合 PG WAL日志详解
预写式日志(WAL)
预写式日志(Write Ahead Log,WAL)是保证数据完整性的一种标准方法。对其详尽的描述几乎可以在所有(如果不是全部)有关事务处理的书中找到。简单来说,WAL的中心概念是数据文件(存储着表和索引)的修改必须在这些动作被日志记录之后才被写入,即在描述这些改变的日志记录被刷到持久存储以后。如果我们遵循这种过程,我们不需要在每个事务提交时刷写数据页面到磁盘,因为我们知道在发生崩溃时可以使用日志来恢复数据库:任何还没有被应用到数据页面的改变可以根据其日志记录重做(这是前滚恢复,也被称为REDO)。
因为WAL在崩溃后恢复数据库文件内容,不需要日志化文件系统作为数据文件或WAL文件的可靠存储。实际上,日志会降低性能,特别是如果日志导致文件系统数据被刷写到磁盘。幸运地是,日志期间的数据刷写常常可以在文件系统挂载选项中被禁用,例如在Linux ext3文件系统中可以使用data=writeback。在崩溃后日志化文件系统确实可以提高启动速度。
使用WAL可以显著降低磁盘的写次数,因为只有日志文件需要被刷出到磁盘以保证事务被提交,而被事务改变的每一个数据文件则不必被刷出。日志文件被按照顺序写入,因此同步日志的代价要远低于刷写数据页面的代价。在处理很多影响数据存储不同部分的小事务的服务器上这一点尤其明显。此外,当服务器在处理很多小的并行事务时,日志文件的一个fsync可以提交很多事务。
WAL也使得在线备份和时间点恢复能被支持,如第 25.3 节所述。通过归档WAL数据,我们可以支持回转到被可用WAL数据覆盖的任何时间:我们简单地安装数据库的一个较早的物理备份,并且重放WAL日志一直到所期望的时间。另外,该物理备份不需要是数据库状态的一个一致的快照 — 如果它的制作经过了一段时间,则重放这一段时间的WAL日志将会修复任何内部不一致性。
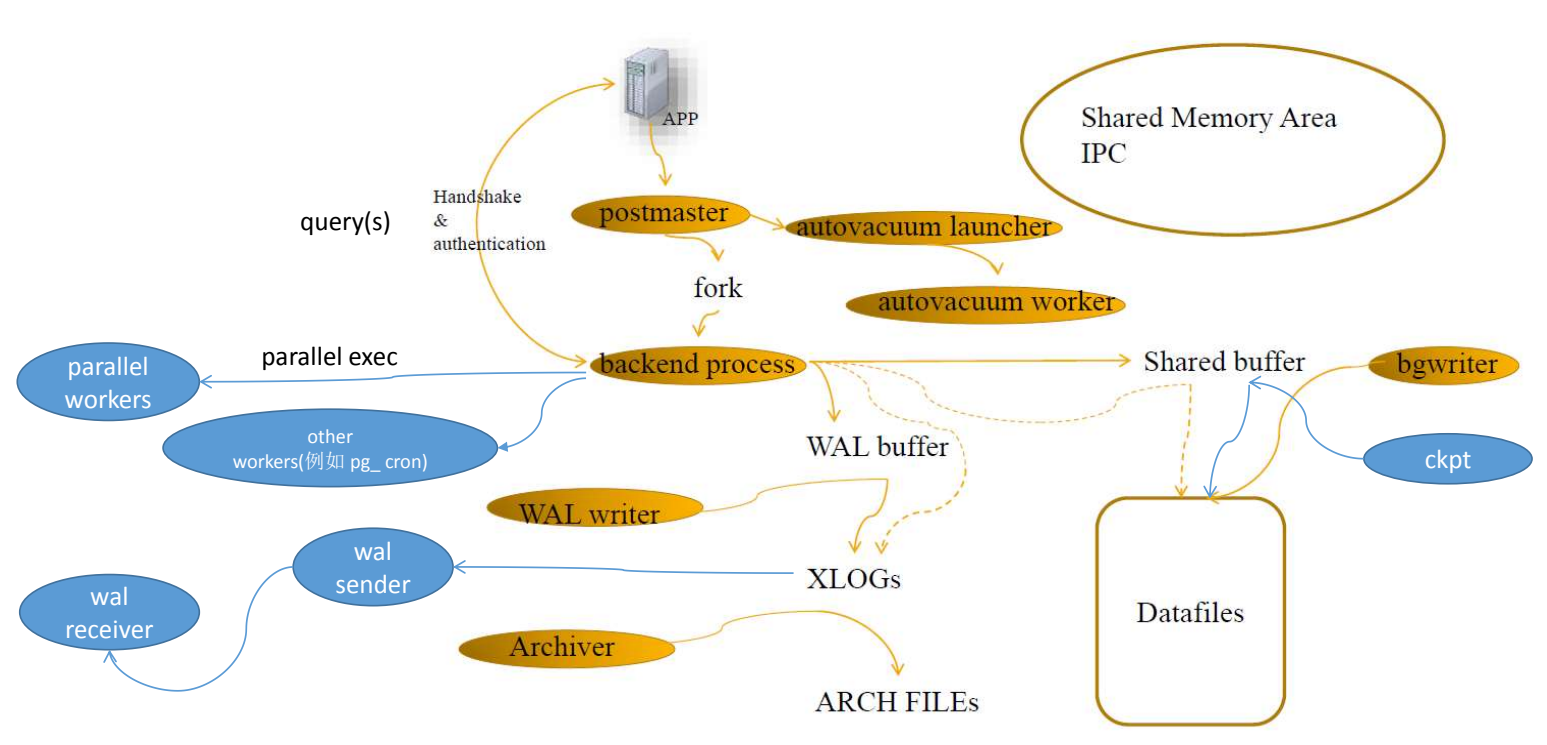
类似于Oracle的redo,PostgreSQL的redo文件被称为WAL文件或XLOG文件,存放在 $PGDATA/pg_xlog或 $PGDATA/pg_wal目录中(PostgreSQL从10版本开始,将所用xlog相关的全部用wal替换了)。任何试图修改数据库数据的操作都会写一份日志到磁盘。
wal命名格式文件名称为16进制的24个字符组成,每8个字符一组,每组的意义如下:
1 2 3 4 5 6 7 8 | 00000001 00000000 000000E0 -------- -------- -------- 时间线 LogId LogSeg 时间线:英文为timeline,是以1开始的递增数字,如1,2,3... LogId:32bit长的一个数字,是以0开始递增的数字,如0,1,2,3... LogSeg:32bit长的一个数字,是以0开始递增的数字,如0,1,2,3... |
通过select pg_switch_xlog()或select pg_switch_wal();可以手动切换xlog/wal日志。
PG10之前版本:select pg_switch_xlog();
PG10开始版本:select pg_switch_wal();
wal日志即write ahead log预写式日志,简称wal日志。wal日志可以说是PostgreSQL中十分重要的部分,相当于oracle中的redo日志。
当数据库中数据发生变更时:
change发生时:先要将变更后内容计入wal buffer中,再将变更后的数据写入data buffer;
commit发生时:wal buffer中数据刷新到磁盘;
checkpoint发生时:将所有data buffer刷新的磁盘。
可以想象,如果没有wal日志,那么数据库中将会发生什么?
首先,当我们在数据库中更新数据时,如果没有wal日志,那么每次更新都会将数据刷到磁盘上,并且这个动作是随机i/o,性能可想而知。并且没有wal日志,关系型数据库中事务的ACID如何保证呢?
因此wal日志重要性可想而知。其中心思想就是:先写入日志文件,再写入数据。
说到checkpoint,我们再来看看哪些情况会触发数据库的checkpoing:
1.手动执行CHECKPOINT命令;
2.执行需要检查点的命令(例如pg_start_backup 或pg_ctl stop|restart等等);
3.达到检查点配置时间(checkpoint_timeout);
4.max_wal_size已满。
其中1和2两点都和数据库的配置无关,我们暂时先不看,这里先介绍下checkpoint_timeout和max_wal_size两个参数。
checkpoint_timeout: 自动 WAL 检查点之间的最长时间,以秒计。合理的范围在 30 秒到 1 天之间。默认是 5 分钟(5min)。增加这个参数的值会增加崩溃恢复所需的时间。
1 2 3 4 5 | bill@bill=>show checkpoint_timeout ; checkpoint_timeout -------------------- 30min (1 row) |
max_wal_size: 在自动 WAL检查点之间允许WAL 增长到的最大尺寸。这是一个软限制,在特殊的情况 下 WAL 尺寸可能会超过max_wal_size, 例如在重度负荷下、archive_command失败或者高的 wal_keep_segments设置。默认为 1 GB。增加这个参数可能导致崩溃恢复所需的时间。
1 2 3 4 5 | bill@bill=>show max_wal_size ; max_wal_size -------------- 2GB (1 row) |
和max_wal_size相对应的还有个min_wal_size,这里简单介绍下:
只要 WAL 磁盘用量保持在这个设置之下,在检查点时旧的 WAL文件总是被回收以便未来使用,而不是直接被删除。
可能对oracle熟悉的人会觉得wal日志和redo还是有些不同,没错,oracle中redo是固定几个redo日志文件,然后轮着切换去写入,因此我们常常会在io高的数据库中看到redo切换相关的等待事件。
而在pg中wal日志是动态切换,从pg9.6开始采用这种模式。和oracle不同的是,pg中这种动态wal切换步骤是这样的:单个wal日志写满(默认大小16MB,编译数据库时指定)继续写下一个wal日志,直到磁盘剩余空间不足min_wal_size时才会将旧的 WAL文件回收以便继续使用。
但是这种模式有一个弊端就是如果在checkpoint之前产生了大量的wal日志就会导致发生checkpoint时对性能的影响巨大,因此pg中还有一个参数checkpoint_completion_target
来进行调整。
checkpoint_completion_target: 指定检查点完成的目标,作为检查点之间总时间的一部分。默认是 0.5。
什么意思呢,假如我的checkpoint_timeout设置是30分钟,而wal生成了10G,那么设置成0.5就允许我在15分钟内完成checkpoint,调大这个值就可以降低checkpoint对性能的影响,但是万一数据库出现故障,那么这个值设置越大数据就越危险。
当数据库中数据发生变更时: change发生时:先要将变更后内容计入wal buffer中,再将变更后的数据写入data buffer; commit发生时:wal buffer中数据刷新到磁盘; checkpoint发生时:将所有data buffer刷新的磁盘。
如果没有wal日志,那么数据库中将会发生什么? 首先,当我们在数据库中更新数据时,如果没有wal日志,那么每次更新都会将数据刷到磁盘上,并且这个动作是随机i/o,性能可想而知。并且没有wal日志,关系型数据库中事务的ACID如何保证呢? 因此wal日志重要性可想而知。其中心思想就是:先写入日志文件,再写入数据。
说到checkpoint,我们再来看看哪些情况会触发数据库的checkpoing:
1.手动执行CHECKPOINT命令;
2.执行需要检查点的命令(例如pg_start_backup 或pg_ctl stop|restart等等);
3.达到检查点配置时间(checkpoint_timeout);
4.max_wal_size已满。
checkpoint_timeout: 自动 WAL 检查点之间的最长时间,以秒计。合理的范围在 30 秒到 1 天之间。默认是 5 分钟(5min)。增加这个参数的值会增加崩溃恢复所需的时间。
max_wal_size: 在自动 WAL检查点之间允许WAL 增长到的最大尺寸。这是一个软限制,在特殊的情况 下 WAL 尺寸可能会超过max_wal_size, 例如在重度负荷下、archive_command失败或者高的 wal_keep_segments设置。默认为 1 GB。增加这个参数可能导致崩溃恢复所需的时间。( wal_keep_segments用于指定pg_wal目录中保存的过去的wal文件(wal 段)的最小数量,以防备用服务器在进行流复制时需要。)
和max_wal_size相对应的还有个min_wal_size,只要 WAL 磁盘用量保持在这个设置之下,在检查点时旧的 WAL文件总是被回收以便未来使用,而不是直接被删除。
wal切换步骤是这样的:单个wal日志写满(默认大小16MB,编译数据库时指定)继续写下一个wal日志,直到磁盘剩余空间不足min_wal_size时才会将旧的 WAL文件回收以便继续使用。但是这种模式有一个弊端就是如果在checkpoint之前产生了大量的wal日志就会导致发生checkpoint时对性能的影响巨大,因此pg中还有一个参数checkpoint_completion_target 来进行调整。
checkpoint_completion_target: 指定检查点完成的目标,作为检查点之间总时间的一部分。默认是 0.5。假如我的checkpoint_timeout设置是30分钟,而wal生成了10G,那么设置成0.5就允许我在15分钟内完成checkpoint,调大这个值就可以降低checkpoint对性能的影响,但是万一数据库出现故障,那么这个值设置越大数据就越危险。
总结:大多数检查点应该是基于时间的,即由checkpoint_timeout触发。 性能(不频繁检查点)与恢复所需时间(频繁检查点)之间需要抉择: 值在15-30分钟之间是比例合适的,但到1小时不是什么坏事。 在决定checkpoint_timeout后,通过估计WAL的数量选择max_wal_size。 设置checkpoint_completion_target以便内核将数据刷新到磁盘的时间足够(但不是太多)
总结:大多数检查点应该是基于时间的,即由checkpoint_timeout触发。
性能(不频繁检查点)与恢复所需时间(频繁检查点)之间需要抉择:
值在15-30分钟之间是比例合适的,但到1小时不是什么坏事。
在决定checkpoint_timeout后,通过估计WAL的数量选择max_wal_size。
设置checkpoint_completion_target以便内核将数据刷新到磁盘的时间足够(但不是太多)。
切换日志
pg_switch_wal()或pg_switch_xlog()强制服务器切换到一个新的预写式日志文件,这允许对当前文件进行归档(假设你正在使用连续归档)。 其结果是在刚刚完成的预写式日志文件中结束预写式日志位置加1。 如果自从上次预写式日志切换以来没有WAL日志活动,则pg_switch_wal将不做任何操作,并返回当前正在使用的WAL日志文件的起始位置。默认情况下该函数仅限超级用户使用,但可以授权其他用户执行该函数。
pg_switch_xlog()用于PG 10之前,从PG 10开始切换归档日志使用pg_switch_wal()。
另外,PG也提供了相应的函数根据LSN获取日志文件名:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 | postgres=# select pg_switch_wal(); pg_switch_wal --------------- 0/F000000 (1 row) postgres=# SELECT pg_walfile_name(pg_current_wal_lsn()); pg_walfile_name -------------------------- 00000001000000000000000E (1 row) postgres=# SELECT pg_walfile_name('0/F000000'); pg_walfile_name -------------------------- 00000001000000000000000E (1 row) postgres=# select pg_switch_wal(); pg_switch_wal --------------- 0/10000000 (1 row) postgres=# select pg_switch_wal(); pg_switch_wal --------------- 0/10000000 (1 row) postgres=# select pg_switch_wal(); pg_switch_wal --------------- 0/10000000 (1 row) postgres=# SELECT pg_walfile_name(pg_current_wal_lsn()); pg_walfile_name -------------------------- 00000001000000000000000F (1 row) postgres=# SELECT pg_walfile_name('0/10000000'); pg_walfile_name -------------------------- 00000001000000000000000F (1 row) |
配置归档
必须重启:
1 2 3 4 5 6 7 8 | wal_level='replica' archive_mode='on' archive_command='test ! -f /postgresql/archive/%f && cp %p /postgresql/archive/%f' restore_command='cp /pg13/archive/%f %p' archive_timeout=10 select * from pg_settings where name in ('archive_mode','archive_command'); |
在生产环境,为了保证数据高可用性,通常需要设置归档,所谓的归档,其实就是把pg_wal里面的日志备份出来,当系统故障后可以通过归档的日志文件对数据进行恢复:
配置归档需要开启如下参数:
wal_level = replica (pg13默认已经开启replica)
该参数的可选的值有minimal,replica和logical,wal的级别依次增高,在wal的信息也越多。由于minimal这一级别的wal不包含从基础的备份和wal日志重建数据的足够信息,在该模式下,无法开启wal日志归档archive_mode = on
上述参数为on,表示打开归档备份,可选的参数为on,off,always 默认值为off,所以要手动打开archive_command = 'test ! -f /mnt/server/archivedir/%f && cp %p /mnt/server/archivedir/%f'
该参数的默认值是一个空字符串,他的值可以是一条shell命令或者一个复杂的shell脚本。在shell脚本或命令中可以用 “%p” 表示将要归档的wal文件包含完整路径的信息的文件名,用“%f” 代表不包含路径信息的wal文件的文件名archive_timeout表示只对完整的WAL段调用archive_command。因此,如果你的服务器只产生很少的WAL流量(或者它产生的空闲时间很短),则在事务完成和将其安全记录到归档存储之间可能会有很长的延迟。要限制可以保存的未归档数据的数量,可以设置archive_timeout强制服务器定期切换到新的WAL段文件。
请注意,由于强制切换而提前关闭的归档文件的长度仍然与完全完整的文件的长度相同。因此,使用非常短的archive_timeout是不明智的-它将使您的存档存储空间过大。一分钟左右的archive_timeout设置通常是合理的。如果你希望数据能被更快地从主服务器上复制下来,你应该考虑使用流复制而不是归档。如果指定值时没有单位,则以秒为单位。这个参数只能在postgresql.conf文件中或在服务器命令行上设置。
该参数只能在postgresql.conf文件或服务器命令行中设置。
注意:wal_level和archive_mode参数修改都需要重新启动数据库才可以生效。而修改archive_command则不需要。所以一般配置新系统时,无论当时是否需要归档,这要建议将这两个参数开启
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 | postgres=# select * from pg_settings where name in ('archive_mode','archive_command'); name | setting | unit | category | short_desc | extra_desc | context | vartype | source | min_val | max_val | enumvals | boot_val | reset_val | sourcefile | sourceline | pending_restart -----------------+------------+------+-----------------------------+-------------------------------------------------------------------+------------+------------+---------+---------+---------+---------+-----------------+----------+-----------+------------+------------+----------------- archive_command | (disabled) | | Write-Ahead Log / Archiving | Sets the shell command that will be called to archive a WAL file. | | sighup | string | default | | | | | | | | f archive_mode | off | | Write-Ahead Log / Archiving | Allows archiving of WAL files using archive_command. | | postmaster | enum | default | | | {always,on,off} | off | off | | | f (2 rows) postgres=# alter system set archive_command='test ! -f /postgresql/archive/%f && cp %p /postgresql/archive/%f'; ALTER SYSTEM postgres=# alter system set archive_mode='on'; ALTER SYSTEM postgres=# select * from pg_settings where name in ('archive_mode','archive_command'); name | setting | unit | category | short_desc | extra_desc | context | vartype | source | min_val | max_val | enumvals | boot_val | reset_val | sourcefile | sourceline | pending_restart -----------------+------------+------+-----------------------------+-------------------------------------------------------------------+------------+------------+---------+---------+---------+---------+-----------------+----------+-----------+------------+------------+----------------- archive_command | (disabled) | | Write-Ahead Log / Archiving | Sets the shell command that will be called to archive a WAL file. | | sighup | string | default | | | | | | | | f archive_mode | off | | Write-Ahead Log / Archiving | Allows archiving of WAL files using archive_command. | | postmaster | enum | default | | | {always,on,off} | off | off | | | f (2 rows) postgres=# select * from pg_settings where name in ('archive_mode','archive_command'); FATAL: terminating connection due to administrator command server closed the connection unexpectedly This probably means the server terminated abnormally before or while processing the request. The connection to the server was lost. Attempting reset: Succeeded. psql (13.3, server 13.4 (Debian 13.4-1.pgdg100+1)) postgres=# select * from pg_settings where name in ('archive_mode','archive_command'); name | setting | unit | category | short_desc | extra_desc | context | vartype | source | min_val | max_val | enumvals | boot_val | reset_val | sourcefile | sourceline | pending_restart -----------------+------------------------------------------------------------------+------+-----------------------------+-------------------------------------------------------------------+------------+------------+---------+--------------------+---------+---------+-----------------+----------+------------------------------------------------------------------+-----------------------------------------------+------------+----------------- archive_command | test ! -f /postgresql/archive/%f && cp %p /postgresql/archive/%f | | Write-Ahead Log / Archiving | Sets the shell command that will be called to archive a WAL file. | | sighup | string | configuration file | | | | | test ! -f /postgresql/archive/%f && cp %p /postgresql/archive/%f | /var/lib/postgresql/data/postgresql.auto.conf | 4 | f archive_mode | on | | Write-Ahead Log / Archiving | Allows archiving of WAL files using archive_command. | | postmaster | enum | configuration file | | | {always,on,off} | off | on | /var/lib/postgresql/data/postgresql.auto.conf | 5 | f (2 rows) postgres=# select pg_switch_wal(); pg_switch_wal --------------- 0/15EDA18 (1 row) root@lhrpg134:/var/lib/postgresql/data/pg_wal# ls -l total 32772 -rw------- 1 postgres postgres 16777216 Sep 23 11:14 000000010000000000000001 -rw------- 1 postgres postgres 16777216 Sep 23 11:14 000000010000000000000002 drwx------ 2 postgres postgres 4096 Sep 23 11:14 archive_status |
如果开启了归档,则在归档路径下的archive_status目录里,会有类似000000010000000000000002.ready和000000010000000000000003.done的文件。
.ready表示XLOG文件已写满,可以调用归档命令了,.done表示已归档完成。开启了归档后,只有归档成功的pg_xlog文件才会被清除。在每次归档命令被执行后,会触发清除标签的动作,在执行检查点时,也会触发清除归档标签文件的动作。
影响wal保存的最大个数的参数
checkpoint_segments和wal_keep_segments,checkpoint_completion_target
1 2 3 4 5 | 通常地说,WAL最大个数不超过: ( 2 + checkpoint_completion_target ) * checkpoint_segments + 1 在流复制环境下,WAL最大数不超过: wal_keep_segments + checkpoint_segments + 1 |
超过的话会自动清理。
默认的WAL segments为16M,这个参数在PG编译执行 ./configure 时,指定“–with-wal-segsize=target_value”参数设置。从PG 11开始,可以通过initdb 和 pg_resetwal 调整WAL文件大小,参考:https://www.dbaup.com/postgresql11xiugaiwal-segsizedaxiao.html
自动清理wal日志
一般来说,设置自动清理archive_log 可以在配置文件中添加:
1 | archive_cleanup_command = 'pg_archivecleanup archivelocation %r' |
示例: