合 Oracle等待事件详解
- 等待事件的源起
- 分类
- Classes of Wait Events
- Descriptions of Common Wait Event Parameters
- 重要等待事件
- User I/O类型
- db file sequential read(数据文件顺序读)
- 例子
- db file scattered read(数据文件离散读)
- db file parallel read
- db file single write
- direct path read(直接路径读、DPR)
- 串行全表扫描(Serial Table Scan)--Oracle 11g全表扫描以Direct Path Read方式执行
- Oracle 11g新特性触发Direct Path Read 等待事件案例
- direct path write(直接路径写、DRW)
- direct path read temp、direct path write temp
- read by other session
- read by other session等待事件模拟
- local write wait
- 所有User I/O类等待事件的总结
User I/O类型
等待事件的源起
谈到等待事件,必然会提到一种流行的诊断方法论OWI,即Oracle Wait Interface.
等待事件的概念大概是从Oracle 7.0.12中引入的,刚引入的时候大约有100多个等待事件,在Oracle 8.0中这个数目增大到了大约150个,在Oracle 8i中大约有220个事件,在Oracle 9i中大约有400多个等待事件,在Oracle 10gR2中,大约有800多个等待事件,在11gR2中约有1000多个等待事件。随着等待事件的逐步完善,也能够反映出对于问题的诊断粒度越来越细化。
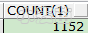
虽然不同版本和组件安装可能会有不同数目的等待事件,但是这些等待事件都可以通过查V$EVENT_NAME视图获得:
10.2.0.5版本:
select count(1) from v$event_name;

11g:
select count(1) from v$event_name;
分类
ORACLE的等待事件,主要可以分为两类,即空闲(IDLE)等待事件和非空闲(NON-IDLE)等待事件。
1). 空闲等待事件指ORACLE正等待某种工作,在诊断和优化数据库的时候,不用过多注意这部分事件。
2). 非空闲等待事件专门针对ORACLE的活动,指数据库任务或应用运行过程中发生的等待,这些等待事件是在调整数据库的时候需要关注与研究的。
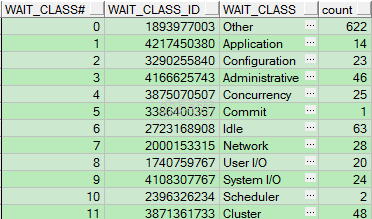
下面来看一下ORACLE中等待事件的主要分类及各类等待事件的个数:
SELECT a.INST_ID, A.EVENT, COUNT(1)
FROM gv$session a
where a.username is not null
and a.STATUS = 'ACTIVE'
AND A.WAIT_CLASS\<>'Idle'
GROUP BY a.INST_ID,A.EVENT;
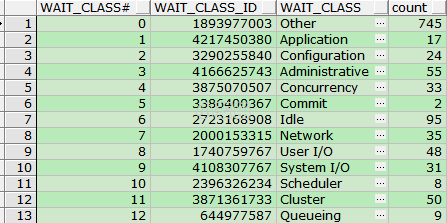
SELECT wait_class#,
wait_class_id,
wait_class,
COUNT(*) AS "count"
FROM v$event_name
GROUP BY wait_class#,
wait_class_id,
wait_class
ORDER BY wait_class#;
11g:
常见的空闲事件有:
• dispatcher timer
• lock element cleanup
• Null event
• parallel query dequeue wait
• parallel query idle wait - Slaves
• pipe get
• PL/SQL lock timer
• pmon timer- pmon
• rdbms ipc message
• slave wait
• smon timer
• SQL*Net break/reset to client
• SQL*Net message from client
• SQL*Net message to client
• SQL*Net more data to client
• virtual circuit status
• client message
一些常见的非空闲等待事件有:
• db file scattered read
• db file sequential read
• buffer busy waits
• free buffer waits
• enqueue
• latch free
• log file parallel write
• log file sync
This appendix contains the following topics:
■ Classes of Wait Events
■ Descriptions of Common Wait Event Parameters
■ Descriptions of Wait Events
Information about wait events is displayed in three dynamic performance views:
■ V$SESSION_WAIT displays the events for which sessions have just completed waiting or are currently waiting.
■ V$SYSTEM_EVENT displays the total number of times all the sessions have waited for the events in that view.
■ V$SESSION_EVENT is similar to V$SYSTEM_EVENT, but displays all waits for each
session.
Many of these wait events are tied to the internal implementation of Oracle and
therefore are subject to change or deletion without notice. Application developers
should be aware of this and write their codeto tolerate missing or extra wait events.
The following SQL statement displays an alphabetical list of all Oracle wait events and the wait class to which they belong:
SQL> SELECT name, wait_class FROM V$EVENT_NAME ORDER BY name;
Classes of Wait Events
Every wait event belongs to a class of wait event. The following list describes each of the wait classes.
Administrative
Waits resulting from DBA commands that cause users to wait (for example, an index rebuild)
Application
Waits resulting from user application code (for example, lock waits caused by row level locking or explicit lock commands)
Cluster
Waits related to Real Application Clusters resources (for example, global cache resources such as 'gc cr block busy')
Commit
This wait class only comprises one wait event - wait for redo log write confirmation after a commit (that is, 'log file sync')
Concurrency
Waits for internal database resources (for example, latches)
Configuration
Waits caused by inadequate configuration of database or instance resources (for example, undersized log file sizes, shared pool size)
Idle
Waits that signify the session is inactive, waiting for work (for example, 'SQL*Net message from client')
Network
Waits related to network messaging (for example, 'SQL*Net moredata to dblink')
Other
Waits which should not typically occur on a system (for example, 'wait for EMON to spawn')
Queue
Contains events that signify delays in obtaining additional data in a pipelined environment. The time spent on these wait events indicates inefficiency or other problems in the pipeline. It affects features such as Oracle Streams, parallel queries, or DBMS_PIPEPL/SQL packages.
Scheduler
Resource Manager related waits (for example, 'resmgr: become active')
System I/O
Waits for background process I/O (for example, DBWR wait for 'db file parallel write')
User I/O
Waits for user I/O (for example 'db file sequential read')
Descriptions of Common Wait Event Parameters
Oracle® Database Reference 11g Release 2 (11.2) E40402-09
Descriptions of Common Wait Event Parameters
This section provides descriptions of some of the more common wait event parameters.
block#
This is the block number of the block for which Oracle needs to wait. The block number is relative to the start of the file. Tofind the object to which this block belongs, issue the following SQL statement:
select segment_name, segment_type, owner, tablespace_name
from dba_extents
where file_id = file#
and block#
between block_id and block_id + blocks - 1;
blocks
The number of blocks that is being either read from or written to the file. The block
size is dependent on the file type:
■ Database files have a block size of DB_BLOCK_SIZE
■ Logfiles and control files have a block size that is equivalent to the physical block size of the platform
break?
If the value for this parameter equals 0, a reset was sent to the client. A nonzero value indicates that a break was sent to the client.
class
The class of the block describes how the contents of the block are used. For example, class 1 represents data block, and class 4 represents segment header.
dba
The initials "dba" represents the data block address, which consists of a file number and a block number.
driver id
The address of the disconnect function of the driver that is currently being used.
file#
The following query returns the name of the database file:
select *
from v$datafile
where file# = file#;
id1
The first identifier (id1) of the enqueue or global lock takes its value from P2 or P2RAW. The meaning of the identifier depends on the name (P1).
id2
The second identifier (id2) of the enqueue or global lock takes its value from P3 or P3RAW. The meaning of the identifier depends on the name (P1).
le
The relative index number into V$GC_ELEMENT.
mode
The mode is usually stored in the low order bytes of P1 or P1RAW and indicates the mode of the enqueue or global lock request.This parameter has one of the following values:
Table C-1 Lock Mode Values
| Mode Value | Description |
|---|---|
| 1 | Null mode |
| 2 | Sub-Share |
| 3 | Sub-Exclusive |
| 4 | Share |
| 5 | Share/Sub-Exclusive |
| 6 | Exclusive |
Use the following SQL statement to retrieve the name of the lock and the mode of the lock request:
select chr(bitand(p1,-16777216)/16777215)||
chr(bitand(p1, 16711680)/65535) "Lock",
bitand(p1, 65535) "Mode"
from v$session_wait
where event = 'DFS enqueue lock acquisition';
name and type
The name or "type" of the enqueue or globallock can be determined by looking at the two high order bytes of P1 or P1RAW. The name is always two characters. Use the following SQL statement to retrieve the lock name.
select chr(bitand(p1,-16777216)/16777215)||
chr(bitand(p1,16711680)/65535) "Lock"
from v$session_wait
where event = 'DFS enqueue lock acquisition';
namespace
The name of the object namespace as it is displayed in V$DB_OBJECT_CACHE view.
requests
The number of I/Os that are "requested." This differs from the number of blocks in that one request could potentially contain multiple blocks.
session#
The number of the inactive session. Use the following SQL statement to find more information about the session:
select *
from v$session
where sid = session#;
waited
This is the total amount of time the sessionhas waited for this session to terminate.
重要等待事件
一些常见的重要的等待事件:
1)数据文件I/O相关的等待事件:
- db file sequential read
- db file scattered read
- db file parallel read
- direct path read
- direct path write
2)控制文件I/O相关的等待事件:
- control file parallel write
- control file sequential read
- control file single write
3)重做日志文件I/O相关的等待事件:
- log file parallel write
- log file sync
- log file sequential read
- log file single write
- switch logfile command
- log file switch completion
- log file switch (clearing log file)
- log file switch (checkpoint incomplete)
- log switch/archive
- log file switch (archiving needed)
4)高速缓存区I/O相关的等待事件:
- db file parallel write
- db file single write
- write complete waits
- free buffer waits
User I/O类型
SELECT * FROM V$EVENT_NAME A WHERE A.WAIT_CLASS = 'User I/O';
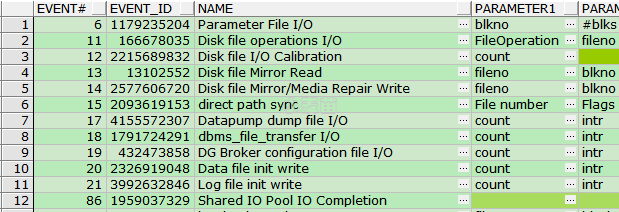
11g User I/O大约有84个。
db file sequential read(数据文件顺序读)
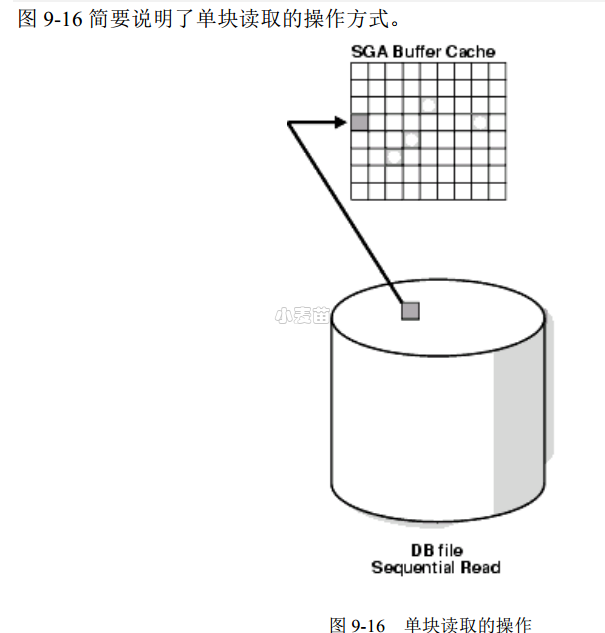
db file sequential read这个等待事件在实际生产库非常常见,是个与User I/O相关的等待事件,通常显示与单个数据块相关的读取操作,在大多数情况下,读取一个索引块或者通过索引读取一个数据块时,都会记录这个等待。当Oracle 需要每次I/O只读取单个数据块这样的操作时,会产生这个等待事件。最常见的情况有索引的访问(除IFFS外的方式),回滚操作,以ROWID的方式访问表中的数据,重建控制文件,对文件头做DUMP等。如果db file scattered read事件是伴随Multi Block I/O发生的等待事件,那db file sequential read事件就是伴随Single Block I/O发生的等待事件。每次发生Single Block I/O时,就会发生一次db file sequential read事件的等待。Single Block I/O可以发生在从文件读取一个块的所有工作上,一般在索引扫描、通过ROWID的表扫描、读取控制文件和文件头时发生。
在V$SESSION_WAIT这个视图里面,这个等待事件有三个参数P1、P2、P3,其中P1代表Oracle要读取的文件的绝对文件号即File#,P2代表Oracle从这个文件中开始读取的起始数据块的BLOCK号即Block#,P3代表Oracle从这个文件开始读取的BLOCK号后读取的BLOCK数量即Blocks,通常这个值为1,表明是单个BLOCK被读取,如果这个值大于1,则是读取了多个BLOCK,这种多BLOCK读取常常出现在早期的Oracle版本中从临时段中读取数据的时候。
这个等待事件有三个参数:
File#: 要读取的数据块所在数据文件的文件号。
Block#: 要读取的起始数据块号。
Blocks:要读取的数据块数目(这里应该等于1)。
SELECT *
FROM v$event_name
WHERE NAME = 'db file sequential read';

db file sequential read等待使性能出现问题,这些性能问题大多数发生在低效的索引扫描、行迁移、行链接引发附加的I/O过程中。
1、应用程序层
低效的sql语句或低效的索引扫描经常被使用时,因不必要的物理I/O增加,可能增加db file sequential read等待。使用选择性较差的索引是发生db file sequential read等待的主要原因。
2、oracle内存层
如果高速缓冲区过小,就会反复发生物理I/O,因此可能增加db file sequential read等待,这时同时发生free buffer waits等待的概率较高。如果大量发生free buffer waits等待,应该考虑扩展高速缓存区的大小。始终要考虑利用多重缓冲池,有效使用高速缓存区。利用多重缓冲池减少db file sequential read等到的原理,与减少db file scattered read等待的原理相同。
3、OS/裸设备层
如果sql优化或高速缓存区优化、重建表也不能解决问题,就应该怀疑I/O系统本身的性能。将db file sequential read事件的等待次数和等待时间比较后,如果平均等待时间长,缓慢的I/O系统成为原因的可能性高。之前也讨论过,I/O系统上的性能问题在多钟情况下均会发生,因此需要充分调查各种因素。
利用v$filestat视图,可分别获得各数据文件关于Multi Block I/O和Single Block I/O的活动信息。
SELECT F.FILE#,
F.NAME,
S.PHYRDS,
S.PHYBLKRD,
S.READTIM, --所有的读取工作信息
S.SINGLEBLKRDS,
S.SINGLEBLKRDTIM, --SINGLE BLOCK I/O
(S.PHYBLKRD - S.SINGLEBLKRDS) AS MULTIBLKRD, --MULTI BLOCK I/O次数
(S.READTIM - S.SINGLEBLKRDTIM) AS MULTIBLKRDTIM, --MULTI BLOCK I/O时间
ROUND(S.SINGLEBLKRDTIM /
DECODE(S.SINGLEBLKRDS, 0, 1, S.SINGLEBLKRDS),
3) AS SINGLEBLK_AVGTIM, --SINGLE BLOCK I/O 平均等待时间(CS)
ROUND((S.READTIM - S.SINGLEBLKRDTIM) /
NULLIF((S.PHYBLKRD - S.SINGLEBLKRDS), 0),
3) AS MULTIBLK_AVGTIM --MULTI BLOCK I/O 平均等待时间(CS)
FROM V$FILESTAT S, V$DATAFILE F
WHERE S.FILE# = F.FILE#;
如果特点文件上平均执行时间表现的过高,则应该通过提高该文件所在的I/O系统的性能,以此改善性能。没有关于Multi Block I/O的最合理的平均等待时间值,但一般应该维持10微妙左右的平均等待时间。
在Oracle 10g中,这个等待事件被归入User I/O一类:
这一事件通常显示与单个数据块相关的读取操作(如索引读取)。如果这个等待事件比较显著,可能表示在多表连接中,表的连接顺序存在问题,可能没有正确的使用驱动表;或者可能索引的使用存在问题,不加选择地进行索引,并非索引总是最好的选择。
还有一种特殊的情况是,全表扫描过程还会产生单块读的情况有,读UNDO块。可以参考最后的老熊文章的例子http://blog.itpub.net/26736162/viewspace-2123513/。对于这种情况的解决办法是加索引,或等大事务执行完成后再执行SQL。
这里的sequential也并非指的是Oracle 按顺序的方式来访问数据,和db file scattered read一样,它指的是读取的数据块在内存中是以连续的方式存放的。
在大多数的情况下读取一个索引数据的BLOCK或者通过索引读取数据的一个BLOCK的时候都会去要读取相应的数据文件头的BLOCK。在早期的版本中会从磁盘中的排序段读取多个BLOCK到高速缓存区的连续的缓存中。
在大多数情况下,通过索引可以更为快速地获取记录,所以对于一个编码规范、调整良好的数据库,这个等待事件很大通常是正常的。有时候这个等待过高和存储分布不连续、连续数据块中部分被缓存有关,特别对于DML频繁的数据表,数据以及存储空间的不连续可能导致过量的单块读,定期的数据整理和空间回收有时候是必须的。但是在很多情况下,使用索引并不是最佳的选择,比如读取较大表中大量的数据,全表扫描可能会明显快于索引扫描,所以在开发中就应该注意,对于这样的查询应该避免使用索引扫描。
如果这个等待事件在整个等待时间中占主要的部分,可以采用以下的几种方法来调整数据库。
方法一:从AWR的报告中的"SQL ordered by Reads"部分或者从V$SQL视图中找出读取物理磁盘I/O最多的几个SQL语句,优化这些SQL语句以减少对I/O的读取需求。
如果有Index Range scans,但是却使用了不该用的索引,就会导致访问更多的BLOCK,这个时候应该强迫使用一个可选择的索引,使访问同样的数据尽可能的少的访问索引块,减少物理I/O的读取;如果索引的碎片比较多,那么每个BLOCK存储的索引数据就比较少,这样需要访问的BLOCK就多,这个时候一般来说最好把索引rebuild,减少索引的碎片;如果被使用的索引存在一个很大的Clustering Factor,那么对于每个索引BLOCK获取相应的记录的时候就要访问更多表的BLOCK,这个时候可以使用特殊的索引列排序来重建表的所有记录,这样可以大大的减少Clustering Factor,例如:一个表有A,B,C,D,E五个列,索引建立在A,C上,这样可以使用如下语句来重建表:
CREATE TABLE TABLE_NAME AS SELECT * FROM old ORDER BY A,C;
此外,还可以通过使用分区索引来减少索引BLOCK和表BLOCK的读取。
方法二:如果不存在有问题的执行计划导致读取过多的物理I/O的特殊SQL语句,那么可能存在以下的情况:
数据文件所在的磁盘存在大量的活动,导致其I/O性能很差。这种情况下可以通过查看AWR报告中的"File I/O Statistics"部分或者V$FILESTAT视图找出热点的磁盘,然后将在这些磁盘上的数据文件移动到那些使用了条带集、RAID等能实现I/O负载均衡的磁盘上去。
使用如下的查询语句可以得到各个数据文件的I/O分布:
SELECT d.name NAME,
f.phyrds,
f.phyblkrd,
f.phywrts,
f.phyblkwrt,
f.readtim,
f.writetim
FROM v$filestat f,
v$datafile d
WHERE f.file# = d.file#
ORDER BY f.phyrds DESC,
f.phywrts DESC;
从Oracle9.2.0开始,我们可以从V$SEGMENT_STATISTICS视图中找出物理读取最多的索引段或者是表段,通过查看这些数据,可以清楚详细的看到这些段是否可以使用重建或者分区的方法来减少所使用的I/O。如果Statpack设置的level为7就会在报告中产生"Segment Statistics"的信息。
SELECT statistic_name,
COUNT(1)
FROM v$segment_statistics T
GROUP BY T.STATISTIC_NAME;
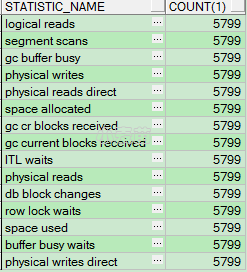
从上面的查询可以看到相应的统计名称,使用下面的查询语句就能得到读取物理I/O最多的段:
SELECT object_name,
object_type,
statistic_name,
VALUE
FROM v$segment_statistics
WHERE statistic_name = 'physical reads'
ORDER BY VALUE DESC;
方法三:如果不存在有问题的执行计划导致读取过多的物理I/O的特殊SQL语句,磁盘的I/O也分布的很均匀,这种时候我们可以考虑增大的高速缓存区。对于Oracle8i来说增大初始化参数DB_BLOCK_BUFFERS,让Statpack中的Buffer Cache的命中率达到一个满意值;对于Oracle9i来说则可以使用Buffer Cache Advisory工具来调整Buffer Cache;对于热点的段可以使用多缓冲池,将热点的索引和表放入到KEEP Buffer Pool中去,尽量让其在缓冲中被读取,减少I/O。
例子
老熊的一篇文章:常识之外,全表扫描为何产生大量db file sequential read单块读(常识之外:全表扫描为何产生大量 db file sequential read 单块读?http://blog.itpub.net/26736162/viewspace-2123513/):,介绍了,**全表扫描过程还会产生单块读的情况有,读UNDO块。**
db file scattered read(数据文件离散读)
在V$SESSION_WAIT这个视图里面,这个等待事件有三个参数P1、P2、P3,其中P1代表Oracle要读取的文件的绝对文件号,P2代表Oracle从这个文件中开始读取的BLOCK号,P3代表Oracle从这个文件开始读取的BLOCK号后读取的BLOCK数量。
SELECT *
FROM v$event_name
WHERE NAME IN ('db file sequential read', 'db file scattered read');

从V$EVENT_NAME视图可以看到,该等待事件有3个参数:
File#: 要读取的数据块所在数据文件的文件号。
Block#: 要读取的起始数据块号。
Blocks:需要读取的数据块数目。
这样就可以找到那个对象:
SELECT EVENT, P1, P2, P3, ROW_WAIT_OBJ#
FROM GV$SESSION
WHERE EVENT = 'db file scattered read';
SELECT OBJECT_NAME, OBJECT_TYPE
FROM DBA_OBJECTS
WHERE OBJECT_ID = ROW_WAIT_OBJ#;
起始数据块号加上数据块的数量,这意味着Oracle session正在等待多块连续读操作的完成。
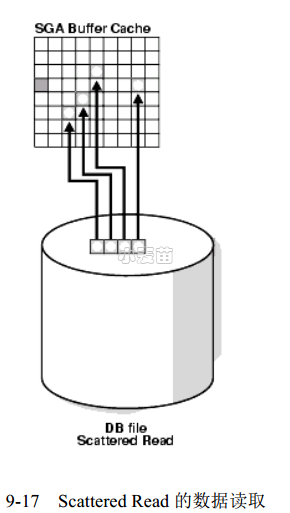
这个等待事件在实际生产库中经常可以看到,这是一个用户操作引起的等待事件,当用户发出每次I/O需要读取多个数据块这样的SQL 操作时或者说当Oracle从磁盘上读取多个BLOCK到不连续的高速缓存区的缓存中,会产生这个等待事件,这个事件表明用户进程正在读数据到Buffer Cache中,等待直到物理I/O调用返回。最常见的两种情况是全表扫描(FTS: Full Table Scan)和索引快速全扫描(IFFS: index fast full scan)。为保障性能,尽量一次读取多个块,这称为Multi Block I/O。每次执行Multi Block I/O,都会等待物理I/O结束,此时等待db file scattered read事件。根据经验,通常大量的db file scattered read等待可能意味着应用问题或者索引缺失。Oracle一次能够读取的最多的BLOCK数量是由初始化参数DB_FILE_MULTIBLOCK_READ_COUNT来决定。
这个名称中的scattered(发散),可能会导致很多人认为它是以scattered 的方式来读取数据块的,其实恰恰相反,当发生这种等待事件时,SQL的操作都是顺序地读取数据块的,比如FTS或者IFFS方式(如果忽略需要读取的数据块已经存在内存中的情况)。这里的scattered指的是读取的数据块在内存中的存放方式,他们被读取到内存中后,是以分散的方式存在在内存中,而不是连续的。
在生产环境之中,db file scattered read这个等待事件可能更为常见。DB File Scattered Read发出离散读,将存储上连续的数据块离散的读入到多个不连续的内存位置。Scattered Read通常是多块读,在Full Table Scan或Fast Full Scan等访问方式下使用。Scattered Read代表Full Scan,当执行Full Scan读取数据到Buffer Cache时,通常连续的数据在内存中的存储位置并不连续,所以这个等待被命名为Scattered Read(离散读)。每次多块读读取的数据块数量受初始化参数DB_FILE_MULTIBLOCK_READ_COUNT限制。
Oracle按照db_file_multiblock_read_count(以下简称MBRC)参数值进行Multi Block I/O。这个值每个OS都有最大的界定,可以通过如下方法确认最大值。
SQL> show parameter db_file_multiblock_read_count
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
db_file_multiblock_read_count integer 128
SQL> alter system set db_file_multiblock_read_count=100000; --试图变更为超大值
系统已更改。
SQL> show parameter db_file_multiblock_read_count;
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
db_file_multiblock_read_count integer 4096 --确认4096是一次可以读取的最多块数
oracle在执行FTS时也进行Single Block I/O。这时即便是FTS也会发生db file sequential read等待。FTS上使用Single Block I/O或读取比MBRC值小的块数的情况如下:
(1)达到区的界线时:如一个区有9个块,一次Multi Block I/O读取8个块,则一次以Multi Block I/O读取之后的剩余一个块通过Single Block I/O读取,如果剩下的块有两个,就会执行Multi Block I/O,而且只读取两个块。
(2)扫描过程中读取被缓存的块时:如读取8个块时,其中第三个块被缓存,oracle将前两个块通过Multi Block I/O读取,对于第三个块执行一次Logical I/O,剩下的5个块通过Multi Block I/O读取。这种情况经常发生时,因引发多次的I/O,可能成为FTS速度下降的原因。
(3)存在行链接时:在执行FTS的过程中,如果发现了行链接,oracle为了读取剩下的行引起的附加I/O,此时执行Single Block I/O。
图9-17简要说明了Scattered Read的数据读取方式。
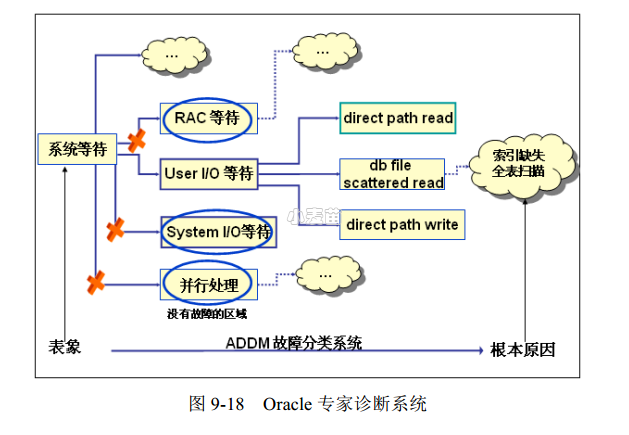
完成对等待事件的分类之后,Oracle 10g的ADDM可以很容易地通过故障树分析定位到问题所在,帮助用户快速发现数据库的瓶颈及瓶颈的根源,这就是Oracle的ADDM专家系统的设计思想。通过图9-18可以直观而清晰地看到这个等待模型和ADDM结合实现的Oracle专家诊断系统。
这种情况通常显示与全表扫描相关的等待。当数据库进行全表扫时,基于性能的考虑,数据会分散(scattered)读入Buffer Cache。如果这个等待事件比较显著,可能说明对于某些全表扫描的表,没有创建索引或者没有创建合适的索引,我们可能需要检查这些数据表已确定是否进行了正确的设置。然而这个等待事件不一定意味着性能低下,在某些条件下Oracle 会主动使用全表扫描来替换索引扫描以提高性能,这和访问的数据量有关,在CBO 下Oracle 会进行更为智能的选择,在RBO 下Oracle 更倾向于使用索引。因为全表扫描被置于LRU(Least Recently Used,最近最少适用)列表的冷端(cold end),对于频繁访问的较小的数据表,可以选择把他们Cache 到内存中,以避免反复读取。
在实际环境的诊断过程中,可以通过v$session_wait视图发现session的等待,再结合其他视图找到存在问题的SQL等根本原因,从而从根本上解决问题。在11g也可以直接通过v$session视图来查询等待事件。当这个等待事件比较显著时,也可结合v$session_longops动态性能视图来进行诊断,该视图记录了长时间(运行时间超过6秒的)运行的事务。
db file scattered read事件与db file sequential read事件相同,是oracle中最经常发生的等待事件。因为从数据文件读取块时只能执行Multi Block I/O或Single Block I/O。
1、应用程序层
需要筛选出主要发生db file scattered read等待的sql语句。如果不必要的执行FTS或Index Full San,修改sql语句或创建更合理的索引就可以解决。大量读取数据时多数情况下FTS性能更好。不是盲目的创建索引,而是要考虑相应的sql语句后,判断FTS有利,还是Index Full San有利。
2、oracle内存层
如果高速缓存区过小,就会反复需要物理I/O,相应的db file scattered read等待也会增加。这时free buffer waits等待事件一同出现的几率较高。FTS引起的db file scattered read等待的严重性不仅在于需要I/O,而且在于降低高速缓存区的效率,进而影响会话工作。从这种角度出发,处理FTS的有效方法之一就是使用多重缓冲池。读取一次后不再使用的数据,有必要保存到高速缓存区从而导致影响其他用户的工作吗?多重缓冲池虽然是有效管理高速缓存区的强有力的方法,但是遗憾的是没有被广泛使用。多重缓冲池从三个方面改善高速缓存区的性能。第一,将经常访问的对象保存与内存,进而将物理I/O最小化。第二,临时性数据所占用的内存被快速的重新使用,进而将内存的浪费最小化。第三,因为每个缓冲池各使用不同的cache buffers lru chain锁存器,所以有减少锁存器争用的效果。指定DEFAULT将适用默认的缓冲池。这个选项适用于没有分配给KEEP缓冲池和RECYCLE缓冲池的其它数据库对象。通常将经常访问的对象放入KEEP缓冲池中,指定KEEP将把数据块放入KEEP缓冲池中。维护一个适当尺寸的KEEP缓冲池可以使Oracle在内存中保留数据库对象而避免I/O操作。通常将偶尔访问的大表放入RECYCLE缓冲池中,指定RECYCLE将把数据块放入RECYCLE缓冲池中。一个适当尺寸的RECYCLE缓冲池可以减少默认缓冲池为RECYCLE缓冲池的数据库对象的数量,以避免它们占用不必要的缓冲空间。
有效使用FTS的另一种方法是将db_file_multiblock_read_count参数值提高。这个参数决定执行Multi Block I/O时一次读取的块数。因此这个值高,FTS速度相应也会提升,而且db file scattered read等待也会相应减少。将这个值在全系统级上设定得高,并不太妥当。最好是利用alter session set ...命令,只在执行sql语句期间提升这个值。因为这个值如果升高,有关FTS的费用会算的较低,可能会导致sql执行计划的变更。
较大的块也是提高FTS性能的方法。较大的块在如下两个方面改善FTS的性能。第一,增加一个块所包含的行数,这样相同大小的表时使用更少的块数,相应的Multi Block I/O次数也会减少。第二,块的大小较大,则发生行链接或行迁移的概率会降低,附加的I/O也随之降低。大部分OLTP系统上一般只是用标准块大小(8K)。但是经常扫描大量数据的OLAP上使用更大的块能改善性能。
3、oracle段层
需要检查,通过合理执行partition能否减少FTS范围。例如为获得100万个数据中10万个数据而执行FTS时,将10万个数据相应的范围利用partition分开,则可以将FTS的范围缩小至1/10。
4、OS/裸设备层
如果利用sql的优化或高速缓存区的优化也不能解决问题,就应该怀疑I/O系统本身的性能。将db file scattered read事件的等待次数和等待时间比较后,如果平均等待时间长,缓慢的I/O系统成为原因的可能性高。之前也讨论过,I/O系统上的性能问题在多钟情况下均会发生,因此需要充分调查各种因素。
利用v$filestat视图,可分别获得各数据文件关于Multi Block I/O和Single Block I/O的活动信息。
select f.file#,
f.name,
s.phyrds,
s.phyblkrd,
s.readtim, --所有的读取工作信息
s.singleblkrds,
s.singleblkrdtim, --Single Block I/O
(s.phyblkrd - s.singleblkrds) as multiblkrd, --Multi Block I/O次数
(s.readtim - s.singleblkrdtim) as multiblkrdtim, --Multi Block I/O时间
round(s.singleblkrdtim /
decode(s.singleblkrds, 0, 1, s.singleblkrds),
3) as singleblk_avgtim, --Single Block I/O 平均等待时间(cs)
round((s.readtim - s.singleblkrdtim) /
nullif((s.phyblkrd - s.singleblkrds), 0),
3) as multiblk_avgtim --Multi Block I/O 平均等待时间(cs)
from v$filestat s, v$datafile f
where s.file# = f.file#;
如果特点文件上平均执行时间表现的过高,则应该通过提高该文件所在的I/O系统的性能,以此改善性能。没有关于Multi Block I/O的最合理的平均等待时间值,但一般应该维持10微妙左右的平均等待时间。
如果这个等待事件在整个等待时间中占了比较大的比重,可以如下的几种方法来调整Oracle数据库:
方法一:找出执行全表扫描(FTS: Full Table Scan)和索引快速全扫描(IFFS: index fast full scan)扫描的SQL语句,判断这些扫描是否是必要的,是否导致了比较差的执行计划,如果是,则需要调整这些SQL语句,可以结合v$session_longops 动态性能视图来进行诊断,该视图中记录了长时间(运行时间超过6 秒的)运行的事物,可能很多是全表扫描操作。
从Oracle9i开始提供了一个视图V$SQL_PLAN用于记录当前系统Library Cache中SQL语句的执行计划,可以通过这个视图找到存在问题的SQL语句,即可以很快的帮助找到那些全表扫描或者Fast Full Index扫描的SQL语句,这个视图会自动忽略掉关于数据字典的SQL语句。
查找全表扫描的SQL语句可以使用如下语句:
通过V$SQL_PLAN和V$SQLTEXT联合,获得全表扫描的SQL语句
SELECT sql_text
FROM v$sqltext t,
v$sql_plan p
WHERE t.hash_value = p.hash_value
AND p.operation = 'TABLE ACCESS'
AND p.options = 'FULL'
ORDER BY p.hash_value,
t.piece;
获得全表扫描的对象
SELECT DISTINCT object_name,
object_owner
FROM v$sql_plan p
WHERE p.operation = 'TABLE ACCESS'
AND p.options = 'FULL'
AND object_owner = 'SYS';
查找Fast Full Index扫描的SQL语句可以使用如下语句:
SELECT sql_text
FROM v$sqltext t,
v$sql_plan p
WHERE t.hash_value = p.hash_value
AND p.operation = 'INDEX'
AND p.options = 'FULL SCAN'
ORDER BY p.hash_value, t.piece;
获得全索引扫描的对象
SELECT DISTINCT object_name,
object_owner
FROM v$sql_plan p
WHERE p.operation = 'INDEX'
AND p.options = 'FULL SCAN'
AND object_owner = 'SYS';
如果是Oracle8i的数据库,可以从V$SESSION_EVENT视图中找到关于这个等待事件的进程sid,然后根据sid来跟踪相应的会话的SQL。
select sid,event from v$session_event where event='db file sequential read'
或者可以查看物理读取最多的SQL语句的执行计划,看是否里面包含了全表扫描和Fast Full Index扫描。通过如下语句来查找物理读取最多的SQL语句:
select sql_text from (
select * from v$sqlarea
order by disk_reads)
where rownum\<=10;
方法二:有时候在执行计划很好情况下也会出现多BLOCK扫描的情况,这时可以通过调整Oracle数据库的多BLOCK的I/O,设置一个合理的Oracle初始化参数DB_FILE_MULTIBLOCK_READ_COUNT,尽量使得满足以下的公式:
DB_BLOCK_SIZE x DB_FILE_MULTIBLOCK_READ_COUNT = max_io_size of system
DB_FILE_MULTIBLOCK_READ_COUNT是指在全表扫描中一次能够读取的最多的BLOCK数量,这个值受操作系统每次能够读写最大的I/O限制,如果设置的值按照上面的公式计算超过了操作系统每次的最大读写能力,则会默认为max_io_size/db_block_size。例如DB_FILE_MULTIBLOCK_READ_COUNT设置为32,DB_BLOCK_SIZE为8K,这样每次全表扫描的时候能读取256K的表数据,从而大大的提高了整体查询的性能。设置这个参数也不是越大越好的,设置这个参数之前应该要先了解应用的类型,如果是OLTP类型的应用,一般来说全表扫描较少,这个时候设定比较大的DB_FILE_MULTIBLOCK_READ_COUNT反而会降低Oracle数据库的性能,因此CBO在某些情况下会因为多BLOCK读取导致COST比较低从而错误的选用全表扫描。
方法三: 通过对表和索引使用分区、将缓存区的LRU末端的全表扫描和IFFS扫描的的BLOCK放入到KEEP缓存池中等方法调整这个等待事件。
db file parallel read
SELECT *
FROM v$event_name
WHERE NAME IN ('db file parallel read');

在V$SESSION_WAIT这个视图里面,这个等待事件有三个参数P1、P2、P3,其中P1为files代表有多少个文件被读取所请求,P2为blocks代表总共有多少个BLOCK被请求,P3为requests代表总共有多少次I/O请求。
db file parallel read物理读等待事件涉及到的数据块均是不连续的,同时可以跨越extent,这点不像db file scattered read。
这是一个很容易引起误导的等待事件,实际上这个等待事件和并行操作(比如并行查询,并行DML)没有关系。这个事件发生在数据库恢复的时候,当有一些数据块需要恢复的时候,Oracle会以并行的方式把他们从数据文件中读入到内存中进行恢复操作。当Oracle从多个数据文件中并行的物理读取多个BLOCK到内存的不连续缓冲中(可能是高速缓存区或者是PGA)的时候可能就会出现这个等待事件。这种并行读取一般出现在恢复操作中或者是从缓冲中预取数据达到最优化(而不是多次从单个BLOCK中读取,buffer prefetch以优化多个单块读)。这个事件表明会话正在并行执行多个读取的需求。注意:在11g之前,这个等待事件发生在数据文件的恢复过程中,但11g中新增了prefetch的特性,所以也可能导致这个等待事件的产生。
如果在等待时间中这个等待事件占的比重比较大,可以按照处理db file sequential read等待事件的方法来处理这个事件。
若是由于prefetch引起的性能问题,我们可以通过添加隐含参数来解决该问题。可以参考blog:http://blog.itpub.net/26736162/viewspace-2123473
set pagesize 9999
set line 9999
col NAME format a40
col KSPPDESC format a50
col KSPPSTVL format a20
SELECT a.INDX,
a.KSPPINM NAME,
a.KSPPDESC,
b.KSPPSTVL
FROM x$ksppi a,
x$ksppcv b
WHERE a.INDX = b.INDX
and lower(a.KSPPINM) IN ('_db_block_prefetch_quota','_db_block_prefetch_limit','_db_file_noncontig_mblock_read_count');
ALTER SYSTEM SET "_db_block_prefetch_quota"=0 SCOPE=SPFILE SID='*';
ALTER SYSTEM SET "_db_block_prefetch_limit"=0 SCOPE=SPFILE SID='*';
ALTER SYSTEM SET "_db_file_noncontig_mblock_read_count"=0 SCOPE=SPFILE SID='*';
SYS@oraESKDB1> set pagesize 9999
SYS@oraESKDB1> set line 9999
SYS@oraESKDB1> col NAME format a40
SYS@oraESKDB1> col KSPPDESC format a50
SYS@oraESKDB1> col KSPPSTVL format a20
SYS@oraESKDB1> SELECT a.INDX,
2 a.KSPPINM NAME,
3 a.KSPPDESC,
4 b.KSPPSTVL
5 FROM x$ksppi a,
6 x$ksppcv b
7 WHERE a.INDX = b.INDX
8 and lower(a.KSPPINM) IN ('_db_block_prefetch_quota','_db_block_prefetch_limit','_db_file_noncontig_mblock_read_count');
INDX NAME KSPPDESC KSPPSTVL
---------- ---------------------------------------- -------------------------------------------------- --------------------
881 _db_block_prefetch_quota Prefetch quota as a percent of cache size 10
883 _db_block_prefetch_limit Prefetch limit in blocks 0
1156 _db_file_noncontig_mblock_read_count number of noncontiguous db blocks to be prefetched 11
SYS@oraESKDB1> ALTER SYSTEM SET "_db_file_noncontig_mblock_read_count"=0 SCOPE=SPFILE SID='*';
System altered.
SYS@oraESKDB1> ALTER SYSTEM SET "_db_block_prefetch_quota"=0 SCOPE=SPFILE SID='*';
System altered.
SYS@oraESKDB1> ALTER SYSTEM SET "_db_block_prefetch_limit"=0 SCOPE=SPFILE SID='*';
System altered.
SYS@oraESKDB1> ALTER SYSTEM SET "_db_file_noncontig_mblock_read_count"=0 SCOPE=SPFILE SID='*';
db file single write
这个等待事件通常只发生在一种情况下,就是Oracle 更新数据文件头信息时(比如发生Checkpoint)。
当这个等待事件很明显时,需要考虑是不是数据库中的数据文件数量太大,导致Oracle需要花较长的时间来做所有文件头的更新操作(checkpoint)。
SELECT *
FROM v$event_name
WHERE NAME IN ('db file single write');

这个等待事件有三个参数:
- file#: 需要更新的数据块所在的数据文件的文件号。查询文件号的SQL语句是:SELECT * FROM v$datafile WHERE file# = \<file#>;
- block#:需要更新的数据块号,如果BLOCK号不是1,则可以通过如下查询查出Oracle正在写入的对象是什么:
SELECT segment_name , segment_type ,
owner , tablespace_name
FROM sys.dba_extents
WHERE file_id = \<file#>
AND \<block#>
BETWEEN block_id AND block_id + blocks -1;
- blocks:需要更新的数据块数目(通常来说应该等于1),或Oracle写入file#的数据文件中从BLOCK#开始写入的BLOCK的数量。头一般来说都是BLOCK1,操作系统指定的文件头是BLOCK0,如果BLOCK号大于1,则表明Oracle正在写入的是一个对象而不是文件头。
direct path read(直接路径读、DPR)
直接路径读等待事件的3个参数分别是:file#(指绝对文件号)、first block#和block数量。
SELECT * FROM V$EVENT_NAME A WHERE A.NAME = 'direct path read';

这个等待事件有三个参数:
file number: 等待I/O读取请求的文件的绝对文件号
first dba: 等待I/O读取请求的第一个BLOCK号
block cnt: 以first block为起点,总共有多少个连续的BLOCK被请求读取
由参数P1与P2推得访问的数据对象:
select s.segment_name, s.partition_name
from dba_extents s
where between s.block_id and (s.block_id + s.blocks -1) and s.file_id =
直接路径读(direct path read)通常发生在Oracle直接读取数据到PGA时,这个读取不需要经过SGA。这类读取通常在以下情况被使用:
- 大量的磁盘排序IO操作 在排序操作(order by, group by, union, distinct, rollup,合并连接)时,由于PGA中的SORT_AREA_SIZE空间不足,无法在PGA中完成排序,需要利用temp表空间进行排序,当从临时表空间中读取排序结果时,会产生direct path read,从10g开始表现为direct path read temp等待事件。
- 大量的Hash Join操作,利用temp表空间保存hash区。使用HASH连接的SQL语句,将不适合位于内存中的散列分区刷新到临时表空间中。为了查明匹配SQL谓词的行,临时表空间中的散列分区被读回到内存中(目的是为了查明匹配SQL谓词的行),ORALCE会话在direct path read等待事件上等待。
- SQL语句的并行查询,并行查询从属进程 使用并行扫描的SQL语句也会影响系统范围的direct path read等待事件。在并行执行过程中,direct path read等待事件与从属查询有关,而与父查询无关,运行父查询的会话基本上会在PX Deq:Execute Reply上等待,从属查询会产生direct path read等待事件。
- 预读操作
- 串行全表扫描(Serial Table Scan),大表的全表扫描,在Oracle11g中,全表扫描的算法有新的变化,根据表的大小、高速缓存的大小等信息,决定是否绕过SGA直接从磁盘读取数据。而10g则是全部通过高速缓存读取数据,称为table scan(large)。11g认为大表全表时使用直接路径读,可能比10g中的数据文件散列读(db file scattered reads)速度更快,使用的latch也更少。
最常见的是第一种情况。在DSS系统中,存在大量的Direct path read是很正常的,但是在OLTP系统中,通常显著的直接路径读都意味着系统应用存在问题,从而导致大量的磁盘排序读取操作。
db file sequential read、db file scattered read、direct path read是常见的集中数据读方式,下图简要描述了这3种方式的读取示意。
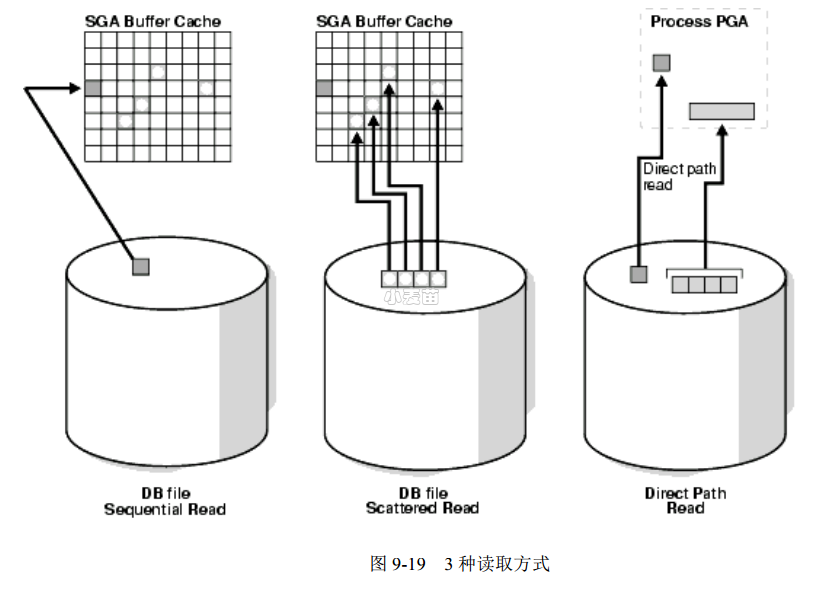
大量的direct path read等待时间最可能是一个应用程序问题。
direct path read事件由SQL语句驱动,这些SQL语句执行来自临时的或常规的表空间的直接读取操作。当输入的内容大于PGA中的工作区域时,带有需要排序的函数的SQL语句将排序结果写入到临时表空间中, 临时表空间中的排序顺序串随后被合并,用于提供最终的结果。读取排序结果时, Oracle会话在direct path read等待事件上等待。
对于这一写入等待,我们应该找到I/O操作最为频繁的数据文件(如果有过多的排序操作,很有可能就是临时文件),分散负载,加快其写入操作。
DB_FILE_DIRECT_IO_COUNT初始化参数可能影响direct path read的性能。
直接读取可能按照同步或异步的方式执行,取决于平台和初始化参数disk_asynch_io参数的值。使用异步I/O时,系统范围的等待的事件的统计可能不准确,会造成误导作用。
该事件一般不可能显示为主要的瓶颈,但它实际上也许是就是祸首。由于ORACLE统计等待时间的方式会造成统计的时间量不准确(如:从属查询产生的时间无法进行统计),所以对该事件不应该使用v$session_event视图中的total_wait或time_waited进行估计,应该使用v$sesstat视图中的直接读取操作次数(physical reads direct)进行判断:
select a.NAME,
b.SID,
b.VALUE,
round((sysdate - c.LOGON_TIME) * 24) hours_connected
from v$statname a, v$sesstat b, v$session c
where b.SID = c.SID
and a.STATISTIC# = b.STATISTIC#
and b.VALUE > 0
and a.NAME = 'physical reads direct'
order by b.VALUE;
由direct path read事件产生的原因,我们需要判断该事件正在读取什么段(如:散列段、排序段、一般性的数据文件),由此可判断产生该事件的原因是什么,可使用以下语句进行查询:
SELECT a.event,
a.sid,
c.sql_hash_value hash_vale,
decode(d.ktssosegt,
1,
'SORT',
2,
'HASH',
3,
'DATA',
4,
'INDEX',
5,
'LOB_DATA',
6,
'LOB_INDEX',
NULL) AS segment_type,
b.tablespace_name,
b.file_name
FROM v$session_wait a, dba_data_files b, v$session c, x$ktsso d
WHERE c.saddr = d.ktssoses(+)
AND c.serial# = d.ktssosno(+)
AND d.inst_id(+) = userenv('instance')
AND a.sid = c.sid
AND a.p1 = b.file_id
AND a.event = 'direct path read'
UNION ALL
SELECT a.event,
a.sid,
d.sql_hash_value hash_value,
decode(e.ktssosegt,
1,
'SORT',
2,
'HASH',
3,
'DATA',
4,
'INDEX',
5,
'LOB_DATA',
6,
'LOB_INDEX',
NULL) AS segment_type,
b.tablespace_name,
b.file_name
FROM v$session_wait a,
dba_temp_files b,
v$parameter c,
v$session d,
x$ktsso e
WHERE d.saddr = e.ktssoses(+)
AND d.serial# = e.ktssosno(+)
AND e.inst_id(+) = userenv('instance')
AND a.sid = d.sid
AND b.file_id = a.p1 - c.VALUE
AND c.NAME = 'db_files'
AND a.event = 'direct path read';
注:如果是从临时文件中读取排序段的会话,则表明SORT_AREA_SIZE或PGA_AGGREGATE_TARGET的设置是不是偏小。如果是从临时文件中读取HASH段的会话,则表明HASH_AREA_SIZE或PAG_AGGREGATE_TARGET的设置是不是偏小。
当direct path read等待事件是由于并行查询造成的(读取的是一般的数据文件而非临时文件),父SQL语句的HASHVALUE与子SQL语句的HASHVALUE不同,可以通过以下SQL查询产生子SQL语句的父SQL语句:
SELECT DECODE(A.QCSERIAL#, NULL, 'PARENT', 'CHILD') STMT_LEVEL,