行),并通过缓冲区将每行传递给 dbproc1,以获取同一表上的 INSERT、UPDATE 或 DELETE 语句。 最终,SPID1(执行 INSERT、UPDATE 或 DELETE)被 SPID2 持有的锁阻塞(执行 SELECT)。 SPID2 将结果行写入客户端 dbproc2。 然后,Dbproc2 尝试将缓冲区中的行传递到 dbproc1,但发现 dbproc1 正忙(它在等待 SPID1 完成当前在 SPID2 上被阻塞的 INSERT 时被阻塞)。 此时,dbproc2 在应用程序层被 dbproc1 阻塞,而 dbproc1 的 SPID (SPID1) 在数据库级别被 SPID2 阻塞。 同样,这会导致死锁,同时 SQL Server 无法检测或解析,因为所涉及资源中只有一个是 SQL Server 资源。
A 和 B 这两个示例都是应用程序开发人员必须注意的基本问题。 他们必须对应用程序进行代码编码,以便正确处理这些情况。
解决方法:
提供查询超时后,如果发生分布式死锁,则在超时时会中断。 有关使用查询超时的详细信息,请参阅连接提供程序文档。
方案 5:由处于回滚状态的会话导致的阻塞
在用户定义的事务之外终止或取消的数据修改查询将回滚。 出现这种情况可能是客户端网络会话断开连接的副作用,或者选择请求作为死锁受害者。 这通常可以通过观察 sys.dm_exec_requests 的输出来识别,它可能指示回滚 command,并且 percent_complete 列可能会显示进度。
在用户定义的事务之外终止或取消的数据修改查询将回滚。 出现这种情况也可能是客户端计算机重启及其网络会话断开连接的副作用。 同样,被选为死锁受害者的查询也会回滚。 数据修改查询的回滚速度通常不能比最初应用更改的速度更快。 例如,如果 DELETE、INSERT 或 UPDATE 语句已运行一小时,则至少可能需要一个小时才能回滚。 这是预期的行为,因为必须回滚所做的更改,否则数据库中的事务和物理完整性将受到损害。 由于必须执行此操作,SQL Server 将 SPID 标记为黄金或回滚状态(这意味着它不能被终止或选为死锁受害者)。 这通常可以通过观察 sp_who 的输出来识别,这可能指示 ROLLBACK 命令。 sys.dm_exec_sessions 的 status 将指示 ROLLBACK 状态。
备注
启用“加速数据库恢复功能”时,很少出现冗长回滚。 此功能已在 SQL Server 2019 中推出。
解决方法:
必须等待会话完成回滚所做的更改。
如果实例在此操作过程中关闭,则数据库在重启时将处于恢复模式,并且在处理所有打开的事务之前将无法访问它。 启动恢复每个事务所用的时间与运行时恢复的时间基本相同,在此期间数据库不可访问。 因此,强制服务器关闭以修复处于回滚状态的 SPID 通常会适得其反。 在启用了“加速数据库恢复”的 2019 SQL Server 中,不应发生这种情况。
要避免这种情况,请勿在 OLTP 系统繁忙期间执行大型批处理写入操作或索引创建或维护操作。 如果可能,请在低活动量期间执行此类操作。
方案 6:孤立事务导致的阻塞
这是一个常见的问题方案,部分与方案 2重叠。 如果客户端应用程序停止、客户端工作站重启或出现批量中止错误,这些都可能会使事务保持打开状态。 如果应用程序未回滚应用程序 CATCH 或 FINALLY 阻止中的事务,或者未处理这种情况,则可能会出现这种情况。
在这种情况下,虽然已取消执行 SQL 批处理,但应用程序会保持 SQL 事务的打开状态。 从 SQL Server 实例的角度来看,客户端似乎仍然存在,获取的任何锁仍会保留。
若要演示孤立事务,请执行以下查询,该查询通过将数据插入不存在的表来模拟批量中止错误:
SQL
1 2 3 4 5 6 | CREATE TABLE #test2 (col1 INT); INSERT INTO #test2 SELECT 1; go BEGIN TRAN UPDATE #test2 SET col1 = 2 where col1 = 1; INSERT INTO #NonExistentTable values (10) |
然后,在同一窗口中执行此查询:
SQL
1 | SELECT @@TRANCOUNT; |
第二个查询的输出结果表明,事务计数为 1。 在提交或回滚事务之前,仍会持有在事务中获取的所有锁。 由于该批处理已被查询中止,因此执行该批处理的应用程序可能会继续在同一会话上运行其他查询,而无需清理仍处于打开状态的事务。 锁定将一直保留到会话终止或重启 SQL Server 实例。
解决方案:
- 防止这种情况的最佳方法是改进应用程序错误/异常处理方式,尤其是针对意外终止的情况。 确保在应用程序代码中使用
Try-Catch-Finally块,并在出现异常时回滚事务。 - 考虑将
SET XACT_ABORT ON用于会话,或用于在任何开始事务且未在错误后进行清理的存储过程。 如果出现中断批处理的运行时错误,此设置将自动回滚所有打开的事务,并将控制权返回给客户端。 有关详细信息,请查看设置 XACT_ABORT (Transact-SQL)。 - 要解析已断开连接但未适当清理其资源的客户端应用程序的孤立连接,可以使用
KILL命令终止 SPID。 有关参考,请参阅 KILL (Transact-SQL)。
KILL 命令将 SPID 值作为输入。 例如,要终止 SPID 9,请运行以下命令:
SQL
1 | KILL 99 |
备注
由于检查 KILL 命令存在时间间隔,因此,KILL 命令最多可能需要 30 秒才能完成。
解决SQL Server中锁升级导致的阻塞问题
摘要
锁升级是将许多细粒度锁 ((如行锁或页锁) 转换为表锁)的过程。 Microsoft SQL Server动态确定何时执行锁升级。 做出此决定时,SQL Server会考虑在特定扫描中持有的锁数、整个事务持有的锁数,以及整个系统中用于锁的内存。 通常,SQL Server的默认行为会导致锁升级仅在提高性能或必须将过多的系统锁内存减少到更合理的级别时发生。 但是,某些应用程序或查询设计可能会在不需要执行此操作时触发锁升级,并且升级的表锁可能会阻止其他用户。 本文讨论如何确定锁升级是否导致阻塞,以及如何处理不需要的锁升级。
原始产品版本:SQL Server
原始 KB 编号: 323630
确定锁升级是否导致阻塞
锁升级不会导致大多数阻塞性问题。 若要确定锁定升级是在遇到阻塞问题时还是接近时发生,请启动包含该 lock_escalation 事件的扩展事件会话。 如果未看到任何 lock_escalation 事件,则服务器上不会发生锁升级,并且本文中的信息不适用于你的情况。
如果发生锁升级,请验证升级的表锁是否正在阻止其他用户。
有关如何识别头阻止程序和头阻止程序持有的锁资源以及阻止其他服务器进程 ID (SPID) 的详细信息,请参阅 INF:了解和解决SQL Server阻塞问题。
如果阻止其他用户的锁不是 TAB (表级) 锁,其锁定模式为 S (共享) 或 X (独占) ,则锁升级不是问题。 特别是,如果 TAB 锁是意向锁 ((如 IS、IU 或 IX) 的锁定模式),则这不是由锁升级引起的。 如果阻止问题不是由锁升级引起的,请参阅 INF:了解和解决SQL Server阻塞问题故障排除步骤。
防止锁升级
防止锁定升级的最简单、最安全的方法是使事务保持较短,并减少昂贵查询的锁占用量,以便不会超过锁升级阈值。 可通过多种方法实现此目标,包括以下策略:
将大型批处理操作分解为多个较小的操作。 例如,运行以下查询以从审核表中删除 100,000 多条旧记录,然后确定该查询导致锁定升级,阻止其他用户:
SQL
1DELETE FROM LogMessages WHERE LogDate < '20020102';通过一次删除这些记录数百条,可以显著减少每个事务累积的锁数。 这将防止锁升级。 例如,运行以下查询:
SQL
123456DECLARE @done bit = 0;WHILE (@done = 0)BEGINDELETE TOP(1000) FROM LogMessages WHERE LogDate < '20020102';IF @@rowcount < 1000 SET @done = 1;END;通过使查询尽可能高效,减少查询的锁定占用量。 大型扫描或许多书签查找可能会增加锁定升级的机会。 此外,这会增加死锁的几率,并会对并发和性能产生不利影响。 确定导致锁升级的查询后,请查找创建新索引或向现有索引添加列的机会,以删除索引或表扫描,并最大程度地提高索引查找的效率。 查看执行计划,并可能创建新的非聚集索引以提高查询性能。 有关详细信息,请参阅SQL Server索引体系结构和设计指南。
此优化的目标之一是使索引查找返回的行尽可能少,以最大程度地降低书签查找的成本, (最大化查询) 索引的选择性。 如果SQL Server估计书签查找逻辑运算符将返回许多行,则它可能会使用
PREFETCH子句执行书签查找。 如果SQL Server确实用于PREFETCH书签查找,则必须将部分查询的事务隔离级别提高为部分查询的“可重复读取”。 这意味着SELECT,类似于“已提交读取”隔离级别的语句可能会获取成千上万的键锁, (聚集索引和一个非聚集索引) 。 这可能会导致此类查询超过锁升级阈值。 如果发现升级的锁是共享表锁,这一点尤其重要,尽管这些锁在默认的“已提交”隔离级别并不常见。 如果书签查找 WITHPREFETCH子句导致升级,请考虑将列添加到出现在“索引查找”中的非聚集索引,或向查询计划中“书签查找”逻辑运算符下方的“索引扫描”逻辑运算符添加列。 可以创建覆盖索引 (索引,该索引包含查询) 中使用的表中的所有列;如果包含“选择列”列表中的所有内容不切实际,则至少创建一个索引,该索引涵盖用于联接条件或 WHERE 子句的列。嵌套循环联接也可能使用
PREFETCH,这会导致相同的锁定行为。如果其他 SPID 当前持有不兼容的表锁,则不会发生锁升级。 锁升级始终升级到表锁,从不升级到页锁。 此外,如果锁升级尝试失败,因为另一个 SPID 持有不兼容的 TAB 锁,则尝试升级的查询在等待 TAB 锁时不会阻止。 相反,它会继续在其原始、更精细的级别 (行、键或页) 获取锁,并定期进行其他升级尝试。 因此,防止对特定表进行锁升级的一种方法是在与升级锁类型不兼容的其他连接上获取并保留锁。 表级别的 IX (意向独占) 锁不会锁定任何行或页,但它仍与升级的 S (共享) 或 X (独占) TAB 锁不兼容。 例如,假设必须运行一个批处理作业,该作业修改了 mytable 表中的许多行,并且由于锁定升级而导致阻塞。 如果此作业始终在一小时内完成,则可以创建包含以下代码的 Transact-SQL 作业,并将新作业计划为在批处理作业开始时间之前的几分钟启动:
SQL
1234BEGIN TRAN;SELECT * FROM mytable (UPDLOCK, HOLDLOCK) WHERE 1 = 0;WAITFOR DELAY '1:00:00';COMMIT TRAN;此查询获取并保留 mytable 上的 IX 锁一小时。 这可以防止在此期间对表进行锁升级。 此批处理不会修改任何数据或阻止其他查询 (除非其他查询使用 TABLOCK 提示强制表锁定,或者管理员已使用 ALTER INDEX) 禁用页面或行锁。
消除由于缺乏 SARGability 而导致的锁升级,这是一个关系数据库术语,用于描述查询是否可以对谓词和联接列使用索引。 有关 SARGability 的详细信息,请参阅 内部设计指南查询注意事项。 例如,看似不请求多个行或单个行的相当简单的查询最终仍可能扫描整个表/索引。 如果 WHERE 子句左侧有函数或计算,则可能会出现这种情况。 此类缺乏 SARGability 的示例包括隐式或显式数据类型转换、ISNULL () 系统函数、将列作为参数传递的用户定义函数,或者对列进行计算,例如
WHERE CONVERT(INT, column1) = @a或WHERE Column1*Column2 = 5。 在这种情况下,查询无法 SEEK 现有索引,即使它包含相应的列,因为必须首先检索所有列值并将其传递给函数。 这会导致扫描整个表或索引,并导致获取大量锁。 在这种情况下,SQL Server可以达到锁计数升级阈值。 解决方案是避免对 WHERE 子句中的列使用函数,从而确保 SARGable 条件。
禁用锁升级
尽管可以在 SQL Server 中禁用锁升级,但我们不建议这样做。 请改用 防止锁定升级 部分中所述的防护策略。
- 表级别: 可以在表级别禁用锁升级。 请参阅
ALTER TABLE ... SET (LOCK_ESCALATION = DISABLE)。 若要确定要面向哪个表,请检查 T-SQL 查询。 如果不可能,请使用 扩展事件,启用 lock_escalation 事件,并检查 object_id 列。 或者,使用 Lock:Escalation 事件 ,并使用 SQL Profiler 检查ObjectID2列。 - 实例级别: 可以通过为实例启用跟踪标志 1211 或 1224 或两者来禁用锁升级。 但是,这些跟踪标志在 SQL Server 实例中全局禁用所有锁升级。 锁升级在SQL Server中非常有用,可以最大程度地提高查询的效率,否则,这些查询会因获取和释放数千个锁的开销而降低。 锁升级还有助于最大程度地减少跟踪锁所需的内存。 SQL Server可为锁结构动态分配的内存是有限的。 因此,如果禁用锁升级,并且锁内存增长到足够大,则为任何查询分配其他锁的任何尝试都可能会失败,并生成以下错误条目:
错误: 1204,严重性: 19,状态: 1
SQL Server目前无法获取 LOCK 资源。 当活动用户较少时,请重新运行语句,或要求系统管理员检查SQL Server锁和内存配置。
备注
发生 1204 错误时,它会停止处理当前语句,并导致活动事务回滚。 如果重启SQL Server服务,回滚本身可能会阻止用户或导致数据库恢复时间过长。
可以使用 SQL Server 配置管理器 (-T1211 或 -T1224 ) 添加这些跟踪标志。 必须重启SQL Server服务,新的启动参数才能生效。 如果运行 DBCC TRACEON (1211, -1) 或 DBCC TRACEON (1224, -1) 查询,跟踪标志将立即生效。
但是,如果不添加 -T1211 或 -T1224 作为启动参数,则重启SQL Server服务时命令的效果DBCC TRACEON将丢失。 启用跟踪标志可防止将来的任何锁升级,但不会撤消活动事务中已发生的任何锁升级。
如果使用锁提示(如 ROWLOCK),则只会更改初始锁定计划。 锁提示不会阻止锁升级。
锁定升级阈值
在以下情况之一下,可能会发生锁升级:
- 达到内存阈值 - 达到锁内存的 40% 的内存阈值。 当锁内存超过缓冲池的 24% 时,可以触发锁升级。 锁内存限制为可见缓冲池的 60%。 锁升级阈值设置为锁内存的 40%。 这是缓冲池 60% 的 40%或 24%。 如果锁内存超过 60% 的限制 (则如果禁用锁升级) ,则分配其他锁的所有尝试都会失败,并
1204生成错误, - 达到锁阈值 - 检查内存阈值后,将评估在当前表或索引上获取的锁数。 如果数字超过 5,000,则会触发锁升级。
若要了解达到的阈值,请使用扩展事件,启用 lock_escalation 事件,并检查 escalated_lock_count 列和 escalation_cause 列。 或者,使用 Lock:Escalation 事件,并检查 EventSubClass 值,其中“0 - LOCK_THRESHOLD”表示语句超出了锁阈值,“1 - MEMORY_THRESHOLD”表示语句已超出内存阈值。 此外,检查 IntegerData 和 IntegerData2 列。
建议
与在表或实例级别禁用升级相比, 防止锁定升级 部分中讨论的方法更好。 此外,与禁用锁升级相比,预防性方法通常为查询带来更好的性能。 Microsoft 建议仅启用此跟踪标志,以缓解锁升级导致的严重阻塞,同时正在调查其他选项(如本文中讨论的选项)。
排查由编译锁引起的阻塞问题
摘要
在 Microsoft SQL Server中,一次通常只有一个存储过程计划的副本位于缓存中。 强制实施这一点需要对编译过程的某些部分进行序列化,而此同步部分通过使用编译锁来完成。 如果许多连接同时运行同一个存储过程,并且每次运行时都必须为该存储过程获取编译锁,则会话 ID (SPID) 可能会开始相互阻止,因为它们各自尝试获取对象的独占编译锁。
下面是可在阻塞输出中观察到的编译阻塞的一些典型特征:
waittype阻塞和 (通常) 阻止会话 SPID 是LCK_M_X(独占) 并且waitresource采用 的形式OBJECT: dbid: object_id [[COMPILE]],其中object_id是存储过程的对象 ID。- 阻止程序具有
waittypeNULL,状态为可运行。 阻止者具有waittypeLCK_M_X(独占锁) ,状态处于睡眠状态。 - 尽管阻塞事件的持续时间可能很长,但没有一个 SPID 长时间阻止其他 SPID。 存在滚动阻塞。 一旦一个编译完成,另一个 SPID 就会在几秒钟或更短的秒内接管头部阻塞器的角色,依此推。
以下信息来自此类阻止期间的 快照 sys.dm_exec_requests :
控制台
1 2 3 4 5 6 7 8 9 10 11 12 13 | session_id blocking_session_id wait_type wait_time waitresource ---------- ------------------- --------- --------- ---------------------------- 221 29 LCK_M_X 2141 OBJECT: 6:834102 [[COMPILE]] 228 29 LCK_M_X 2235 OBJECT: 6:834102 [[COMPILE]] 29 214 LCK_M_X 3937 OBJECT: 6:834102 [[COMPILE]] 13 214 LCK_M_X 1094 OBJECT: 6:834102 [[COMPILE]] 68 214 LCK_M_X 1968 OBJECT: 6:834102 [[COMPILE]] 214 0 LCK_M_X 0 OBJECT: 6:834102 [[COMPILE]] |
在 waitresource 6:834102) (列中,6 是数据库 ID,834102 是对象 ID。 此对象 ID 属于存储过程,而不是表。
更多信息
存储过程重新编译是存储过程或触发器上的编译锁的一种解释。 在这种情况下,解决方案是减少或消除重新编译。
导致编译锁的其他方案
存储过程执行时没有完全限定名称
- 运行存储过程的用户不是该过程的所有者。
- 存储过程名称未与对象所有者的名称完全限定。
例如,如果用户 dbo 拥有对象
dbo.mystoredproc和另一个用户 ,Harry则使用 命令exec mystoredproc运行此存储过程,则按对象名称进行初始缓存查找失败,因为对象不是所有者限定的。 (目前还不清楚是否存在另一个名为 的Harry.mystoredproc存储过程。因此,SQL Server无法确保的dbo.mystoredproc缓存计划是正确的执行计划。) SQL Server然后获取过程的独占编译锁,并准备编译过程。 这包括将对象名称解析为对象 ID。 在SQL Server编译计划之前,SQL Server使用此对象 ID 对过程缓存执行更精确的搜索,并且即使没有所有者资格,也可以找到以前编译的计划。如果找到现有计划,SQL Server会重复使用缓存的计划,并且不会实际编译存储过程。 但是,由于缺少所有者资格,因此SQL Server在程序确定可以重用现有的缓存执行计划之前执行第二个缓存查找并获取独占编译锁。 获取锁并执行查找以及达到此点所需的其他工作可能会给编译锁带来延迟,从而导致阻塞。 如果许多不是存储过程所有者的用户在不提供所有者名称的情况下并发运行该过程,则尤其如此。 即使没有看到 SPID 等待编译锁,缺乏所有者资格也会造成存储过程执行延迟,并导致 CPU 使用率过高。
发生此问题时,以下事件序列将记录在SQL Server扩展事件会话中。
事件名称 Text rpc_starting mystoredproc sp_cache_miss mystoredproc sql_batch_starting mystoredproc sp_cache_hit mystoredproc ... ... sp_cache_miss当按名称查找缓存失败时发生,但在将不明确的对象名称解析为对象 ID 并存在sp_cache_hit事件后,最终在缓存中找到匹配的缓存计划时发生。编译锁定问题的解决方法是确保对存储过程的引用是所有者限定的。 (而不是 exec
mystoredproc,请使用 execdbo.mystoredproc.) 虽然所有者资格对于性能原因很重要,但不必使用数据库名称限定存储的处理,以防止额外的缓存查找。通过使用标准阻止故障排除方法,可以检测到由编译锁引起的阻塞。
存储过程的前缀为 sp_
如果存储过程名称以
sp_前缀开头,并且不在 master 数据库中,则即使所有者限定存储过程,每次执行的缓存命中之前都会看到 sp_cache_miss 。 这是因为前缀sp_告知SQL Server存储过程是系统存储过程,系统存储过程具有不同的名称解析规则。 (首选位置位于 master 数据库中。) 用户创建的存储过程的名称不应以sp_开头。使用大小写 (上/下) 调用存储过程
如果使用其他大小写执行所有者限定过程, () 创建过程时所使用的大小写,则该过程可以触发 CacheMiss 事件或请求 COMPILE 锁。 最终,该过程使用缓存的计划,并且不会重新编译。 但是,如果有许多 SPID 尝试使用与创建锁时所用的大小写不同的大小写来执行相同的过程,则对编译锁的请求有时可能会导致 阻塞链 的情况。 无论在服务器或数据库上使用的排序顺序或排序规则如何,都是如此。 此行为的原因是,用于在缓存中查找过程的算法基于性能) (的哈希值,如果大小写不同,哈希值可能会更改。
解决方法是使用与应用程序执行过程时所使用的相同大小写删除并创建过程。 还可以使用正确的大小写 () ,确保从所有应用程序执行该过程。
存储过程作为 Language 事件调用
如果尝试将存储过程作为语言事件而不是 RPC 执行,SQL Server必须分析和编译语言事件查询,确定查询正在尝试执行特定过程,然后尝试在缓存中查找该过程的计划。 若要避免出现SQL Server必须分析和编译语言事件的情况,请确保将查询作为 RPC 发送到 SQL。
有关详细信息,请参阅联机丛书中的 “创建存储过程” 一文中的“系统 存储过程”部分。
sys.partitions (Transact-SQL)
数据库中的所有表和大部分类型的索引的每个分区各对应一行。 此视图中不包括特殊索引类型,例如全文索引、空间索引和 XML 索引。 SQL Server中的所有表和索引至少包含一个分区,无论它们是否显式分区。
| 列名称 | 数据类型 | 说明 |
|---|---|---|
| partition_id | bigint | 指示分区 ID。 在数据库中是唯一的。 |
| object_id | int | 指示此分区所属的对象的 ID。 每个表或视图都至少包含一个分区。 |
| index_id | int | 指示此分区所属的对象内的索引的 ID。 0 = 堆 1 = 聚集索引 2 或更高 = 非聚集索引 |
| partition_number | int | 所属索引或堆中的从 1 开始的分区号。 对于未分区的表和索引,此列的值为 1。 |
| hobt_id | bigint | 指示包含此分区行的数据堆或 B 树 (HoBT) 的 ID。 |
| 行 | bigint | 指示此分区中的大约行数。 |
| filestream_filegroup_id | smallint | 适用于:SQL Server 2012 (11.x) 及更高版本。 指示在此分区上存储的 FILESTREAM 文件组的 ID。 |
| data_compression | tinyint | 指示每个分区的压缩状态: 0 = NONE 1 = ROW 2 = PAGE 3 = COLUMNSTORE:适用于:SQL Server 2012 (11.x) 及更高版本 4 = COLUMNSTORE_ARCHIVE:适用于:SQL Server 2014 (12.x) 及更高版本 注意:将在任何版本的 SQL Server 中压缩全文索引。 |
| data_compression_desc | nvarchar(60) | 指示每个分区的压缩状态。 行存储表的可能值为 NONE、ROW 和 PAGE。 列存储表的可能值为 COLUMNSTORE 和 COLUMNSTORE_ARCHIVE。 |
权限
要求 公共 角色具有成员身份。 有关详细信息,请参阅 Metadata Visibility Configuration。
示例
确定对象使用的空间并显示相关的分区信息
以下查询返回数据库中的所有对象、每个对象中使用的空间量以及与每个对象相关的分区信息。
1 2 3 4 5 6 7 8 9 10 11 | SELECT object_name(object_id) AS ObjectName, total_pages / 128. AS SpaceUsed_MB, p.partition_id, p.object_id, p.index_id, p.partition_number, p.rows, p.data_compression_desc FROM sys.partitions AS p JOIN sys.allocation_units AS au ON p.partition_id = au.container_id ORDER BY SpaceUsed_MB DESC; |
并发事务:死锁跟踪
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | -- 测试代码 -- DROP TABLE Test CREATE TABLE Test ( id INT, name VARCHAR(20), info VARCHAR(20), ) CREATE CLUSTERED INDEX IX_Test ON DBO.Test(id) CREATE NONCLUSTERED INDEX IX_Test_name ON DBO.Test(name) INSERT INTO Test VALUES(1,'kk',null),(2,'mm',null) SELECT * FROM Test |
【测试一】
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | ------------------------------------------------------------ --打开:窗口【1】 BEGIN TRAN update dbo.Test set info='A' where id =1 waitfor delay '00:00:10' update dbo.Test set info='B' where id =2 COMMIT TRAN ------------------------------------------------------------ ------------------------------------------------------------ --打开:窗口【2】 BEGIN TRAN update dbo.Test set info='C' where id =2 update dbo.Test set info='D' where id =1 COMMIT TRAN ------------------------------------------------------------ |
打开Profile 监控事件locks:deadlock
先执行窗口【1】,再执行窗口【2】。结果窗口【2】死锁:

表更改结果:
Profile 捕获到的信息:
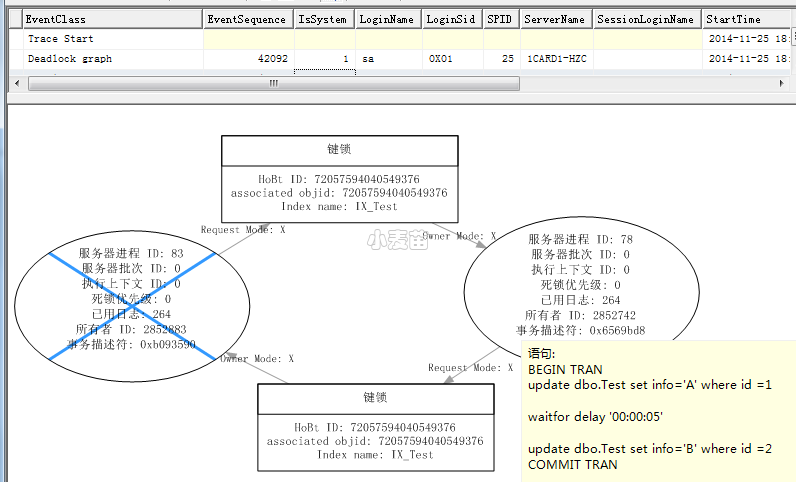
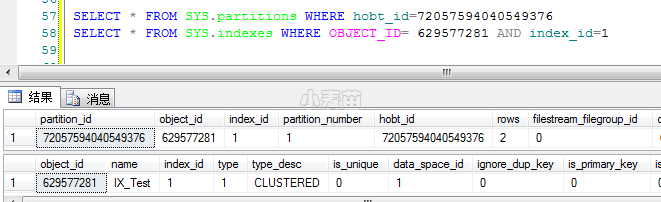
方形的图中,键锁 HoBt ID 可以确定是哪个索引:
1 2 3 | SELECT * FROM SYS.partitions WHERE hobt_id=72057594040549376 SELECT * FROM SYS.indexes WHERE OBJECT_ID= 629577281 AND index_id=1 |
将Profile 捕获到的信息拷贝出来:
主要分为两部分,一部分为进程的执行信息,另一部分为堵塞资源的请求信息。
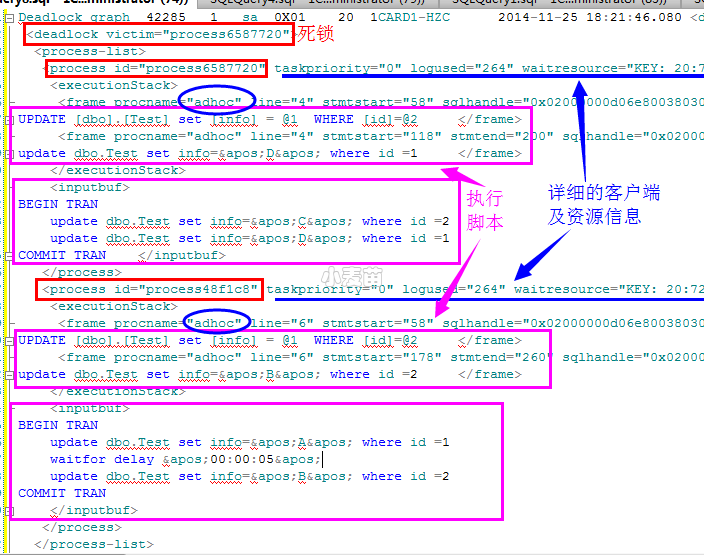

观察上面这几点,都可以找到死锁的客户端信息和产生死锁的对象,可以大致了解产生这个死锁的过程。
找到的批处理脚本,即可通过其他方法优化解决。
【测试二】
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | UPDATE Test SET info = NULL SELECT * FROM Test --开启死锁跟踪标志 DBCC TRACEON(1204,-1) DBCC TRACEON(1222,-1) ------------------------------------------------------------ --打开:窗口【3】 BEGIN TRAN update dbo.Test set info='A' where name ='kk' waitfor delay '00:00:05' update dbo.Test set info='B' where name ='mm' COMMIT TRAN ------------------------------------------------------------ ------------------------------------------------------------ --打开:窗口【4】 BEGIN TRAN delete from dbo.Test where name ='mm' update dbo.Test set info='C' where name ='kk' COMMIT TRAN ------------------------------------------------------------ |
先运行窗口【3】,再运行窗口【4】,结果如下:

窗口【3】作为死锁牺牲品,死锁图如下:
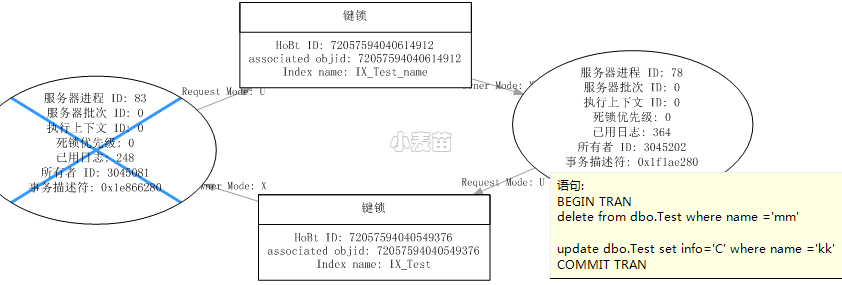

这是聚集索引和非聚集索引引起的键死锁。
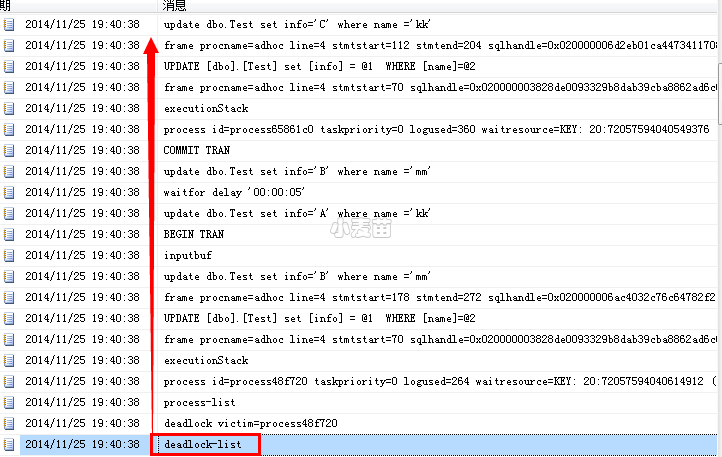
跟踪标志 1204和跟踪标志 1222:
发生死锁时,跟踪标志 1204和跟踪标志 1222会返回在SQLServer 2005 错误日志中捕获的信息。跟踪标志 1204会报告由死锁所涉及的每个节点设置格式的死锁信息。跟踪标志 1222会设置死锁信息的格式,顺序为先按进程,然后按资源。可以同时启用这两个跟踪标志,以获取同一个死锁事件的两种表示形式。
DBCC TRACEON(1204,-1) (如果打开1204标志,日志记录如下)

DBCC TRACEON(1222,-1) (如果打开1222标志,日志记录如下)
1 2 3 4 5 6 7 8 9 10 11 12 13 | --【若只有以下索引,死锁的模式和请求的锁如下】 -- 不死锁,但都是聚集索引扫描 -- DROP INDEX IX_Test_name ON DBO.Test CREATE CLUSTERED INDEX IX_Test ON DBO.Test(id) --mode(U,U)和mode(X,U) 的键锁和RID锁 -- DROP INDEX IX_Test ON DBO.Test CREATE NONCLUSTERED INDEX IX_Test_name ON DBO.Test(name,id) WITH(DROP_EXISTING = ON) --mode(X,U)和mode(X,U) 的键锁和键锁 CREATE CLUSTERED INDEX IX_Test ON DBO.Test(id) CREATE NONCLUSTERED INDEX IX_Test_name ON DBO.Test(name) WITH(DROP_EXISTING = ON) |
上面只是资源死锁确定的一般常用方法,都可以确定死锁问题。最不好的是死锁时输出的语句不是完整的,没有上下文环境。
减少死锁的一些方法:
◆ 按同一顺序访问对象。
◆ 避免事务中的用户交互。
◆ 保持事务简短并处于一个批处理中。
◆ 使用较低的隔离级别。
◆ 使用基于行版本控制的隔离级别。
将 READ_COMMITTED_SNAPSHOT 数据库选项设置为 ON,使得已提交读事务使用行版本控制。
使用快照隔离。
◆ 使用绑定连接。
并发事务:死锁跟踪之确定死锁锁定的资源
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | --测试示例: CREATE TABLE mytest ( id INT, name VARCHAR(20), info VARCHAR(20), ) INSERT INTO mytest VALUES(1,'kk',null),(2,'mm',null) --【现在测试只有非聚集索引的】 CREATE NONCLUSTERED INDEX IX_mytest_id ON DBO.mytest(id) --打开跟踪标志 DBCC TRACEON(1222,-1) --分别打开个窗口,先执行事务窗口【1】,再执行事务窗口【2】 --事务窗口【1】 BEGIN TRAN PRINT @@SPID update dbo.mytest set info='A' where id =1 waitfor delay '00:00:10' update dbo.mytest set info='B' where id =2 ROLLBACK TRAN --事务窗口【2】 BEGIN TRAN PRINT @@SPID update dbo.mytest set info='C' where id =2 select * from dbo.mytest where id =1 ROLLBACK TRAN |
--session=61 成为死锁牺牲品
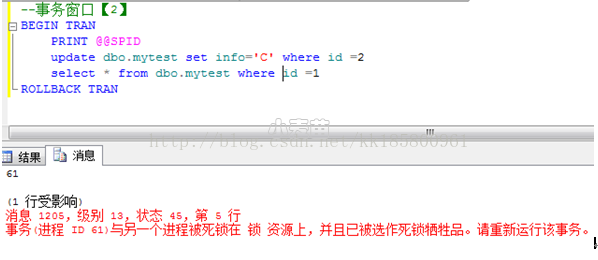
--打开SqlServer日志,几个地方可以看到锁定的资源信息。
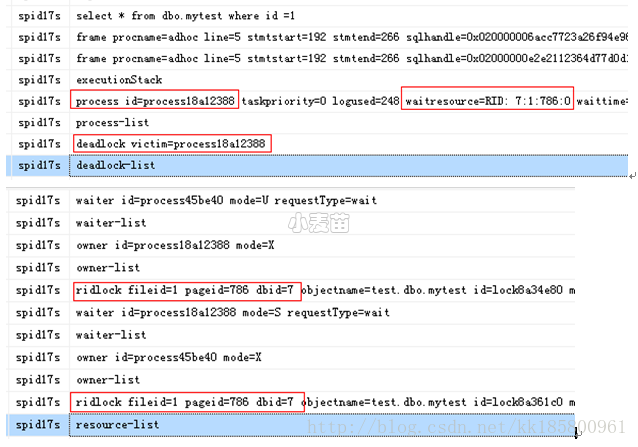
\这个\RID\具体是哪行数据在争用导致死锁??
1 2 3 4 5 6 7 | --找到主要信息 waitresource=RID: 7:1:786:0 这是一个堆表,db_id=7,fileId=1,pageId=786,Slot = 0 --【方法一】查看数据页的信息 DBCC TRACEON(3604) DBCC PAGE(TEST,1,786,3) |
PAGE: (1:786)
Slot 0 Offset 0x1008Length 19
Record Type = PRIMARY_RECORD Record Attributes = NULL_BITMAP VARIABLE_COLUMNS