
合 《PostgreSQL技术内幕——原理探索》第九章 预写式日志——WAL
Tags: PGPostgreSQL翻译《PostgreSQL技术内幕——原理探索》
- 9.1 概述
- 9.1.1 没有WAL的插入操作
- 9.1.2 插入操作与数据库恢复
- 9.1.3 整页写入
- 9.2 事务日志与WAL段文件
- WAL段文件尺寸
- 时间线标识
- WAL文件名
- 9.3 WAL段文件的内部布局
- 9.4 WAL记录的内部布局
- 9.4.1 WAL记录首部部分
- 9.4.2 XLOG记录数据部分(9.4及以前)
- 9.4.2.1 备份区块
- 9.4.2.2 非备份区块
- 9.4.3 XLOG记录数据部分(9.5及后续版本)
- WAL压缩
- 9.4.3.1 备份区块
- 9.4.3.2 非备份区块
- 9.5 WAL记录的写入
- 9.6 WAL写入进程
- 9.7 PostgreSQL中的检查点过程
- 9.7.1 检查点过程概述
- 9.7.2 pg_crontrol文件
- PostgreSQL11中移除了前任检查点
- 9.8 PostgreSQL中的数据库恢复
- 9.9 WAL段文件管理
- 9.9.1 WAL段切换
- 9.9.2 WAL段管理(9.5版及以后)
- 9.9.3 WAL段管理(9.4版及以前)
- 9.10 归档日志与持续归档
事务日志(transaction log)是数据库的关键组件,因为当出现系统故障时,任何数据库管理系统都不允许丢失数据。事务日志是数据库系统中所有变更(change)与行为(action)的历史记录,当诸如电源故障,或其他服务器错误导致服务器崩溃时,它被用于确保数据不会丢失。由于日志包含每个已执行事务的相关充分信息,因此当服务器崩溃时,数据库服务器应能通过重放事务日志中的变更与行为来恢复数据库集群。
在计算机科学领域,WAL是Write Ahead Logging的缩写,它指的是将变更与行为写入事务日志的协议或规则;而在PostgreSQL中,WAL是Write Ahead Log的缩写。在这里它被当成事务日志的同义词,而且也用来指代一种将行为写入事务日志(WAL)的实现机制。虽然有些令人困惑, 但本文将使用PostgreSQL中的定义。
WAL机制在7.1版本中首次被实现,用以减轻服务器崩溃的影响。它还是时间点恢复(Point-in-Time Recovery PIRT)与流复制(Streaming Replication, SR)实现的基础,这两者将分别在第10章和第11章中介绍。
尽管理解WAL机制对于管理、集成PostgreSQL非常重要,但由于它的复杂性,不可能做到简要介绍。因此本章将会对WAL做一个完整的解释。第一节描绘了WAL的全貌,介绍了一些重要的概念与关键词。接下来的小节中会依次讲述其他主题:
- 事务日志(WAL)的逻辑结构与物理结构
- WAL数据的内部布局
- WAL数据的写入
- WAL写入者进程
- 检查点过程
- 数据库恢复流程
- 管理WAL段文件
- 持续归档
9.1 概述
让我们先来概述一下WAL机制。为了阐明WAL要解决的问题,第一部分展示了如果PostgreSQL在没有实现WAL时崩溃会发生什么。第二部分介绍了一些关键概念,并概览了本章中的一些关键主题。最后一部分总结了WAL概述部分,并引出了一个更为重要的概念。
9.1.1 没有WAL的插入操作
正如在第八章中讨论的那样,为了能高效访问关系表的页面,几乎所有的DBMS都实现了共享缓冲池。
假设有这样一个没有实现WAL机制的PostgreSQL,现在向表A中插入一些数据元组,如图9.1所示。
图9.1 没有WAL的插入操作
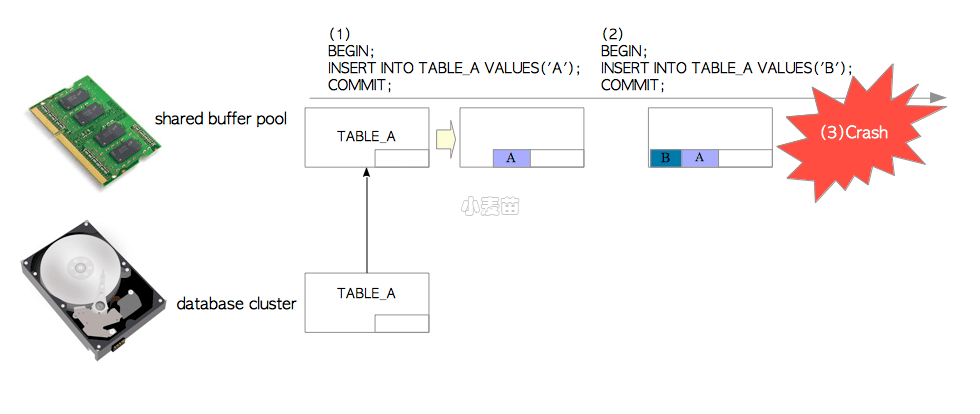
- 发起第一条
INSERT语句时,PostgreSQL从数据库集簇文件中加载表A的页面到内存中的共享缓冲池。然后向页面中插入一条元组。页面并没有立刻写回到数据库集簇文件中。正如第8章中提到的,被修改过的页面通常称为脏页(dirty page) - 发起第二条
INSERT语句时,PostgreSQL直接向缓冲池里的页面内添加了一条新元组。这一页仍然没有被写回到持久存储中。 - 如果操作系统或PostgreSQL服务器因为各种原因失效(例如电源故障),所有插入的数据都会丢失。
因此没有WAL的数据库在系统崩溃时是很脆弱的。
9.1.2 插入操作与数据库恢复
为了解决上述系统失效问题,同时又不招致性能损失,PostgreSQL支持了WAL。这一部分介绍了一些关键词和概念,以及WAL数据的写入和数据库系统的恢复。
为了应对系统失效,PostgreSQL将所有修改作为历史数据写入持久化存储中。这份历史数据称为XLOG记录(xlog record)或WAL数据(wal data)。
当插入、删除、提交等变更动作发生时,PostgreSQL会将XLOG记录写入内存中的WAL缓冲区(WAL Buffer)。当事务提交或中止时,它们会被立即写入持久存储上的WAL段文件(WAL segment file)中(更精确来讲,其他场景也可能会有XLOG记录写入,细节将在9.5节中描述)。XLOG记录的日志序列号(Log Sequence Number, LSN)标识了该记录在事务日志中的位置,记录的LSN被用作XLOG记录的唯一标识符。
顺便一提,当我们考虑数据库系统如何恢复时,可能会想到一个问题:PostgreSQL是从哪一点开始恢复的?答案是重做点(REDO Point),即最新一个检查点(Checkpoint)开始时XLOG记录写入的位置。(PostgreSQL中的检查点将在9.7节中描述)。实际上,数据库恢复过程与检查点过程紧密相连,两者是不可分割的。
WAL与检查点过程在7.1版本中同时实现
介绍完了主要的关键词与概念,现在来说一下带有WAL时的元组插入操作。如图9.2所示:
图9.2 带有WAL的插入操作
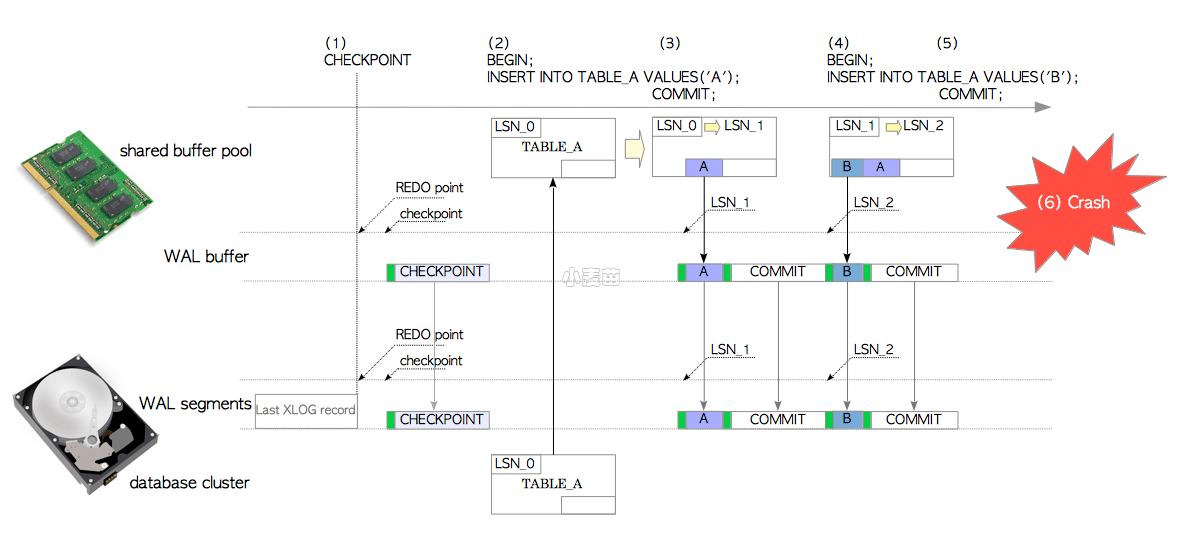
表A的LSN展示的是表A页面中页首部里
pd_lsn类型的PageXLogRecPtr字段,与页面的LSN是一回事。
- 检查点进程是一个后台进程,周期性地执行过程。当检查点进程开始执行检查点时,它会向当前WAL段文件写入一条XLOG记录,称为检查点(Checkpoint Record)。这条记录包含了最新的重做点位置。
- 发起第一条
INSERT语句时,PostgreSQL从数据库集簇文件中加载表A的页面至内存中的共享缓冲池,向页面中插入一条元组,然后在LSN_1位置创建并写入一条相应的XLOG记录,然后将表A的LSN从LSN_0更新为LSN_1。在本例中,XLOG记录是由首部数据与完整元组组成的一对值。 - 当该事务提交时,PostgreSQL向WAL缓冲区创建并写入一条关于该提交行为的XLOG记录,然后将WAL缓冲区中的所有XLOG记录刷写入WAL段文件中。
- 发起第二条
INSERT语句时,PostgreSQL向页面中插入一条新元组,然后在LSN_2位置创建并写入一条相应的XLOG记录,然后将表A的LSN从LSN_1更新为LSN_2。 - 当这条语句的事务提交时,PostgreSQL执行同步骤3类似的操作。
- 设想当操作系统失效发生时,尽管共享缓冲区中的所有数据都丢失了,但所有页面修改已经作为历史记录被写入WAL段文件中。
接下来的步骤展示了如何将数据库集簇恢复到崩溃时刻前的状态。不需要任何特殊的操作,重启PostgreSQL时会自动进入恢复模式,如图9.3所示。PostgreSQL会从重做点开始,依序读取正确的WAL段文件并重放XLOG记录。
图9.3 使用WAL进行数据库恢复
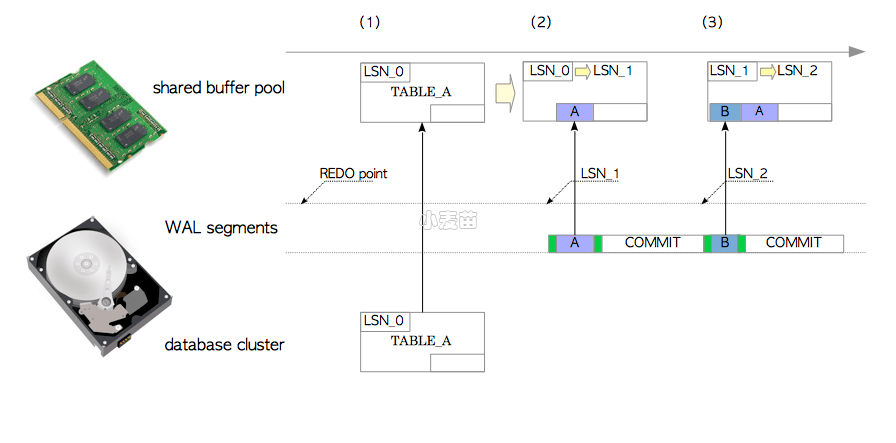
- PostgreSQL从相关的WAL段文件中读取第一条
INSERT语句的XLOG记录,并从硬盘上的数据库集簇目录加载表A的页面到内存中的共享缓冲区中。 - 在重放XLOG记录前,PostgreSQL会比较XLOG记录的LSN与相应页面的LSN。这么做的原因在第9.8节中描述。重放XLOG记录的规则如下所示:
- 如果XLOG记录的LSN要比页面LSN大,XLOG记录中的数据部分就会被插入到页面中,并将页面的LSN更新为XLOG记录的LSN。
- 如果XLOG记录的LSN要比页面的LSN小,那么不用做任何事情,直接读取后续的WAL数据即可。
- PostgreSQL按照同样的方式重放其余的XLOG记录。
PostgreSQL可以通过按时间顺序重放写在WAL段文件中的XLOG记录来自我恢复,因此,PostgreSQL的XLOG记录显然是一种重做日志(REDO log)。
PostgreSQL不支持撤销日志(UNDO log)
尽管写XLOG记录肯定有一定的代价,这些代价和全页写入相比微不足道。所付出的代价换来了巨大的收益,比如,系统崩溃时的恢复能力。
9.1.3 整页写入
假设后台写入进程在写入脏页的过程中出现了操作系统故障,导致磁盘上表A的页面数据损坏。XLOG是无法在损坏的页面上重放的,我们需要其他功能来确保这一点。
译注:PostgreSQL默认使用8KB的页面,操作系统通常使用4KB的页面,可能出现只写入一个4KB页面的情况。
PostgreSQL支持诸如整页写入(full-page write)的功能来处理这种失效。如果启用,PostgreSQL会在每次检查点之后,在每个页面第一次发生变更时,会将整个页面及相应首部作为一条XLOG记录写入。这个功能默认是开启的。在PostgreSQL中,这种包含完整页面的XLOG记录称为备份区块(backup block),或者整页镜像(full-page image)。
图9.4 整页写入
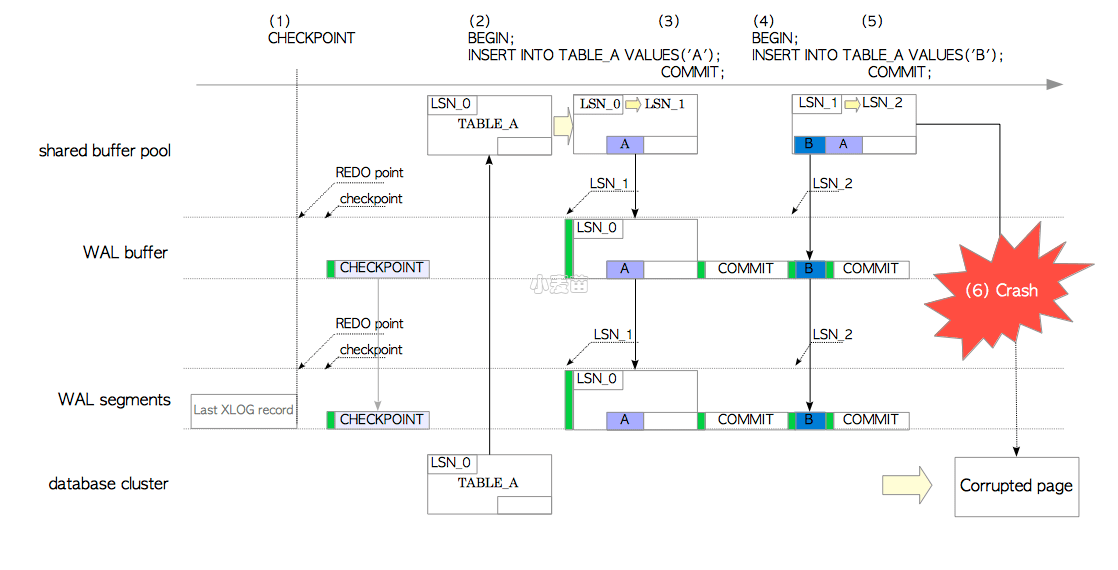
- 检查点进程开始进行检查点过程。
- 在第一条
INSERT语句进行插入操作时,PostgreSQL执行的操作几乎同上所述。区别在于这里的XLOG记录是当前页的备份区块(即,包含了完整的页面),因为这是自最近一次检查点以来,该页面的第一次写入。 - 当事务提交时,PostgreSQL的操作同上节所述。
- 第二条
INSERT语句进行插入操作时,PostgreSQL的操作同上所述,这里的XLOG记录就不是备份块了。 - 当这条语句的事务提交时,PostgreSQL的操作同上节所述。
- 为了说明整页写入的效果,我们假设后台写入进程在向磁盘写入脏页的过程中出现了操作系统故障,导致磁盘上表A的页面数据损坏。
重启PostgreSQL即可修复损坏的集簇,如图9.5所示
图9.5 使用备份区块进行数据库恢复
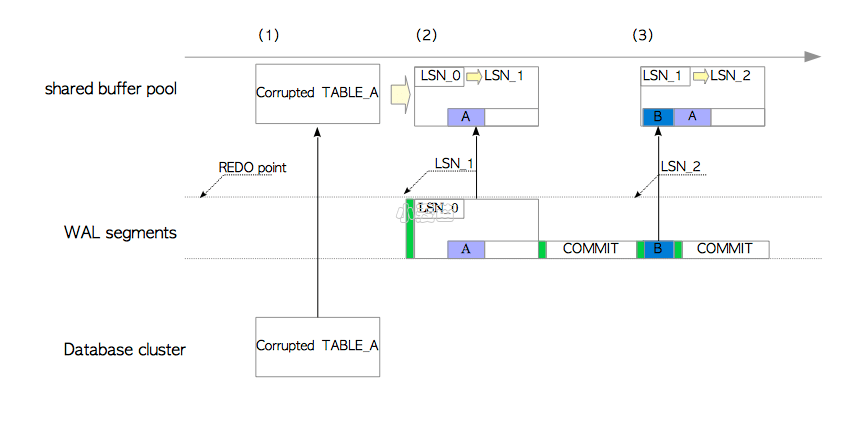
PostgreSQL读取第一条
INSERT语句的XLOG记录,并从数据库集簇目录加载表A的页面至共享缓冲池中。在本例中,按照整页写入的规则,这条XLOG记录是一个备份区块。当一条XLOG记录是备份区块时,会使用另一条重放规则:XLOG记录的数据部分会直接覆盖当前页面,无视页面或XLOG记录中的LSN,然后将页面的LSN更新为XLOG记录的LSN。
在本例中,PostgreSQL使用记录的数据部分覆写了损坏的页面,并将表A的LSN更新为
LSN_1,通过这种方式,损坏的页面通过它自己的备份区块恢复回来了。因为第二条XLOG记录不是备份区块, 因此PostgreSQL的操作同上所述。
即使发生一些数据写入错误,PostgreSQL也能从中恢复。(当然如果发生文件系统或物理介质失效,就不行了)
9.2 事务日志与WAL段文件
PostgreSQL在逻辑上将XLOG记录写入事务日志,即,一个长度用8字节表示的虚拟文件(16 EB)。
虽说事务日志的容量实际上应该是无限的,但8字节长度的地址空间已经足够宽广了。目前是不可能处理这个量级的单个文件的。因此PostgreSQL中的事务日志实际上默认被划分为16M大小的一系列文件,这些文件被称作WAL段(WAL Segment)。如图9.6所示。
WAL段文件尺寸
从版本11开始,在使用
initdb创建数据库时,可以通过--wal-segsize选项来配置WAL段文件的大小。
图9.6 事务日志与WAL段文件
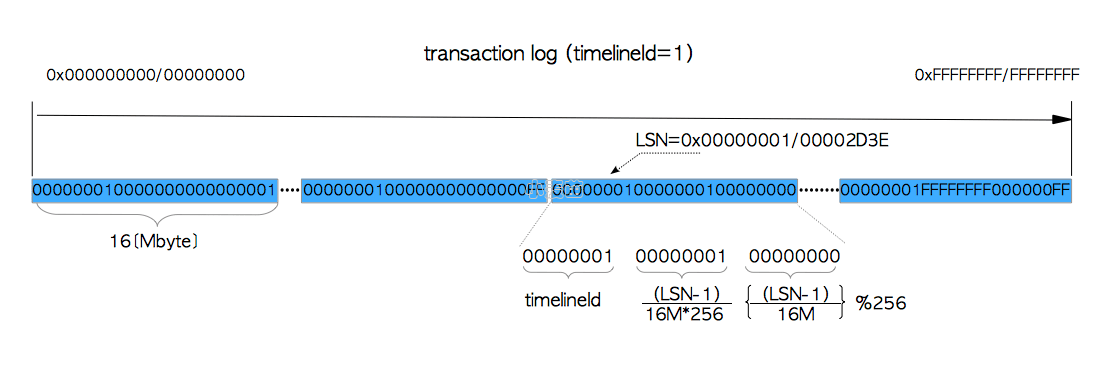
WAL段文件的文件名是由24个十六进制数字组成的,其命名规则如下: $$ \begin{align} \verb|WAL段文件名| = \verb|timelineId| + (\verb|uint32|) \frac{\verb|LSN|-1}{16\verb|M|*256}
+ (\verb|uint32|)\left(\frac{\verb|LSN|-1}{16\verb|M|}\right) % 256 \end{align} $$
时间线标识
PostgreSQL的WAL有时间线标识(TimelineID,四字节无符号整数)的概念,用于第十章中所述的时间点恢复(PITR)。不过在本章中时间线标识将固定为
0x00000001,因为接下来的几节里还不需要这个概念。
第一个WAL段文件名是$00000001\color{blue}{00000000}000000\color{blue}{01}$,如果第一个段被XLOG记录写满了,就会创建第二个段$00000001\color{blue}{00000000}000000\color{blue}{02}$,后续的文件名将使用升序。在$00000001\color{blue}{00000000}000000\color{blue}{FF}$被填满之后,就会使用下一个文件$00000001\color{blue}{00000001}000000\color{blue}{00}$。通过这种方式,每当最后两位数字要进位时,中间8位数字就会加一。与之类似,在$00000001\color{blue}{00000001}000000\color{blue}{FF}$被填满后,就会开始使用$00000001\color{blue}{00000002}000000\color{blue}{00}$,依此类推。
WAL文件名
使用内建的函数
pg_xlogfile_name(9.6及以前的版本),或pg_walfile_name(10及以后的版本),我们可以找出包含特定LSN的WAL段文件。例如:
9.3 WAL段文件的内部布局
一个WAL段文件大小默认为16MB,并在内部划分为大小为8192字节(8KB)的页面。第一个页包含了由XLogLongPageHeaderData定义的首部数据,其他的页包含了由XLogPageHeaderData定义的首部数据。每页在首部数据之后,紧接着就是以降序写入的XLOG记录,如图9.7所示。
图9.7 WAL段文件内部布局
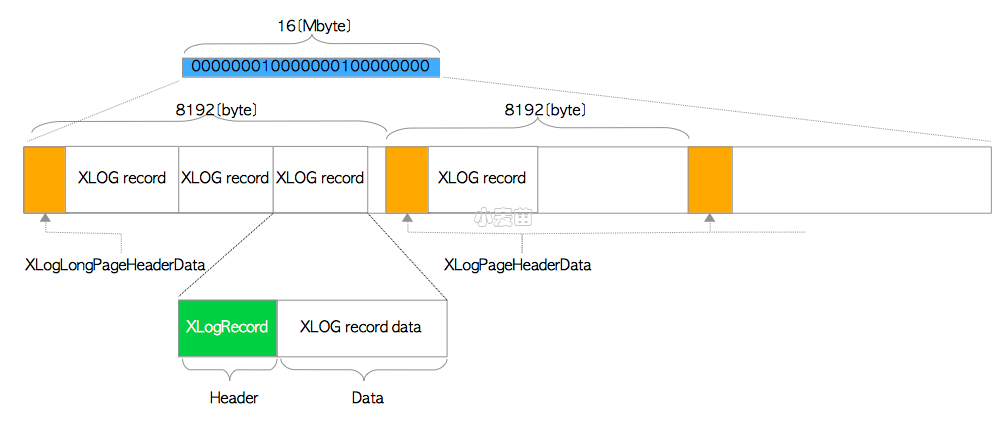
XLogLongPageHeaderData与XLogPageHeaderData结构定义在 src/include/access/xlog_internal.h中。这两个结构的具体说明就不在此展开了,因为对于后续小节并非必需。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | typedef struct XLogPageHeaderData { uint16 xlp_magic; /* 用于正确性检查的魔数 */ uint16 xlp_info; /* 标记位,详情见下 */ TimeLineID xlp_tli; /* 页面中第一条记录的时间线ID */ XLogRecPtr xlp_pageaddr; /* 当前页的XLOG地址 */ /* 当本页放不下一条完整记录时,我们会在下一页继续,xlp_rem_len存储了来自先前页面 * 记录剩余的字节数。注意xl_rem_len包含了备份区块的数据,也就是说它会在第一个首部跟踪 * xl_tot_len而不是xl_len。还要注意延续的数据不一定是对齐的。*/ uint32 xlp_rem_len; /* 记录所有剩余数据的长度 */ } XLogPageHeaderData; typedef XLogPageHeaderData *XLogPageHeader; /* 当设置了XLP_LONG_HEADER标记位时,我们将在页首部中存储额外的字段。 * (通常是在XLOG文件中的第一个页面中) 额外的字段用于确保文件的正确性。 */ typedef struct XLogLongPageHeaderData { XLogPageHeaderData std; /* 标准首部 */ uint64 xlp_sysid; /* 来自pg_control中的系统标识符 */ uint32 xlp_seg_size; /* 交叉校验 */ uint32 xlp_xlog_blcksz;/* 交叉校验 */ } XLogLongPageHeaderData; |
9.4 WAL记录的内部布局
一条XLOG记录由通用的首部部分与特定的数据部分构成。本章第一节描述了首部的结构,剩下两个节分别解释了9.5版本前后数据部分的结构。(9.5版本改变了数据格式)
9.4.1 WAL记录首部部分
所有的XLOG记录都有一个通用的首部,由结构XLogRecord定义。9.5更改了首部的定义,9.4及更早版本的结构定义如下所示:
1 2 3 4 5 6 7 8 9 10 11 | typedef struct XLogRecord { uint32 xl_tot_len; /* 整条记录的全长 */ TransactionId xl_xid; /* 事务ID */ uint32 xl_len; /* 资源管理器的数据长度 */ uint8 xl_info; /* 标记位,如下所示 */ RmgrId xl_rmid; /* 本记录的资源管理器 */ /* 这里有2字节的填充,初始化为0 */ XLogRecPtr xl_prev; /* 在日志中指向先前记录的指针 */ pg_crc32 xl_crc; /* 本记录的CRC */ } XLogRecord; |
除了两个变量,大多数变量的意思非常明显,无需多言。xl_rmid与xl_info都是与资源管理器(resource manager)相关的变量,它是一些与WAL功能(写入,重放XLOG记录)相关的操作集合。资源管理器的数目随着PostgreSQL不断增加,第10版包括这些:
| 资源管理器 | |
|---|---|
| 堆元组操作 | RM_HEAP, RM_HEAP2 |
| 索引操作 | RM_BTREE, RM_HASH, RM_GIN, RM_GIST, RM_SPGIST, RM_BRIN |
| 序列号操作 | RM_SEQ |
| 事务操作 | RM_XACT, RM_MULTIXACT, RM_CLOG, RM_XLOG, RM_COMMIT_TS |
| 表空间操作 | RM_SMGR, RM_DBASE, RM_TBLSPC, RM_RELMAP |
| 复制与热备操作 | RM_STANDBY, RM_REPLORIGIN, RM_GENERIC_ID, RM_LOGICALMSG_ID |
下面是一些有代表性的例子,展示了资源管理器工作方式。
- 如果发起的是
INSERT语句,则其相应XLOG记录首部中的变量xl_rmid与xl_info会相应地被设置为RM_HEAP与XLOG_HEAP_INSERT。当恢复数据库集簇时,就会按照xl_info选用资源管理器RM_HEAP的函数heap_xlog_insert()来重放当前XLOG记录。 UPDATE语句与之类似,首部变量中的xl_info会被设置为XLOG_HEAP_UPDATE,而在数据库恢复时就会选用资源管理器RM_HEAP的函数heap_xlog_update()进行重放。- 当事务提交时,相应XLOG记录首部的变量
xl_rmid与xl_info会被相应地设置为RM_XACT与XLOG_XACT_COMMIT。当数据库恢复时,RM_XACT的xact_redo_commit()就会执行本记录的重放。
在9.5及之后的版本,首部结构XLogRecord移除了一个字段xl_len,精简了XLOG记录的格式,省了几个字节。
1 2 3 4 5 6 7 8 9 10 11 12 13 | typedef struct XLogRecord { uint32 xl_tot_len; /* 整条记录的总长度 */ TransactionId xl_xid; /* 事物标识 xid */ XLogRecPtr xl_prev; /* 指向日志中前一条记录的指针 */ uint8 xl_info; /* 标记位,详情见下*/ RmgrId xl_rmid; /* 本条记录对应的资源管理器 */ /* 这里有2字节的填充,初始化为0 */ pg_crc32c xl_crc; /* 本记录的CRC */ /* 紧随其后的是XLogRecordBlockHeaders 与 XLogRecordDataHeader ,不带填充 */ } XLogRecord; |
9.4版本中的
XLogRecord结构定义在src/include/access/xlog.h中,9.5及以后的定义在src/include/access/xlogrecord.h。heap_xlog_insert与heap_xlog_update定义在src/backend/access/heap/heapam.c;而函数xact_redo_commit定义在src/backend/access/transam/xact.c中
9.4.2 XLOG记录数据部分(9.4及以前)
XLOG记录的数据部分可以分为两类:备份区块(完整的页面),或非备份区块(不同的操作相应的数据不同)。
图9.8 XLOG记录的样例(9.4版本或更早)
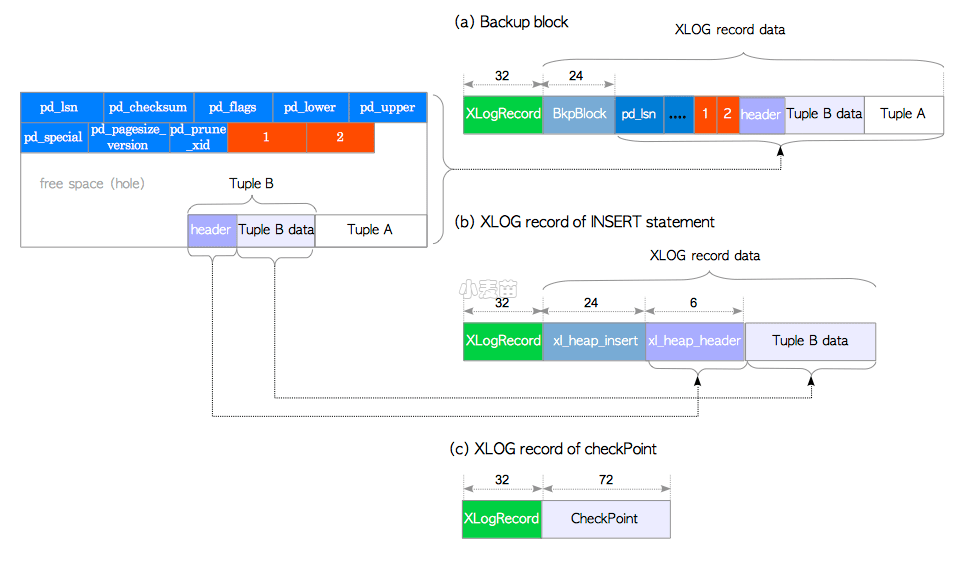
让我们通过几个具体示例来了解XLOG记录的内部布局。
9.4.2.1 备份区块
备份区块如图9.8(a)所示,它由两个数据结构和一个数据对象组成,如下所述:
- 首部部分,
XLogRecord结构体 BkpBlock结构体- 除去空闲空间的完整页面。
BkpBlock包括了用于在数据库集簇目录中定位该页面的变量(比如,包含该页面的关系表的RelFileNode与ForkNumber,以及文件内的区块号BlockNumber),以及当前页面空闲空间的开始位置与长度。
1 2 3 4 5 6 7 8 9 10 11 | # @include/access/xlog_internal.h typedef struct BkpBlock { RelFileNode node; /* 包含该块的关系 */ ForkNumber fork; /* 关系的分支(main,vm,fsm,...) */ BlockNumber block; /* 区块号 */ uint16 hole_offset; /* "空洞"前的字节数 */ uint16 hole_length; /* "空洞"的长度 */ /* 实际的区块数据紧随该结构体后 */ } BkpBlock; |
9.4.2.2 非备份区块
在非备份区块中,数据部分的布局依不同操作而异。这里举一个具有代表性的例子:一条INSERT语句的XLOG记录。如图9.8(b)所示,INSERT语句的XLOG记录是由两个数据结构与一个数据对象组成的:
- 首部部分,
XLogRecord结构体 xl_heap_insert结构体- 被插入的元组 —— 更精确地说,是移除了一些字节的元组。
结构体xl_heap_insert包含的变量用于在数据库集簇中定位被插入的元组。(即,包含该元组的表的RelFileNode,以及该元组的tid),以及该元组的可见性标记位。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | typedef struct BlockIdData { uint16 bi_hi; uint16 bi_lo; } BlockIdData; typedef uint16 OffsetNumber; typedef struct ItemPointerData { BlockIdData ip_blkid; OffsetNumber ip_posid; } typedef struct RelFileNode { Oid spcNode; /* 表空间 */ Oid dbNode; /* 数据库 */ Oid relNode; /* 关系 */ } RelFileNode; typedef struct xl_heaptid { RelFileNode node; /* 关系定位符 */ ItemPointerData tid; /* 元组在关系中的位置 */ } xl_heaptid; typedef struct xl_heap_insert { xl_heaptid target; /* 被插入的元组ID */ bool all_visible_cleared; /* PD_ALL_VISIBLE 是否被清除 */ } xl_heap_insert; |
在结构体
xl_heap_header的代码注释中解释了移除插入元组中若干字节的原因:我们并没有在WAL中存储被插入或被更新元组的固定部分(即
HeapTupleHeaderData,堆元组首部),我们可以在需要时从WAL中的其它部分重建这几个字段,以此节省一些字节。或者根本就无需重建。
这里还有一个例子值得一提,如图9.8(c)所示,检查点的XLOG记录相当简单,它由如下所示的两个数据结构组成:
XLogRecord结构(首部部分)- 包含检查点信息的
CheckPoint结构体(参见9.7节)
xl_heap_header结构定义在src/include/access/htup.h中,而CheckPoint结构体定义在src/include/catalog/pg_control.h中。
9.4.3 XLOG记录数据部分(9.5及后续版本)
在9.4及之前的版本,XLOG记录并没有通用的格式,因此每一种资源管理器都需要定义各自的格式。在这种情况下,维护源代码,以及实现与WAL相关的新功能变得越来越困难。为了解决这个问题,9.5版引入了一种通用的结构化格式,不依赖于特定的资源管理器。
XLOG记录的数据部分可以被划分为两个部分:首部与数据,如图9.9所示:
图9.9 通用XLOG记录格式
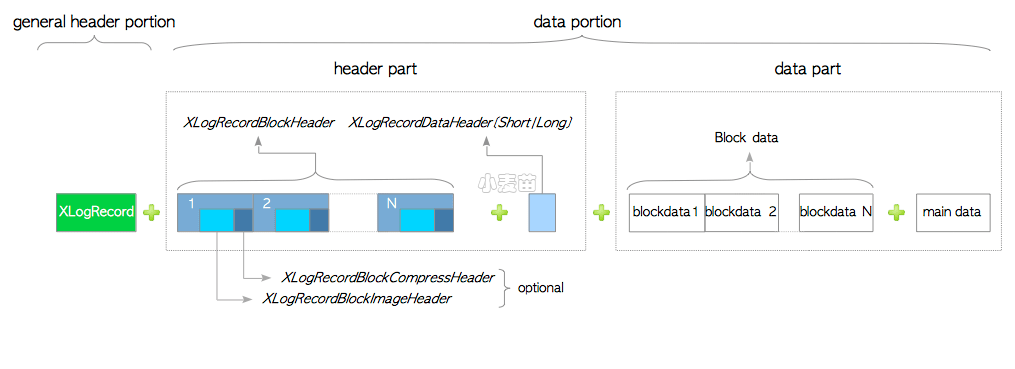
首部部分包含零个或多个XLogRecordBlockHeaders,以及零个或一个XLogRecordDataHeaderShort(或XLogRecordDataHeaderLong);它必须至少包含其中一个。当记录存储着整页镜像时(即备份区块),XLogRecordBlockHeader会包含XLogRecordBlockImageHeader,如果启用压缩还会包含XLogRecordBlockCompressHeader。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 | /* 追加写入XLOG记录的区块数据首部。 * 'data_length'是与本区块关联的,特定于资源管理器的数据荷载长度。它不包括可能会出现 * 的整页镜像的长度,也不会包括XLogRecordBlockHeader结构本身。注意我们并不会对 * XLogRecordBlockHeader结构做边界对齐!因此在使用前该结构体必须拷贝到对齐的本地存储中。 */ typedef struct XLogRecordBlockHeader { uint8 id; /* 块引用 ID */ uint8 fork_flags; /* 关系中的分支,以及标志位 */ uint16 data_length; /* 荷载字节数(不包括页面镜像) */ /* 如果设置 BKPBLOCK_HAS_IMAGE, 紧接一个XLogRecordBlockImageHeader结构 */ /* 如果未设置 BKPBLOCK_SAME_REL, 紧接着一个RelFileNode结构 */ /* 紧接着区块号码 */ } XLogRecordBlockHeader; /* 分支标号放在fork_flags的低4位中,高位用于标记位 */ #define BKPBLOCK_FORK_MASK 0x0F #define BKPBLOCK_FLAG_MASK 0xF0 #define BKPBLOCK_HAS_IMAGE 0x10 /* 区块数据是一个XLogRecordBlockImage */ #define BKPBLOCK_HAS_DATA 0x20 #define BKPBLOCK_WILL_INIT 0x40 /* 重做会重新初始化当前页 */ #define BKPBLOCK_SAME_REL 0x80 /* 忽略RelFileNode,与前一个相同 */ /* XLogRecordDataHeaderShort/Long 被用于本记录的“主数据”部分。如果数据的长度小于256字节 * 则会使用Short版本的格式,即使用单个字节来保存长度,否则会使用长版本的格式。 */ typedef struct XLogRecordDataHeaderShort { uint8 id; /* XLR_BLOCK_ID_DATA_SHORT */ uint8 data_length; /* 载荷字节数目 */ } XLogRecordDataHeaderShort; #define SizeOfXLogRecordDataHeaderShort (sizeof(uint8) * 2) typedef struct XLogRecordDataHeaderLong { uint8 id; /* XLR_BLOCK_ID_DATA_LONG */ /* 紧随其后的是uint32类型的data_length, 未对齐 */ } XLogRecordDataHeaderLong; /* 当包含整页镜像时额外的首部信息(即当BKPBLOCK_HAS_IMAGE标记位被设置时)。 * * XLOG相关的代码会意识到数据压缩上一个显而易见的情况,即PG里的数据页面通常会在中间包含一个 * 未使用的“空洞”,空洞里面通常只有置零的字节。如果空洞的长度大于0,我们就会从存储的数据中 * 移除该“空洞”(且XLOG记录的CRC也不会计算该空洞)。因此区块数据的总量实际上是块大小BLCKSZ * 减去空洞包含的字节大小。 * * 当启用 wal_compression 时,一个包含空洞的整页镜像除了移除空洞,还会额外是引用PGLZ压缩 * 算法进行压缩。这能减小WAL日志的体积,但会增加在记录WAL日志过程中的CPU开销。在这种情况下, * 空洞的大小就无法通过块大小-页面镜像大小来计算了。基本上,这需要存储额外的信息。但当没有 * 空洞存在时,我们可以假设空洞大小为0,因此就不需要存储额外信息了。注意,当压缩节约的字节数 * 小于额外信息的长度时,WAL里就会存储原始的页面镜像,而不是压缩过的版本。因此当成功进行压缩 * 时,区块数据的总量总是要比(块大小BLCKSZ - 空洞字节数 - 额外信息长度)要更小。 */ typedef struct XLogRecordBlockImageHeader { uint16 length; /* 页面镜像的字节数 */ uint16 hole_offset; /* 空洞前面的字节数 */ uint8 bimg_info; /* 标记位,详情见下 */ /* 如果 BKPIMAGE_HAS_HOLE 且 BKPIMAGE_IS_COMPRESSED, 后面会跟着 * XLogRecordBlockCompressHeader 结构体 */ } XLogRecordBlockImageHeader; /* 当页面镜像含有“空洞”且被压缩时,会用到这里的额外首部信息 */ typedef struct XLogRecordBlockCompressHeader { uint16 hole_length; /* number of bytes in "hole" */ } XLogRecordBlockCompressHeader; |
数据部分则由零或多个区块数据与零或一个主数据组成,区块数据与XLogRecordBlockHeader(s)对应,而主数据(main data)则与XLogRecordDataHeader对应。
WAL压缩
在9.5及其后的版本,可以通过设置
wal_compression = enable启用WAL压缩:使用LZ压缩方法对带有整页镜像的XLOG记录进行压缩。在这种情况下,会添加XLogRecordBlockCompressHeader结构。该功能有两个优点与一个缺点,优点是降低写入记录的I/O开销,并减小WAL段文件的消耗量;缺点是会消耗更多的CPU资源来执行压缩。
图9.10 XLOG记录样例(9.5及其后的版本)
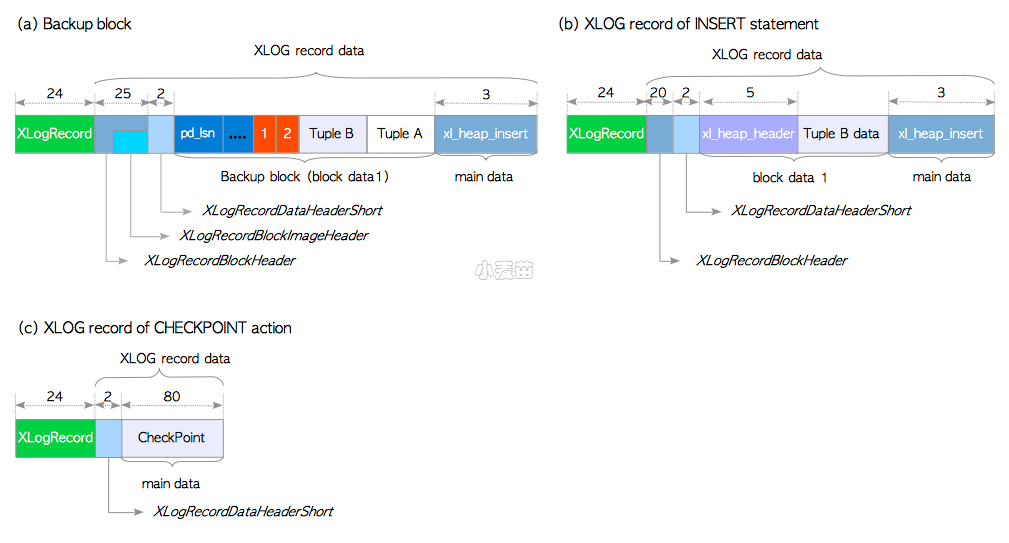
和前一小节一样,这里通过一些特例来描述。

