
合 Oracle行列互换总结
Tags: Oracle
- 列转行
- UNION ALL ---主要方法
- 例一
- 例二
- insert all into ... select
- MODEL
- COLLECTION
- 行转列
- AGGREGATE FUNCTION(max+decode) ---主要方法
- 例一
- 例二
- 延伸
- 创建临时表
- PL/SQL --存过
- 多列转换成字符串
- || OR CONCAT
- 多行转换成字符串
- MAX + DECODE
- ROW_NUMBER + LEAD
- MODEL
- SYS_CONNECT_BY_PATH --主要方法
- WMSYS.WM_CONCAT(col) +dbms_lob.substr(clobcloum,2000,1) --主要方法
- 注意
- 通过分析函数实现行转列
- 引言
- 原理
- 实例
- 总结
- 例题
- 字符串转换成多列
- SUBSTR + INSTR
- 将单列分为多列
- 将多列分为多列
- REGEXP_SUBSTR
- 字符串转换成多行
- UNION ALL
- VARRAY
- SEQUENCE SERIES
- HIERARCHICAL + DBMS_RANDOM
- HIERARCHICAL + CONNECT_BY_ROOT
- MODEL
最近论坛很多人提的问题都与行列转换有关系,所以我对行列转换的相关知识做了一个总结,希望对大家有所帮助,同时有何错疏,恳请大家指出,我也是在写作过程中学习,算是一起和大家学习吧!
行列转换包括以下六种情况:
- 列转行
- 行转列
- 多列转换成字符串
- 多行转换成字符串
- 字符串转换成多列
- 字符串转换成多行
下面分别进行举例介绍。
首先声明一点,有些例子需要如下10g 及以后才有的知识:
A. 掌握model子句
B. 正则表达式
C. 加强的层次查询
讨论的适用范围只包括8i,9i,10g 及以后版本。
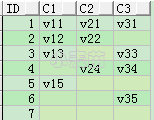
列转行
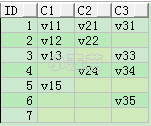
首先需要明白什么是列转行,简单的说就是将原表中的列名作为转换后的表的内容,这就是列转行。
CREATE TABLE t_col_row(
ID INT,
c1 VARCHAR2(10),
c2 VARCHAR2(10),
c3 VARCHAR2(10));
INSERT INTO t_col_row VALUES (1, 'v11', 'v21', 'v31');
INSERT INTO t_col_row VALUES (2, 'v12', 'v22', NULL);
INSERT INTO t_col_row VALUES (3, 'v13', NULL, 'v33');
INSERT INTO t_col_row VALUES (4, NULL, 'v24', 'v34');
INSERT INTO t_col_row VALUES (5, 'v15', NULL, NULL);
INSERT INTO t_col_row VALUES (6, NULL, NULL, 'v35');
INSERT INTO t_col_row VALUES (7, NULL, NULL, NULL);
COMMIT;
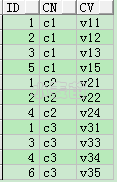
SELECT *** FROM t_col_row;**

UNION ALL ---主要方法
适用范围:8i,9i,10g 及以后版本
例一
SELECT id, 'c1' cn, c1 cv
FROM t_col_row
UNION ALL
SELECT id, 'c2' cn, c2 cv
FROM t_col_row
UNION ALL
SELECT id, 'c3' cn, c3 cv
FROM t_col_row;

若空行不需要转换,只需加一个where条件,
WHERE COLUMN IS NOT NULL 即可。
如:
SELECT id, 'c1' cn, c1 cv
FROM t_col_row
where c1 is not null
UNION ALL
SELECT id, 'c2' cn, c2 cv
FROM t_col_row
where c2 is not null
UNION ALL
SELECT id, 'c3' cn, c3 cv
FROM t_col_row
where c3 is not null;
例二
create table TEST_LHR
(
NAME VARCHAR2(255),
JANUARY NUMBER(18),
FEBRUARY NUMBER(18),
MARCH NUMBER(18),
APRIL NUMBER(18),
MAY NUMBER(18)
)
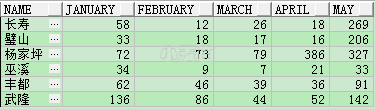
insert into TEST_LHR (NAME, JANUARY, FEBRUARY, MARCH, APRIL, MAY)
values ('长寿', 58, 12, 26, 18, 269);
insert into TEST_LHR (NAME, JANUARY, FEBRUARY, MARCH, APRIL, MAY)
values ('璧山', 33, 18, 17, 16, 206);
insert into TEST_LHR (NAME, JANUARY, FEBRUARY, MARCH, APRIL, MAY)
values ('杨家坪', 72, 73, 79, 386, 327);
insert into TEST_LHR (NAME, JANUARY, FEBRUARY, MARCH, APRIL, MAY)
values ('巫溪', 34, 9, 7, 21, 33);
insert into TEST_LHR (NAME, JANUARY, FEBRUARY, MARCH, APRIL, MAY)
values ('丰都', 62, 46, 39, 36, 91);
insert into TEST_LHR (NAME, JANUARY, FEBRUARY, MARCH, APRIL, MAY)
values ('武隆', 136, 86, 44, 52, 142);
commit;
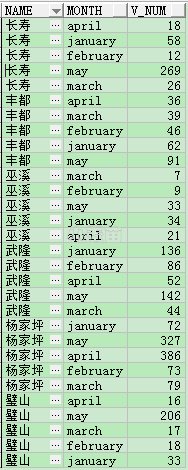
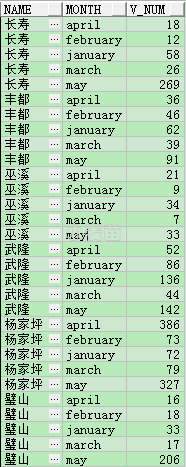
SELECT *****
FROM (SELECT t.name,
'january' MONTH,
t.january v_num
FROM TEST_LHR t
UNION ALL
SELECT t.name,
'february' MONTH,
t.february v_num
FROM TEST_LHR t
UNION ALL
SELECT t.name,
'march' MONTH,
t.march v_num
FROM TEST_LHR t
UNION ALL
SELECT t.name,
'april' MONTH,
t.april v_num
FROM TEST_LHR t
UNION ALL
SELECT t.name,
'may' MONTH,
t.may v_num
FROM TEST_LHR t)
ORDER BY NAME;

insert all into ... select
首先创建需要的表,test_lhr1,
SQL> desc test_lhr1
Name Type Nullable Default Comments
NAME VARCHAR2(255) Y
MONTH VARCHAR2(8) Y
V_NUM NUMBER(18) Y
然后执行下边的sql语句:
insert all
into test_lhr1(NAME,month,v_num) values(name, 'may', may)
into test_lhr1(NAME,month,v_num) values(name, 'april', april)
into test_lhr1(NAME,month,v_num) values(name, 'february', february)
into test_lhr1(NAME,month,v_num) values(name, 'march', march)
into test_lhr1(NAME,month,v_num) values(name, 'january', january)
select t.name,t.january,t.february,t.march,t.april,t.may from test_lhr t;
commit;
别忘记commit操作,然后再查询test_lhr1,发现表中的数据就是列转成行了。
select *** from test_lhr1;**
MODEL
适用范围:10g 及以后
SELECT id,
cn,
cv
FROM t_col_row
MODEL RETURN
UPDATED ROWS PARTITION BY(ID)
DIMENSION BY(0 AS n)
MEASURES('xx' AS cn, 'yyy' AS cv, c1, c2, c3)
RULES UPSERT ALL(cn[1] = 'c1', cn[2] = 'c2', cn[3] = 'c3', cv[1] = c1[0], cv[2] = c2[0], cv[3] = c3[0])
ORDER BY ID,
cn;
COLLECTION
适用范围:8i,9i,10g 及以后版本
要创建一个对象和一个集合:
CREATE TYPE cv_pair AS OBJECT(cn VARCHAR2(10),cv VARCHAR2(10));
CREATE TYPE cv_varr AS VARRAY(8) OF cv_pair;
SELECT id,
t.cn AS cn,
t.cv AS cv
FROM t_col_row,
TABLE(cv_varr(cv_pair('c1', t_col_row.c1),
cv_pair('c2', t_col_row.c2),
cv_pair('c3', t_col_row.c3))) t
ORDER BY 1,
2;
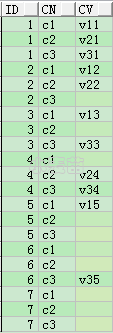
行转列
行转列就是将行数据内容作为列名。
CREATE TABLE t_row_col AS
SELECT id, 'c1' cn, c1 cv
FROM t_col_row
UNION ALL
SELECT id, 'c2' cn, c2 cv
FROM t_col_row
UNION ALL
SELECT id, 'c3' cn, c3 cv FROM t_col_row;
SELECT *** FROM t_row_col ORDER BY 1,2;**
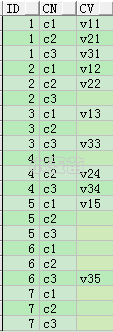
AGGREGATE FUNCTION(max+decode) ---主要方法
用聚集函数来实现,适用范围:8i,9i,10g 及以后版本
例一
SELECT id,
MAX(decode(cn, 'c1', cv, NULL)) AS c1,
MAX(decode(cn, 'c2', cv, NULL)) AS c2,
MAX(decode(cn, 'c3', cv, NULL)) AS c3
FROM t_row_col
GROUP BY id
ORDER BY 1;
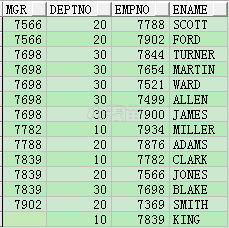
? 注意:
- MAX聚集函数也可以用sum、min、avg 等其他聚集函数替代。
- 被指定的转置列只能有一列,但固定的列可以有多列,如果转置列有多列可以有2种办法解决,① 采用1.3.2创建临时表的方式
② 可以先转为单列,单列采用字符串的格式,然后将单列转换为多列
请看下面的例子:
SELECT mgr,
deptno,
empno,
ename
FROM emp
ORDER BY 1,
2;
SELECT mgr,
deptno,
MAX(decode(empno, '7788', ename, NULL)) "7788",
MAX(decode(empno, '7902', ename, NULL)) "7902",
MAX(decode(empno, '7844', ename, NULL)) "7844",
MAX(decode(empno, '7521', ename, NULL)) "7521",
MAX(decode(empno, '7900', ename, NULL)) "7900",
MAX(decode(empno, '7499', ename, NULL)) "7499",
MAX(decode(empno, '7654', ename, NULL)) "7654"
FROM emp
WHERE mgr IN (7566, 7698)
AND deptno IN (20, 30)
GROUP BY mgr, deptno
ORDER BY 1, 2;

这里转置列为empno,固定列为mgr,deptno。
1、固定列数的行列转换
如
student subject grade
---------------------------
student1 语文 80
student1 数学 70
student1 英语 60
student2 语文 90
student2 数学 80
student2 英语 100
……
转换为
语文 数学 英语
student1 80 70 60
student2 90 80 100
……
语句如下:
select student,sum(decode(subject,'语文', grade,null)) "语文",
sum(decode(subject,'数学', grade,null)) "数学",
sum(decode(subject,'英语', grade,null)) "英语"
from table
group by student
2、不定列行列转换
如
c1 c2
--------------
1 我
1 是
1 谁
2 知
2 道
3 不
……
转换为
1 我是谁
2 知道
3 不
这一类型的转换必须借助于PL/SQL来完成,这里给一个例子
CREATE OR REPLACE FUNCTION get_c2(tmp_c1 NUMBER)
RETURN VARCHAR2
IS
Col_c2 VARCHAR2(4000);
BEGIN
FOR cur IN (SELECT c2 FROM t WHERE c1=tmp_c1) LOOP
Col_c2 := Col_c2||cur.c2;
END LOOP;
Col_c2 := rtrim(Col_c2,1);
RETURN Col_c2;
END;
/
SQL> select distinct c1 ,get_c2(c1) cc2 from table;即可
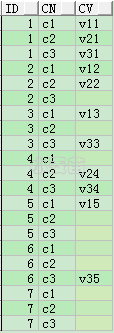
还有一种行转列的方式,就是相同组中的行值变为单个列值,但转置的行值不变为列名:
ID CN_1 CV_1 CN_2 CV_2 CN_3 CV_3
1 c1 v11 c2 v21 c3 v31
2 c1 v12 c2 v22 c3
3 c1 v13 c2 c3 v33
4 c1 c2 v24 c3 v34
5 c1 v15 c2 c3
6 c1 c2 c3 v35
7 c1 c2 c3
这种情况可以用分析函数实现:
SELECT id,
MAX(decode(rn, 1, cn, NULL)) cn_1,
MAX(decode(rn, 1, cv, NULL)) cv_1,
MAX(decode(rn, 2, cn, NULL)) cn_2,
MAX(decode(rn, 2, cv, NULL)) cv_2,
MAX(decode(rn, 3, cn, NULL)) cn_3,
MAX(decode(rn, 3, cv, NULL)) cv_3
FROM (SELECT id,
cn,
cv,
row_number() over(PARTITION BY id ORDER BY cn, cv) rn
FROM t_row_col)
GROUP BY ID;
例二
SELECT t.name,
MAX(decode(t.month, 'may', t.v_num)) AS may,
MAX(decode(t.month, 'april', t.v_num)) AS april,
MAX(decode(t.month, 'february', t.v_num)) AS february,
MAX(decode(t.month, 'march', t.v_num)) AS march,
MAX(decode(t.month, 'january', t.v_num)) AS january
FROM test_lhr1 t
GROUP BY t.name;

延伸
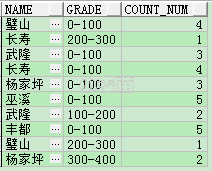
如果要实现对各个不同的区间进行统计,则:
SELECT *****
FROM test_lhr1 t
ORDER BY t.name,
t.month;
SELECT t.name,
CASE
WHEN t.v_num < 100 THEN
'0-100'
WHEN t.v_num >= 100 AND t.v_num < 200 THEN
'100-200'
WHEN t.v_num >= 200 AND t.v_num < 300 THEN
'200-300'
WHEN t.v_num >= 300 AND t.v_num < 400 THEN
'300-400'
END AS grade,
COUNT(t.v_num) count_num
FROM test_lhr1 t
GROUP BY t.name,
CASE
WHEN t.v_num < 100 THEN
'0-100'
WHEN t.v_num >= 100 AND t.v_num < 200 THEN
'100-200'
WHEN t.v_num >= 200 AND t.v_num < 300 THEN
'200-300'
WHEN t.v_num >= 300 AND t.v_num < 400 THEN
'300-400'
END;
SELECT t2.grade,
MAX(decode(t2.name, '璧山', t2.count_num)) 璧山,
MAX(decode(t2.name, '长寿', t2.count_num)) 长寿,
MAX(decode(t2.name, '武隆', t2.count_num)) 武隆,
MAX(decode(t2.name, '丰都', t2.count_num)) 丰都,
MAX(decode(t2.name, '杨家坪', t2.count_num)) 杨家坪
FROM (SELECT t.name,
CASE
WHEN t.v_num < 100 THEN
'0-100'
WHEN t.v_num >= 100 AND t.v_num < 200 THEN
'100-200'
WHEN t.v_num >= 200 AND t.v_num < 300 THEN
'200-300'
WHEN t.v_num >= 300 AND t.v_num < 400 THEN
'300-400'
END AS grade,
COUNT(t.v_num) count_num
FROM test_lhr1 t
GROUP BY t.name,
CASE
WHEN t.v_num < 100 THEN
'0-100'
WHEN t.v_num >= 100 AND t.v_num < 200 THEN
'100-200'
WHEN t.v_num >= 200 AND t.v_num < 300 THEN
'200-300'
WHEN t.v_num >= 300 AND t.v_num < 400 THEN
'300-400'
END) t2
GROUP BY t2.grade;

创建临时表
基本的行转列可以通过创建临时表来实现,首先将基础表根据条件创建几个临时表,然后将这些临时表关联起来就可以了。
SELECT t1.id,
t1.cv C1,
t2.cv C2,
t3.cv C3
FROM (SELECT *** FROM t_row_col t WHERE t.cn = 'c1') t1,**
(SELECT *** FROM t_row_col t WHERE t.cn = 'c2') t2,**
(SELECT *** FROM t_row_col t WHERE t.cn = 'c3')** t3
WHERE t1.id = t2.id
AND t2.id = t3.id;
PL/SQL --存过
适用范围:8i,9i,10g 及以后版本
这种对于行值不固定的情况可以使用。
下面是我写的一个包,包中
p_rows_column_real 用于前述的第一种不限定列的转换;
p_rows_column 用于前述的第二种不限定列的转换。
CREATE OR REPLACE PACKAGE pkg_dynamic_rows_column AS
TYPE refc IS REF CURSOR;
PROCEDURE p_print_sql(p_txt VARCHAR2);
FUNCTION f_split_str(p_str VARCHAR2, p_division VARCHAR2, p_seq INT)
RETURN VARCHAR2;
PROCEDURE p_rows_column(p_table IN VARCHAR2,
p_keep_cols IN VARCHAR2,
p_pivot_cols IN VARCHAR2,
p_where IN VARCHAR2 DEFAULT NULL,
p_refc IN OUT refc);
PROCEDURE p_rows_column_real(p_table IN VARCHAR2,
p_keep_cols IN VARCHAR2,
p_pivot_col IN VARCHAR2,
p_pivot_val IN VARCHAR2,
p_where IN VARCHAR2 DEFAULT NULL,
p_refc IN OUT refc);
END;
/
CREATE OR REPLACE PACKAGE BODY pkg_dynamic_rows_column AS
PROCEDURE p_print_sql(p_txt VARCHAR2) IS
v_len INT;
BEGIN
v_len := length(p_txt);
FOR i IN 1 .. v_len / 250 + 1 LOOP
dbms_output.put_line(substrb(p_txt, (i - 1) * 250 + 1, 250));
END LOOP;
END;
FUNCTION f_split_str(p_str VARCHAR2, p_division VARCHAR2, p_seq INT)
RETURN VARCHAR2 IS
v_first INT;
v_last INT;
BEGIN
IF p_seq < 1 THEN
RETURN NULL;
END IF;
IF p_seq = 1 THEN
IF instr(p_str, p_division, 1, p_seq) = 0 THEN
RETURN p_str;
ELSE
RETURN substr(p_str, 1, instr(p_str, p_division, 1) - 1);
END IF;
ELSE
v_first := instr(p_str, p_division, 1, p_seq - 1);
v_last := instr(p_str, p_division, 1, p_seq);
IF (v_last = 0) THEN
IF (v_first > 0) THEN
RETURN substr(p_str, v_first + 1);
ELSE
RETURN NULL;
END IF;
ELSE
RETURN substr(p_str, v_first + 1, v_last - v_first - 1);
END IF;
END IF;
END f_split_str;
PROCEDURE p_rows_column(p_table IN VARCHAR2,
p_keep_cols IN VARCHAR2,
p_pivot_cols IN VARCHAR2,
p_where IN VARCHAR2 DEFAULT NULL,
p_refc IN OUT refc) IS
v_sql VARCHAR2(4000);
TYPE v_keep_ind_by IS TABLE OF VARCHAR2(4000) INDEX BY
BINARY_INTEGER;
v_keep v_keep_ind_by;
TYPE v_pivot_ind_by IS TABLE OF VARCHAR2(4000) INDEX BY
BINARY_INTEGER;
v_pivot v_pivot_ind_by;
v_keep_cnt INT;
v_pivot_cnt INT;
v_max_cols INT;
v_partition VARCHAR2(4000);
v_partition1 VARCHAR2(4000);
v_partition2 VARCHAR2(4000);
BEGIN
v_keep_cnt := length(p_keep_cols) - length(REPLACE(p_keep_cols, ','))
+ 1;
v_pivot_cnt := length(p_pivot_cols) -
length(REPLACE(p_pivot_cols, ',')) + 1;
FOR i IN 1 .. v_keep_cnt LOOP
v_keep(i) := f_split_str(p_keep_cols, ',', i);
END LOOP;
FOR j IN 1 .. v_pivot_cnt LOOP
v_pivot(j) := f_split_str(p_pivot_cols, ',', j);
END LOOP;
v_sql := 'select max(count(*)) from ' || p_table || ' group by ';
FOR i IN 1 .. v_keep.LAST LOOP
v_sql := v_sql || v_keep(i) || ',';
END LOOP;
v_sql := rtrim(v_sql, ',');
EXECUTE IMMEDIATE v_sql
INTO v_max_cols;
v_partition := 'select ';
FOR x IN 1 .. v_keep.COUNT LOOP
v_partition1 := v_partition1 || v_keep(x) || ',';
END LOOP;
FOR y IN 1 .. v_pivot.COUNT LOOP
v_partition2 := v_partition2 || v_pivot(y) || ',';
END LOOP;
v_partition1 := rtrim(v_partition1, ',');
v_partition2 := rtrim(v_partition2, ',');
v_partition := v_partition || v_partition1 || ',' || v_partition2 ||
', row_number() over (partition by ' || v_partition1 ||
' order by ' || v_partition2 || ') rn from ' || p_table;
v_partition := rtrim(v_partition, ',');
v_sql := 'select ';
FOR i IN 1 .. v_keep.COUNT LOOP
v_sql := v_sql || v_keep(i) || ',';
END LOOP;
FOR i IN 1 .. v_max_cols LOOP
FOR j IN 1 .. v_pivot.COUNT LOOP
v_sql := v_sql || ' max(decode(rn,' || i || ',' || v_pivot(j) ||
',null))' || vpivot(j) || '' || i || ',';
END LOOP;
END LOOP;
IF p_where IS NOT NULL THEN
v_sql := rtrim(v_sql, ',') || ' from (' || v_partition || ' ' ||
p_where || ') group by ';
ELSE
v_sql := rtrim(v_sql, ',') || ' from (' || v_partition ||
') group by ';
END IF;
FOR i IN 1 .. v_keep.COUNT LOOP
v_sql := v_sql || v_keep(i) || ',';
END LOOP;
v_sql := rtrim(v_sql, ',');
p_print_sql(v_sql);
OPEN p_refc FOR v_sql;
EXCEPTION
WHEN OTHERS THEN
OPEN p_refc FOR
SELECT 'x' FROM dual WHERE 0 = 1;
END;
PROCEDURE p_rows_column_real(p_table IN VARCHAR2,
p_keep_cols IN VARCHAR2,
p_pivot_col IN VARCHAR2,
p_pivot_val IN VARCHAR2,
p_where IN VARCHAR2 DEFAULT NULL,
p_refc IN OUT refc) IS
v_sql VARCHAR2(4000);
TYPE v_keep_ind_by IS TABLE OF VARCHAR2(4000) INDEX BY
BINARY_INTEGER;
v_keep v_keep_ind_by;
TYPE v_pivot_ind_by IS TABLE OF VARCHAR2(4000) INDEX BY
BINARY_INTEGER;
v_pivot v_pivot_ind_by;
v_keep_cnt INT;
v_group_by VARCHAR2(2000);
BEGIN
v_keep_cnt := length(p_keep_cols) - length(REPLACE(p_keep_cols, ',')) +
1;
FOR i IN 1 .. v_keep_cnt LOOP
v_keep(i) := f_split_str(p_keep_cols, ',', i);
END LOOP;
v_sql := 'select ' || 'cast(' || p_pivot_col ||
' as varchar2(200)) as ' || p_pivot_col || ' from ' || p_table ||
' group by ' || p_pivot_col;
EXECUTE IMMEDIATE v_sql BULK COLLECT
INTO v_pivot;
FOR i IN 1 .. v_keep.COUNT LOOP
v_group_by := v_group_by || v_keep(i) || ',';
END LOOP;
v_group_by := rtrim(v_group_by, ',');
v_sql := 'select ' || v_group_by || ',';
FOR x IN 1 .. v_pivot.COUNT LOOP
v_sql := v_sql || ' max(decode(' || p_pivot_col || ',' || chr(39) ||
v_pivot(x) || chr(39) || ',' || p_pivot_val ||
',null)) as "' || v_pivot(x) || '",';
END LOOP;
v_sql := rtrim(v_sql, ',');
IF p_where IS NOT NULL THEN
v_sql := v_sql || ' from ' || p_table || p_where || ' group by ' ||
v_group_by;
ELSE
v_sql := v_sql || ' from ' || p_table || ' group by ' || v_group_by;
END IF;
p_print_sql(v_sql);
OPEN p_refc FOR v_sql;
EXCEPTION
WHEN OTHERS THEN
OPEN p_refc FOR
SELECT 'x' FROM dual WHERE 0 = 1;
END;
END;
/
多列转换成字符串
CREATE TABLE t_col_str AS
SELECT *** FROM t_col_row;**
这个比较简单,用|| 或concat 函数可以实现:
SELECT concat('a','b') FROM dual;
|| OR CONCAT
适用范围:8i,9i,10g 及以后版本
SELECT *** FROM t_col_str;**
SELECT ID,
c1 || ',' || c2 || ',' || c3 AS c123
FROM t_col_str;
多行转换成字符串
CREATE TABLE t_row_str(
ID INT,
col VARCHAR2(10)
);
INSERT INTO t_row_str VALUES(1,'a');
INSERT INTO t_row_str VALUES(1,'b');
INSERT INTO t_row_str VALUES(1,'c');
INSERT INTO t_row_str VALUES(2,'a');
INSERT INTO t_row_str VALUES(2,'d');
INSERT INTO t_row_str VALUES(2,'e');
INSERT INTO t_row_str VALUES(3,'c');
COMMIT;
SELECT *** FROM t_row_str;**

MAX + DECODE
适用范围:8i,9i,10g 及以后版本
SELECT id,
MAX(decode(rn, 1, col, NULL)) ||
MAX(decode(rn, 2, ',' || col, NULL)) ||
MAX(decode(rn, 3, ',' || col, NULL)) str
