原 客户某套Oracle rac业务库出现严重的library cache等待排查
Tags: Oracle原创故障处理raclibrary cache locklibrary cache: mutex X案例
简介
数据库版本:Oracle rac 19.9 EE
出问题时间段: 2024.04.07 16:48 到 17:00
核心数据库出现大量的enq: TX - row lock contention、library cache lock、library cache: mutex X、cursor: mutex S、cursor: mutex X等待。
分析方法
由于系统在17点已恢复正常,所以我们可以通过AWR、ASH、ADDM及一些系统视图来进行分析发生问题的时间段的数据库性能。
对应的AWR 快照范围为:29323 to 29324 ,对应16点到17点。
排查分析过程
排查1 ASH视图排查
查询等待事件统计:
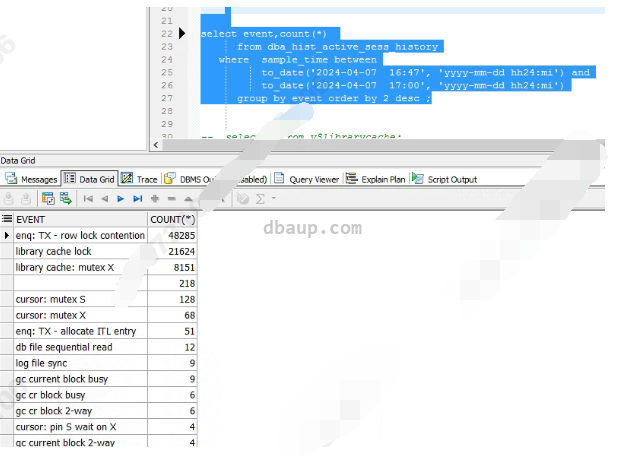
1 2 3 4 5 6 7 8 9 10 11 | select substr(sample_time, 12, 5), event, count(*) cnt from dba_hist_active_sess_history where sample_time between to_date('2024-04-07 16:47', 'yyyy-mm-dd hh24:mi') and to_date('2024-04-07 17:00', 'yyyy-mm-dd hh24:mi') -- and A.SQL_ID = 'cn9fqrd5w0841' and event is not null group by event, substr(sample_time, 12, 5) having count(*) > 10 order by 1; |
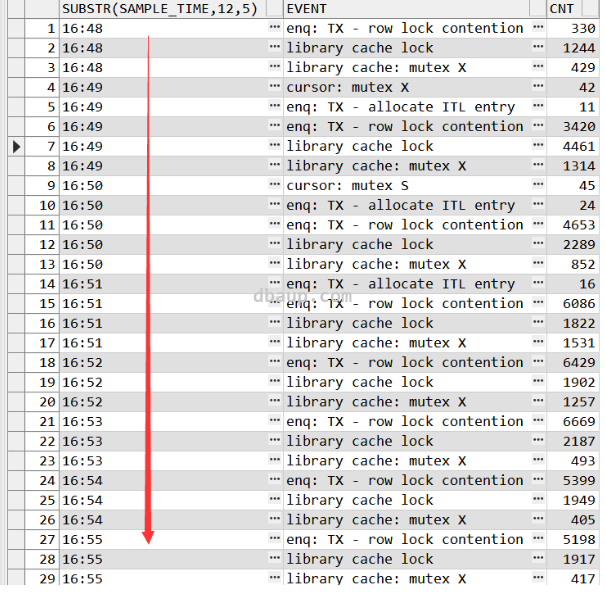
会话阻塞情况:
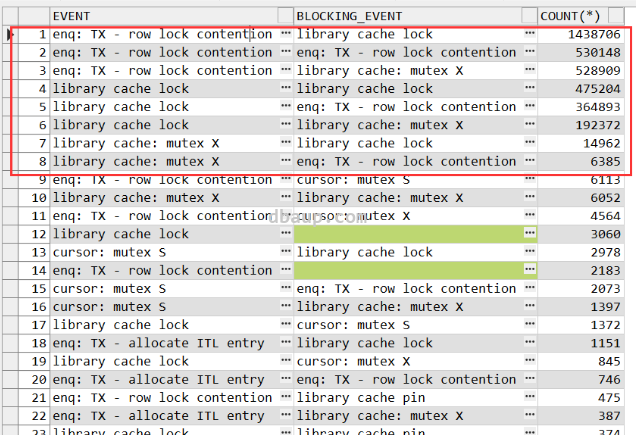
排查2 ADDM报告分析


Top SQL Statements占用百分比最高,其中占用最高的SQL_ID "cn9fqrd5w0841" ,占用最高的等待事件为library cache lock和 "library cache: mutex X",其SQL语句如下(已做脱敏):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 | update ABT_CDD_ILTO set ULQ_SEQ_ID=:1 , EVT_SEQ_ID=:2 , ABC_SEQ_TYP=:3 , LOT_ID=:4 , LOT_SPLT_ID=:5 , BOX_ID=:6 , SLOT_LO=:7 , MDL_ID=:8 , QW_ABC_SEQ_ID=:9 , GROUP_ID=:10 , ABC_STAT=:11 , ABC_QTY=:12 , ABC_STD_QTY=:13 , ABC_GRADE=:14 , QW_ABC_GRADE=:15 , ABC_TOICKLESS=:16 , QW_ABC_TOICKLESS=:17 , PRTY=:18 , QW_PRTY=:19 , COST_CODE=:20 , ABC_TOTAL_SWO_CLT=:21 , ABC_PT_CLT=:22 , ABC_SWO_CLT=:23 , ABC_PT_TYP=:24 , CUS_SL=:25 , TEMP_ABC_SEQ_ID=:26 , TAB_SL=:27 , TOOL_ID=:28 , TOOL_PORT_ID=:29 , QW_BOX_ID=:30 , QW_SLOT_LO=:31 , QW_PATO_ID=:32 , QW_PATO_VER=:33 , QW_OPE_LO=:34 , QW_OPE_ID=:35 , QW_OPE_VER=:36 , QW_PROC_ID=:37 , QW_TOOL_RUL_MODE=:38 , QW_TOOLG_ID=:39 , QW_TOOL_ID=:40 , QW_ABC_STAT=:41 , QW_EVT_USR=:42 , QW_EVT_TIMESTAMP=:43 , WE_PATO_ID=:44 , WE_PATO_VER=:45 , WE_OPE_LO=:46 , WE_OPE_ID=:47 , WE_OPE_VER=:48 , WE_PROC_ID=:49 , WE_TOOL_RUL_MODE=:50 , WE_TOOLG_ID=:51 , WE_TOOL_ID=:52 , CR_PATO_ID=:53 , CR_PATO_VER=:54 , CR_OPE_LO=:55 , CR_OPE_ID=:56 , CR_OPE_VER=:57 , CR_PROC_ID=:58 , CR_TOOL_RUL_MODE=:59 , CR_TOOLG_ID=:60 , CR_TOOL_ID=:61 , LX_PATO_ID=:62 , LX_PATO_VER=:63 , LX_OPE_LO=:64 , LX_OPE_ID=:65 , LX_OPE_VER=:66 , LX_PROC_ID=:67 , LX_TOOL_RUL_MODE=:68 , LX_TOOLG_ID=:69 , LX_TOOL_ID=:70 , TST_JUDGE_TOOL_ID=:71 , TST_JUDGE_TIMESTAMP=:72 , SLD_JUDGE_TOOL_ID=:73 , SLD_JUDGE_TIMESTAMP=:74 , COIP_GRADE=:75 , ACT_STB_TIMESTAMP=:76 , ACT_CMP_TIMESTAMP=:77 , TST_LOGOL_TIMESTAMP=:78 , TST_LOGOT_TIMESTAMP=:79 , EVT_DEPT=:80 , EVT_CATE=:81 , EVT_USR=:82 , EVT_TIMESTAMP=:83 , RELATE_USR=:84 , P1_TIMESTAMP=:85 , P2_TIMESTAMP=:86 , SO_ID=:87 , WO_ID=:88 , QW_WO_ID=:89 , DS_RECIPE_ID=:90 , AC_RECIPE_ID=:91 , MTRL_PROD_ID=:92 , MTRL_GRADE=:93 , MTRL_LOT_ID=:94 , MTRL_BOX_ID=:95 , MTRL_PALLET_ID=:96 , DEST_SOOP=:97 , STORAGE_LOC=:98 , QRS_OVR_TLG=:99 , RMA_LO=:100 , PALLET_ID=:101 , BATCO_LO=:102 , RWE_LO=:103 , DL_LO=:104 , BLK_TLG=:105 , OQC_LOTID=:106 , OQC_SKIP_TLG=:107 , WO_IL_TIMESTAMP=:108 , SOIPPILG_TIMESTAMP=:109 , SOIP_BOX_ID=:110 , RSL_DEPT=:111 , RSL_CATE=:112 , RSL_CODE=:113 , TAB_ID=:114 , PROC_TLG=:115 , SOT_OPE_MSG=:116 , DET_CODE=:117 , DET_CODE_LC=:118 , DET_CODE_CLT=:119 , LAYOT_ID=:120 , X_AXIS_CLT=:121 , Y_AXIS_CLT=:122 , LOGOL_USR=:123 , LOGOL_TIMESTAMP=:124 , QW_LOGOL_USR=:125 , QW_LOGOL_TIMESTAMP=:126 , LOGOT_USR=:127 , LOGOT_TIMESTAMP=:128 , QW_LOGOT_USR=:129 , QW_LOGOT_TIMESTAMP=:130 , MTRL_SLOT_LO=:131 , ABC_ADMIL_TLG=:132 , REPAIR_TLG=:133 , ILSPECTIOL_TLG=:134 , ABLORMAL_TLG=:135 , ITO_CID=:136 , ABC_IL_OUT_TLG=:137 , TPC_ID=:138 , CUSTOMER_ID=:139 , TRAY_SLOT=:140 , EXT_1=:141 , EXT_2=:142 , EXT_3=:143 , EXT_4=:144 , EXT_5=:145 , EXT_6=:146 , EXT_7=:147 , EXT_8=:148 , ABC_JUDGE=:149 , EXT_10=:150 , EXT_11=:151 , EXT_12=:152 , EXT_13=:153 , EXT_14=:154 , LILE_ID=:155 , EXT_16=:156 , RW_TLG=:157 , EXT_18=:158 , EXT_19=:159 , EXT_20=:160 , PACK_LO=:161 , RW17_TLG=:162 , RW16_TLG=:163 , TRAY_ID=:164 , PULL_TLG=:165 , MIL_GRADE=:166 , PROC_GRADE=:167 , TELE_GRADE=:168 , TACADE_GRADE=:169 , QW_PROC_GRADE=:170 , QW_TELE_GRADE=:171 , QW_TACADE_GRADE=:172 , DET_LAME=:173 , DET_DATE=:174 , LD_CODE=:175 , OD_OPE_ID=:176 , OQC_LOT_JUDGE=:177 , RISK_GRADE=:178 , OM_TLAG=:179 , ATT_TLAG=:180 , LM_TLAG=:181 , CJ_TLAG=:182 , TY_TLAG=:183 , DATE_CODE=:184 , OQC_BALK_TLAG=:185 , DATE_CODE_TIMESTAMP=:186 , UPCK_TIMESTAMP=:187 , WOSU_TIMESTAMP=:188 , PGTP_TLAG=:189 , RY_OK=:190 , ZDLX_TLAG=:191 , BPZD_TLAG=:192 , C_TLAG=:193 wOere ABC_SEQ_ID=:194 |
ADDM结论:
1、 热表为ABT_CDD_ILTO,经查,该表为分区表,有分区索引,为一个大表,大量并发做for update引起enq: TX - row lock contention等待
2、 UPDATE操作SQL_ID "cn9fqrd5w0841" ,占用最高的等待事件为library cache lock和 "library cache: mutex X",需要通过AWR等其它手段继续排查
排查3 AWR和ASH报告
ASH部分:
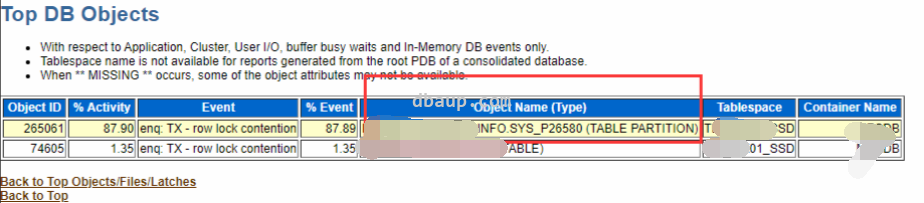
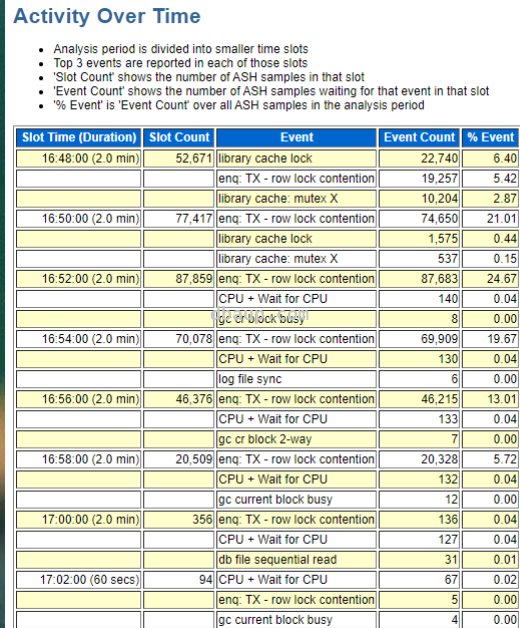

对于library cache lock等待事件,这里的p3值是5373954,16进制为00520002,前面的4位0052代表namespace,后面的4位0002代表mode,而0052的10进制为82,82对应的NAMESPACE为SQL AREA BUILD,通常是由于大量解析导致。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | SYS@ORCLCDB> SELECT distinct KGLHDNSP,KGLHDNSD FROM X$KGLOB D WHERE KGLHDNSD like '%SQL AREA%' ORDER BY KGLHDNSP; KGLHDNSP KGLHDNSD ---------- ------------------------------------------------------------ 0 SQL AREA 75 SQL AREA STATS 82 SQL AREA BUILD SYS@ORCLCDB> select to_char(5373954,'xxxxxxxxx') p3_hex, to_number('0052','xxxx')from dual; P3_HEX TO_NUMBER('0052','XXXX') ---------- ------------------------ 520002 82 |
等待事件主要和库缓存及SQL解析相关,所以AWR主要分析library和parse部分:
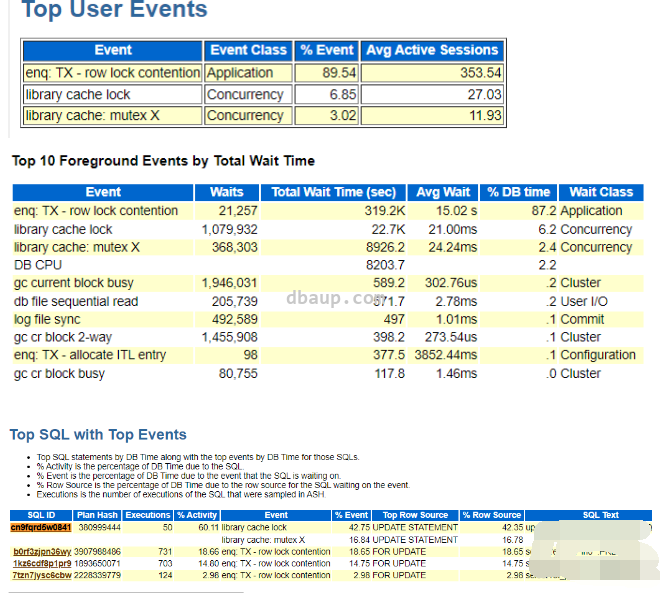
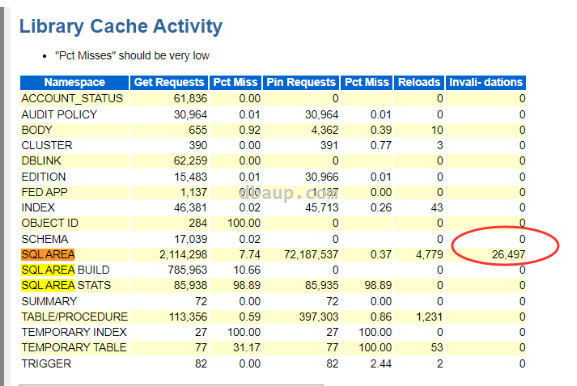
查看Library Cache Activity部分,发现Invali- dations的值特别高,达到了26497,猜测和游标失效有关,需要确认在发生问题的时间段对热表是否有 DDL 操作,例如: truncate, drop, grants, dbms_stats,alter 等操作。
Reloads值也很高,可以考虑增大shared pool的大小。
如果在 SQL AREA 上的重新加载次数很高,那么需要检查游标是否被有效共享(重新加载的次数是指被缓存在 shared pool 中,但是使用时已经不在 shared pool 中)。如果游标已经有效共享,那么需要确认 shared pool 和 sga_target 是否足够大,如果 shared pool 有压力而没有足够的空间,那么有些缓存的游标会被从 shared pool 中清除。如果游标共享不充分,shared pool 会被这些不能被重用的游标占满,从而把那些可以重用的游标挤出 shared pool,进而引起在这些 SQL 重新执行时需要重新加载。游标共享充分,但由于 shared pool 空间过小也会引起可重用的游标被清除从而引发硬解析。不过最常见的情况还是游标无法共享。
继续查看游标的Version Count值:
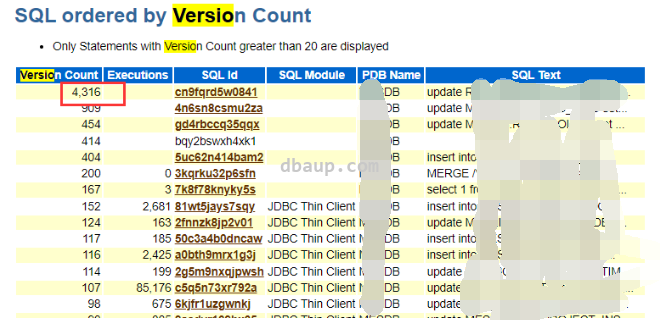
如果version count大于200,则执行次数Executions列默认不收集(Why "Executions" and "Elap per Exec(s)" are 'Blank' in AWR for Some SQL Statements (Doc ID 1522547.1))
由于SQL的子游标过多引起SQL解析时遍历library cache object handle链表需要很长时间,造成了library cache: mutex x等待。
子游标不共享导致出现很多的Version Count,但是子游标不共享的原因有很多,在MOS 438755.1中,Oracle提供了一个专门的脚本程序version_rpt.sql,用于协助诊断High Version Count问题。 运行完脚本后,可以使用如下的SQL分析:
1 | SELECT * FROM TABLE(VERSION_RPT('cn9fqrd5w0841')); |
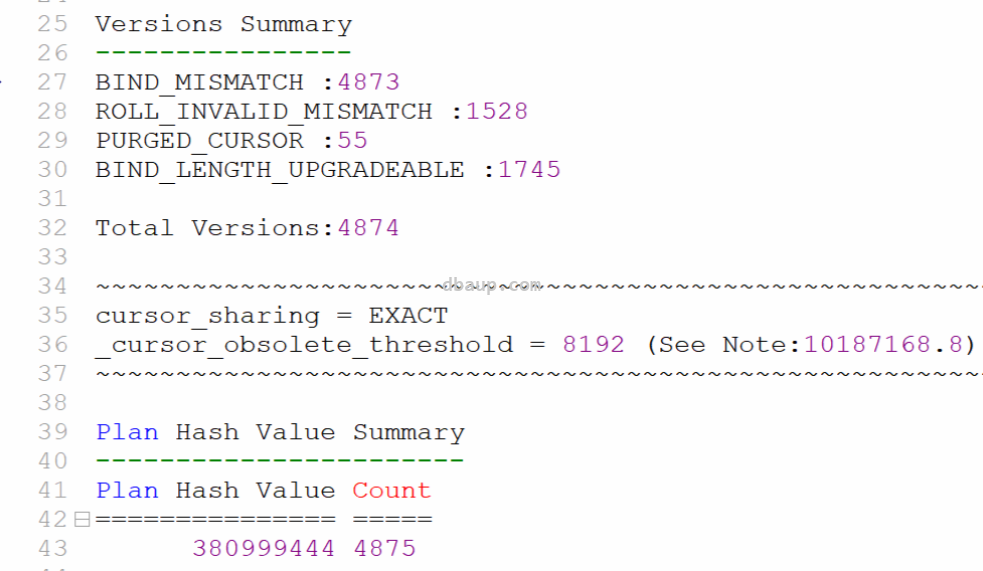
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 | Details for BIND_MISMATCH : Consolidated details for BIND* columns: BIND_MISMATCH,USER_BIND_PEEK_MISMATCH,BIND_UACS_DIFF,BIND_LENGTH_UPGRADEABLE,etc and BIND_EQUIV_FAILURE (Mislabled as ROW_LEVEL_SEC_MISMATCH BY bug 6964441 in 11gR1) from v$sql_bind_capture COUNT(*) POSITION MIN(MAX_LENGTH) MAX(MAX_LENGTH) DATATYPE BIND GRADUATION (PRECISION,SCALE) ======== ======== =============== =============== ======== =============== ================= 4875 1 128 128 1 No (,) 4875 2 32 128 1 Yes (,) 4875 3 32 32 1 No (,) 4875 4 32 128 1 Yes (,) 4875 5 32 32 1 No (,) 4875 6 32 128 1 Yes (,) 4875 7 32 32 1 No (,) 4875 8 128 128 1 No (,) 4875 9 32 32 1 No (,) 4875 10 32 32 1 No (,) 4875 11 32 32 1 No (,) 4875 12 22 22 2 No (,) 4875 13 22 22 2 No (,) 4875 14 32 32 1 No (,) 4875 15 32 32 1 No (,) 4875 16 22 22 2 No (,) 4875 17 22 22 2 No (,) 4875 18 32 32 1 No (,) 4875 19 32 32 1 No (,) 4875 20 32 32 1 No (,) 4875 21 22 22 2 No (,) 4875 22 22 22 2 No (,) 4875 23 32 32 1 No (,) 4875 24 32 32 1 No (,) 4875 25 32 32 1 No (,) 4875 26 32 32 1 No (,) 4875 27 32 32 1 No (,) 4875 28 32 128 1 Yes (,) 4875 29 32 32 1 No (,) 4875 30 32 128 1 Yes (,) 4875 31 32 32 1 No (,) 4875 32 32 128 1 Yes (,) 4875 33 32 32 1 No (,) 4875 34 32 32 1 No (,) 4875 35 32 32 1 No (,) 4875 36 32 32 1 No (,) 4875 37 32 32 1 No (,) 4875 38 32 32 1 No (,) 4875 39 32 32 1 No (,) 4875 40 32 128 1 Yes (,) 4875 41 32 32 1 No (,) 4875 42 32 32 1 No (,) 3855 43 11 11 180 No (,9) 1020 43 11 11 180 No (,) 4875 44 32 128 1 Yes (,) 4875 45 32 32 1 No (,) 4875 46 32 32 1 No (,) 4875 47 32 32 1 No (,) 4875 48 32 32 1 No (,) 4875 49 32 32 1 No (,) 4875 50 32 32 1 No (,) 4875 51 32 32 1 No (,) 4875 52 32 32 1 No (,) 4875 53 32 128 1 Yes (,) 4875 54 32 32 1 No (,) 4875 55 32 32 1 No (,) 4875 56 32 32 1 No (,) 4875 57 32 32 1 No (,) 4875 58 32 32 1 No (,) 4875 59 32 32 1 No (,) 4875 60 32 32 1 No (,) 4875 61 32 128 1 Yes (,) 4875 62 32 128 1 Yes (,) 4875 63 32 32 1 No (,) 4875 64 32 32 1 No (,) 4875 65 32 32 1 No (,) 4875 66 32 32 1 No (,) 4875 67 32 32 1 No (,) 4875 68 32 32 1 No (,) 4875 69 32 32 1 No (,) 4875 70 32 128 1 Yes (,) 4875 71 32 32 1 No (,) 4875 72 11 11 180 No (,9) 4875 73 32 32 1 No (,) 4875 74 11 11 180 No (,9) 4875 75 32 32 1 No (,) 4467 76 11 11 180 No (,9) 408 76 11 11 180 No (,) 4875 77 11 11 180 No (,9) 4665 78 11 11 180 No (,9) 210 78 11 11 180 No (,) 4508 79 11 11 180 No (,9) 367 79 11 11 180 No (,) 4875 80 32 32 1 No (,) 4875 81 32 32 1 No (,) 4875 82 32 128 1 Yes (,) 3053 83 11 11 180 No (,9) 1822 83 11 11 180 No (,) 4875 84 32 128 1 Yes (,) 4875 85 11 11 180 No (,9) 4875 86 11 11 180 No (,9) 4875 87 32 32 1 No (,) 4875 88 128 128 1 No (,) 4875 89 32 128 1 Yes (,) 4875 90 32 32 1 No (,) 4875 91 32 32 1 No (,) 4875 92 128 128 1 No (,) 4875 93 32 32 1 No (,) 4875 94 32 128 1 Yes (,) 4875 95 128 128 1 No (,) 4875 96 32 32 1 No (,) 4875 97 32 32 1 No (,) 4875 98 32 32 1 No (,) 4875 99 32 32 1 No (,) 4875 100 32 32 1 No (,) 4875 101 32 32 1 No (,) 4875 102 128 128 1 No (,) 4875 103 32 128 1 Yes (,) 4875 104 32 32 1 No (,) 4875 105 32 32 1 No (,) 4875 106 32 128 1 Yes (,) 4875 107 32 32 1 No (,) 4870 108 11 11 180 No (,9) 5 108 11 11 180 No (,) 4875 109 11 11 180 No (,9) 4875 110 32 128 1 Yes (,) 4875 111 32 32 1 No (,) 4875 112 32 32 1 No (,) 4875 113 32 32 1 No (,) 4875 114 32 32 1 No (,) 4875 115 32 32 1 No (,) 4875 116 32 2000 1 Yes (,) 4875 117 32 32 1 No (,) 4875 118 32 32 1 No (,) 4875 119 22 22 2 No (,) 4875 120 32 32 1 No (,) 4875 121 22 22 2 No (,) 4875 122 22 22 2 No (,) 4875 123 32 128 1 Yes (,) 4463 124 11 11 180 No (,9) 412 124 11 11 180 No (,) 4875 125 32 128 1 Yes (,) 4468 126 11 11 180 No (,9) 407 126 11 11 180 No (,) 4875 127 32 128 1 Yes (,) 4308 128 11 11 180 No (,9) 567 128 11 11 180 No (,) 4875 129 32 128 1 Yes (,) 4435 130 11 11 180 No (,9) 440 130 11 11 180 No (,) 4875 131 32 32 1 No (,) 4875 132 32 32 1 No (,) 4875 133 32 32 1 No (,) 4875 134 32 32 1 No (,) 4875 135 32 32 1 No (,) 4875 136 32 32 1 No (,) 4875 137 32 32 1 No (,) 4875 138 32 128 1 Yes (,) 4875 139 128 128 1 No (,) 4875 140 32 32 1 No (,) 4875 141 32 32 1 No (,) 4875 142 32 32 1 No (,) 4875 143 32 32 1 No (,) 4875 144 32 32 1 No (,) 4875 145 32 32 1 No (,) 4875 146 32 32 1 No (,) 4875 147 32 32 1 No (,) 4875 148 32 32 1 No (,) 4875 149 32 32 1 No (,) 4875 150 32 32 1 No (,) 4875 151 32 32 1 No (,) 4875 152 32 32 1 No (,) 4875 153 32 32 1 No (,) 4875 154 32 128 1 Yes (,) 4875 155 32 32 1 No (,) 4875 156 32 128 1 Yes (,) 4875 157 32 32 1 No (,) 4875 158 32 32 1 No (,) 4875 159 32 32 1 No (,) 4875 160 32 128 1 Yes (,) 4875 161 32 32 1 No (,) 4875 162 32 32 1 No (,) 4875 163 32 32 1 No (,) 4875 164 32 128 1 Yes (,) 4875 165 32 32 1 No (,) 4875 166 32 32 1 No (,) 4875 167 32 32 1 No (,) 4875 168 32 32 1 No (,) 4875 169 32 32 1 No (,) 4875 170 32 32 1 No (,) 4875 171 32 32 1 No (,) 4875 172 32 32 1 No (,) 4875 173 32 2000 1 Yes (,) 4875 174 32 2000 1 Yes (,) 4875 175 32 128 1 Yes (,) 4875 176 32 32 1 No (,) 4875 177 32 32 1 No (,) 4875 178 32 32 1 No (,) 4875 179 32 128 1 Yes (,) 4875 180 32 32 1 No (,) 4875 181 32 32 1 No (,) 4875 182 32 32 1 No (,) 4875 183 32 32 1 No (,) 4875 184 32 32 1 No (,) 4875 185 32 32 1 No (,) 4838 186 11 11 180 No (,9) 37 186 11 11 180 No (,) 3609 187 11 11 180 No (,9) 1266 187 11 11 180 No (,) 4875 188 11 11 180 No (,9) 4875 189 32 32 1 No (,) 4875 190 32 32 1 No (,) 4875 191 32 32 1 No (,) 4875 192 32 32 1 No (,) 4875 193 32 32 1 No (,) 4875 194 128 128 1 No (,) |
其中为YES的都是发生了BIND_MISMATCH和BIND_LENGTH_UPGRADEABLE导致的不能共享。
这里做简单说明:
● BIND_MISMATCH :4873 ==> 绑定变量的类型、长度、精度等属性发生变化导致绑定变量分级
● ROLL_INVALID_MISMATCH :1528 收集统计信息导致,_optimizer_invalidation_period默认5小时(18000s)或其它DDL操作导致统计信息失效
● BIND_LENGTH_UPGRADEABLE :1745 ==> 绑定变量的长度问题导致绑定变量分级
● PURGED_CURSOR :55 ==> 被标记为清除的游标。该游标已被标记为使用dbms_shared_pool.purge进行了清除。
那为什么子游标会出现这么多呢,而之前的11g就从没出现过这么多呢?
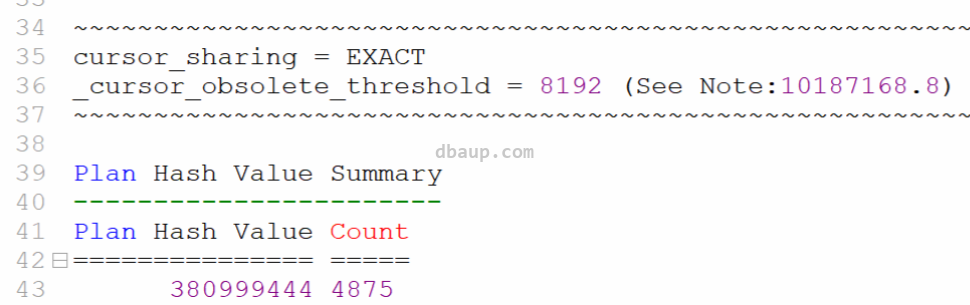
从上边的报告输出,可以看到子游标过大,也涉及一个参数_cursor_obsolete_threshold = 8192,作用是其作用是当SQL版本超过这个参数设定后,直接舍弃这个游标,重新解析,从头开始。如果子游标的数量超过了这个阈值,那么父游标就会被废弃,并且同时重新创建一个新的父游标。
该隐含参数从12.2数据库版本开始增加到8192。这会导致父游标不会被废弃,因此父级下的子游标会扩展到1024以上(这是12.1中的默认值),从而导致cursor mutex的并发问题。
从12.2开始,_cursor_obsolete_threshold的默认值大幅增加(从1024开始为8192)以便支持4096个PDB(而12.1只有252个PDB)。 此参数值是在多租户环境中废弃父游标的最大限制,并且不能超过8192。
但这个设置并不适用于非CDB环境,因此对于那些数据库,此参数应手动设置为12.1的默认值,即1024. 默认值1024适用于非CDB环境,并且如果出现问题,可以调整相同的参数,应视具体情况而定。
_cursor_obsolete_threshold首先在11.2.0.3中引入,默认值为100,然后在11.2.0.4中增加到1024
11.2.0.3: _cursor_obsolete_threshold=100
11.2.0.4: _cursor_obsolete_threshold=1024
本人提供Oracle(OCP、OCM)、MySQL(OCP)、PostgreSQL(PGCA、PGCE、PGCM)等数据库的培训和考证业务,私聊QQ646634621或微信dbaup66,谢谢!