
合 PG中的分区表
Tags: PGPostgreSQL整理自网络分区表继承
- 表分区简介
- 传统方式实现分区
- 创建分区表
- 1 创建主表
- 2 创建分区表
- 3 分区键上建索引
- 4 创建触发器函数
- 5 创建触发器
- 查看分区表
- 1 查看所有表
- 2 查看主表
- 3 查看分区表
- 测试
- 插入数据
- 查看主表数据
- 查看分区表数据
- PG 10 新特性
- 范围分区
- 示例
- 列表分区
- 绑定分区
- 查询
- PG 11新特性
- hash分区语法
- 默认分区
- 多级分区
- ATTACH/DETACH 分区
- 外部表做为分区表
- 索引增强
- DML改进
- UPDATE可以在分区之间移动行
- INSERT/COPY可以路由到外部分区
- INSERT .. ON CONFLICT DO UPDATE/NOTHING
- 管理分区
- 移除数据/分区
- 增加分区
- 绑定分区
- 约束排除
- 约束排除关闭
- 约束排除开启
- 可选的分区方式
- PG分区表大小查询
- PG12之前
- PG12开始
- PG 15中的增强特性
- 总结
表分区简介
http://postgres.cn/docs/13/ddl-partitioning.html
在数据库日渐庞大的今天,为了方便对数据库数据的管理,比如按时间,按地区去统计一些数据时,基数过于庞大,多有不便。很多商业数据库都提供分区的概念,按不同的维度去存放数据,便于后期的管理,PostgreSQL也不例外。
PostgresSQL分区的意思是把逻辑上的一个大表分割成物理上的几块儿。分区不仅能带来访问速度的提升,关键的是,它能带来管理和维护上的方便。
分区的具体好处是:
- 某些类型的查询性能可以得到极大提升。
- 更新的性能也可以得到提升,因为表的每块的索引要比在整个数据集上的索引要小。如果索引不能全部放在内存里,那么在索引上的读和写都会产生更多的磁盘访问。
- 批量删除可以用简单的删除某个分区来实现。
- 可以将很少用的数据移动到便宜的、转速慢的存储介质上。
PostgreSQL 有两种父、子表关系:分区(partition)和继承(inherit)。
在PG里,表分区是通过表继承来实现的,一般都是建立一个主表,里面是空,然后每个分区都去继承它。无论何时,都应保证主表里面是空的。 在PG 10之前,只能通过表继承来实现分区,从PG 10开始,可以通过DDL语句来直接创建分区表(内部原理也是通过继承来实现),这被称为声明式分区表(declaratively patitioned table)或内置分区表。PG 10仅支持范围分区和列表分区,尚未支持散列Hash分区,PG 11支持Hash分区。
小表分区不实际,表在多大情况下才考虑分区呢?PostgresSQL官方给出的建议是:当表本身大小超过了机器物理内存的实际大小时(the size of the table should exceed the physical memory of the database server),可以考虑分区。
分区表注意事项:
不支持全局的唯一、主键、排除、外键约束,只能在对应的分区建立这些约束。
索引只能在分区中创建,在主表创建不能继承到分区中。
更新数据时不能进行数据跨分区移动,否则会报错。
分区表继承特性的限制:
i.分区除了主表外,不能继承其他父表;
ii.一个普通表不能继承分区表主表。
传统方式实现分区
参考:https://www.dbaup.com/pgzhongdebiaojichengheonlyguanjianci.html
创建分区表
1 创建主表
1 2 3 4 5 6 | create table tbl_partition ( id integer, name varchar(20), gender boolean, join_date date, dept char(4)); |
2 创建分区表
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | create table tbl_partition_202011 ( check ( join_date >= DATE '2020-11-01' AND join_date < DATE '2020-12-01' ) ) INHERITS (tbl_partition); create table tbl_partition_202012 ( check ( join_date >= DATE '2020-12-01' AND join_date < DATE '2021-01-01' ) ) INHERITS (tbl_partition); create table tbl_partition_202101 ( check ( join_date >= DATE '2021-01-01' AND join_date < DATE '2021-02-01' ) ) INHERITS (tbl_partition); create table tbl_partition_202102 ( check ( join_date >= DATE '2021-02-01' AND join_date < DATE '2021-03-01' ) ) INHERITS (tbl_partition); create table tbl_partition_202103 ( check ( join_date >= DATE '2021-03-01' AND join_date < DATE '2021-04-01' ) ) INHERITS (tbl_partition); create table tbl_partition_202104 ( check ( join_date >= DATE '2021-04-01' AND join_date < DATE '2021-05-01' ) ) INHERITS (tbl_partition); create table tbl_partition_202105 ( check ( join_date >= DATE '2021-05-01' AND join_date < DATE '2021-06-01' ) ) INHERITS (tbl_partition); |
查看分区:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 | postgres=## \d List of relations Schema | Name | Type | Owner --------+----------------------+-------+---------- public | tbl_partition | table | postgres public | tbl_partition_202011 | table | postgres public | tbl_partition_202012 | table | postgres public | tbl_partition_202101 | table | postgres public | tbl_partition_202102 | table | postgres public | tbl_partition_202103 | table | postgres public | tbl_partition_202104 | table | postgres public | tbl_partition_202105 | table | postgres (8 rows) postgres=## \d tbl_partition Table "public.tbl_partition" Column | Type | Collation | Nullable | Default -----------+-----------------------+-----------+----------+--------- id | integer | | | name | character varying(20) | | | gender | boolean | | | join_date | date | | | dept | character(4) | | | Number of child tables: 7 (Use \d+ to list them.) postgres=## \d+ tbl_partition Table "public.tbl_partition" Column | Type | Collation | Nullable | Default | Storage | Stats target | Description -----------+-----------------------+-----------+----------+---------+----------+--------------+------------- id | integer | | | | plain | | name | character varying(20) | | | | extended | | gender | boolean | | | | plain | | join_date | date | | | | plain | | dept | character(4) | | | | extended | | Child tables: tbl_partition_202011, tbl_partition_202012, tbl_partition_202101, tbl_partition_202102, tbl_partition_202103, tbl_partition_202104, tbl_partition_202105 Access method: heap postgres=## \d tbl_partition_202011 Table "public.tbl_partition_202011" Column | Type | Collation | Nullable | Default -----------+-----------------------+-----------+----------+--------- id | integer | | | name | character varying(20) | | | gender | boolean | | | join_date | date | | | dept | character(4) | | | Check constraints: "tbl_partition_202011_join_date_check" CHECK (join_date >= '2020-11-01'::date AND join_date < '2020-12-01'::date) Inherits: tbl_partition |
3 分区键上建索引
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | create index tbl_partition_202011_joindate on tbl_partition_202011 (join_date); create index tbl_partition_202012_joindate on tbl_partition_202012 (join_date); create index tbl_partition_202101_joindate on tbl_partition_202101 (join_date); create index tbl_partition_202102_joindate on tbl_partition_202102 (join_date); create index tbl_partition_202103_joindate on tbl_partition_202103 (join_date); create index tbl_partition_202104_joindate on tbl_partition_202104 (join_date); create index tbl_partition_202105_joindate on tbl_partition_202105 (join_date); postgres=## \d tbl_partition_202011 Table "public.tbl_partition_202011" Column | Type | Collation | Nullable | Default -----------+-----------------------+-----------+----------+--------- id | integer | | | name | character varying(20) | | | gender | boolean | | | join_date | date | | | dept | character(4) | | | Indexes: "tbl_partition_202011_joindate" btree (join_date) Check constraints: "tbl_partition_202011_join_date_check" CHECK (join_date >= '2020-11-01'::date AND join_date < '2020-12-01'::date) Inherits: tbl_partition |
4 创建触发器函数
对于开发人员来说,希望数据库是透明的,只管 insert into tbl_partition。对于数据插向哪个分区,则希望由DB决定。这点,ORACLE实现了,但是PG不行,需要前期人工处理下。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | CREATE OR REPLACE FUNCTION tbl_partition_insert_trigger() RETURNS TRIGGER AS $$ BEGIN IF ( NEW.join_date >= DATE '2020-11-01' AND NEW.join_date < DATE '2020-12-01' ) THEN INSERT INTO tbl_partition_202011 VALUES (NEW.*); ELSIF ( NEW.join_date >= DATE '2020-12-01' AND NEW.join_date < DATE '2021-01-01' ) THEN INSERT INTO tbl_partition_202012 VALUES (NEW.*); ELSIF ( NEW.join_date >= DATE '2021-01-01' AND NEW.join_date < DATE '2021-02-01' ) THEN INSERT INTO tbl_partition_202101 VALUES (NEW.*); ELSIF ( NEW.join_date >= DATE '2021-02-01' AND NEW.join_date < DATE '2021-03-01' ) THEN INSERT INTO tbl_partition_202102 VALUES (NEW.*); ELSIF ( NEW.join_date >= DATE '2021-03-01' AND NEW.join_date < DATE '2021-04-01' ) THEN INSERT INTO tbl_partition_202103 VALUES (NEW.*); ELSIF ( NEW.join_date >= DATE '2021-04-01' AND NEW.join_date < DATE '2021-05-01' ) THEN INSERT INTO tbl_partition_202104 VALUES (NEW.*); ELSIF ( NEW.join_date >= DATE '2021-05-01' AND NEW.join_date < DATE '2021-06-01' ) THEN INSERT INTO tbl_partition_202105 VALUES (NEW.*); ELSE RAISE EXCEPTION 'Date out of range. Fix the tbl_partition_insert_trigger() function!'; END IF; RETURN NULL; END; $$ LANGUAGE plpgsql; |
说明:如果不想丢失数据,上面的ELSE 条件可以改成 INSERT INTO tbl_partition_error_join_date VALUES (NEW.*); 同时需要创建一张结构和tbl_partition 一样的表tbl_partition_error_join_date,这样,错误的join_date 数据就可以插入到这张表中而不是报错了。
5 创建触发器
1 2 3 | CREATE TRIGGER insert_tbl_partition_trigger BEFORE INSERT ON tbl_partition FOR EACH ROW EXECUTE PROCEDURE tbl_partition_insert_trigger(); |
查看分区表
注意:通过这种方式创建的分区表,视图pg_partitioned_table不显示数据。
1 查看所有表
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | \dt List of relations Schema | Name | Type | Owner --------+----------------------+-------+---------- public | tbl_partition | table | postgres public | tbl_partition_202011 | table | postgres public | tbl_partition_202012 | table | postgres public | tbl_partition_202101 | table | postgres public | tbl_partition_202102 | table | postgres public | tbl_partition_202103 | table | postgres public | tbl_partition_202104 | table | postgres public | tbl_partition_202105 | table | postgres (8 rows) |
2 查看主表
1 2 3 4 5 6 7 8 9 10 11 12 13 | \d tbl_partition Table "public.tbl_partition" Column | Type | Modifiers -----------+-----------------------+----------- id | integer | name | character varying(20) | gender | boolean | join_date | date | dept | character(4) | Triggers: insert_tbl_partition_trigger BEFORE INSERT ON tbl_partition FOR EACH ROW EXECUTE PROCEDURE tbl_partition_insert_trigger() Number of child tables: 7 (Use \d+ to list them.) |
3 查看分区表
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | \d tbl_partition_202104 Table "public.tbl_partition_202104" Column | Type | Modifiers -----------+-----------------------+----------- id | integer | name | character varying(20) | gender | boolean | join_date | date | dept | character(4) | Indexes: "tbl_partition_202104_joindate" btree (join_date) Check constraints: "tbl_partition_202104_join_date_check" CHECK (join_date >= '2021-04-01'::date AND join_date < '2021-05-01'::date) Inherits: tbl_partition |
测试
插入数据
1 2 3 4 5 6 7 8 9 10 11 12 13 | insert into tbl_partition values (1, 'David', '1', '2021-01-10', 'TS'); insert into tbl_partition values (2, 'Sandy', '0', '2021-02-10', 'TS'); insert into tbl_partition values (3, 'Eagle', '1', '2020-11-01', 'TS'); insert into tbl_partition values (4, 'Miles', '1', '2020-12-15', 'SD'); insert into tbl_partition values (5, 'Simon', '1', '2020-12-10', 'SD'); insert into tbl_partition values (6, 'Rock', '1', '2020-11-10', 'SD'); insert into tbl_partition values (7, 'Peter', '1', '2021-01-11', 'SD'); insert into tbl_partition values (8, 'Sally', '0', '2021-03-10', 'BCSC'); insert into tbl_partition values (9, 'Carrie', '0', '2021-04-02', 'BCSC'); insert into tbl_partition values (10, 'Lee', '1', '2021-01-05', 'BMC'); insert into tbl_partition values (11, 'Nicole', '0', '2020-11-10', 'PROJ'); insert into tbl_partition values (12, 'Renee', '0', '2021-01-10', 'TS'); |
查看主表数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | select * from tbl_partition; id | name | gender | join_date | dept ----+--------+--------+------------+------ 3 | Eagle | t | 2020-11-01 | TS 6 | Rock | t | 2020-11-10 | SD 11 | Nicole | f | 2020-11-10 | PROJ 4 | Miles | t | 2020-12-15 | SD 5 | Simon | t | 2020-12-10 | SD 1 | David | t | 2021-01-10 | TS 7 | Peter | t | 2021-01-11 | SD 10 | Lee | t | 2021-01-05 | BMC 12 | Renee | f | 2021-01-10 | TS 2 | Sandy | f | 2021-02-10 | TS 8 | Sally | f | 2021-03-10 | BCSC 9 | Carrie | f | 2021-04-02 | BCSC (12 rows) |
查看分区表数据
1 2 3 4 5 6 7 8 9 | select * from tbl_partition_202101 ; id | name | gender | join_date | dept ----+-------+--------+------------+------ 1 | David | t | 2021-01-10 | TS 7 | Peter | t | 2021-01-11 | SD 10 | Lee | t | 2021-01-05 | BMC 12 | Renee | f | 2021-01-10 | TS (4 rows) |
PG 10 新特性
PG10之前实现分区表功能,基本是根据“继承表+约束+规则或触发器”实现,相对于之前的分区实现方式,PG10的分区特性有以下优势:
1)管理分区方便
2)数据插入效率高
注意:
- 主表和分区分别单独创建
- 范围分区支持多个字段组成的KEY
- 列表分区的KEY只能有一个字段
创建主表语法:
1 2 3 | CREATE TABLE 表名 ( [{ 列名称 数据_类型} [, … ] ] ) PARTITION BY RANGE ( [{ 列名称 } [, …] ] ); 范围分区的KEY值可由多个字段组成(最多32个字段)。 |
创建分区语法:
1 2 3 | CREATE TABLE 表名 PARTITION OF 主表 FOR VALUES FROM{ ( 表达式 [, …] ) | MINVALUE } [, …] TO { ( 表达式 [, …] ) | MAXVALUE } [, …] [ TABLESPACE 表空间名 ]; |
参数说明:
// FROM … TO 表示分区的起始值和结束值。
// MINVALUE / MAXVALUE 表示无限小值和无限大值。
// 默认FROM后面的值是包括值分区的约束内,TO后面的值不包括。
范围分区
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 | create table tbp(n int, t text) partition by range(n); create table tbp_1 partition of tbp for values from (MINVALUE) to (10); create table tbp_2 partition of tbp for values from (10) to (100); create table tbp_3 partition of tbp for values from (100) to (1000); create table tbp_4 partition of tbp for values from (1000) to (MAXVALUE); lhrdb=## \d List of relations Schema | Name | Type | Owner --------+-------+-------------------+---------- public | tbp | partitioned table | postgres public | tbp_1 | table | postgres public | tbp_2 | table | postgres public | tbp_3 | table | postgres public | tbp_4 | table | postgres (5 rows) lhrdb=## select * from pg_partitioned_table; partrelid | partstrat | partnatts | partdefid | partattrs | partclass | partcollation | partexprs -----------+-----------+-----------+-----------+-----------+-----------+---------------+----------- 41034 | r | 1 | 0 | 1 | 1978 | 0 | (1 row) lhrdb=## \d+ tbp Partitioned table "public.tbp" Column | Type | Collation | Nullable | Default | Storage | Stats target | Description --------+---------+-----------+----------+---------+----------+--------------+------------- n | integer | | | | plain | | t | text | | | | extended | | Partition key: RANGE (n) Partitions: tbp_1 FOR VALUES FROM (MINVALUE) TO (10), tbp_2 FOR VALUES FROM (10) TO (100), tbp_3 FOR VALUES FROM (100) TO (1000), tbp_4 FOR VALUES FROM (1000) TO (MAXVALUE) -- 获取分区类型和KEY SELECT pg_get_partkeydef('tbp'::regclass); -- 获取分区范围 SELECT pg_get_partition_constraintdef('tbp_1'::regclass) ; lhrdb=## SELECT pg_get_partkeydef('tbp'::regclass); pg_get_partkeydef ------------------- RANGE (n) (1 row) lhrdb=## SELECT pg_get_partition_constraintdef('tbp_1'::regclass) ; pg_get_partition_constraintdef -------------------------------- ((n IS NOT NULL) AND (n < 10)) (1 row) |
多个key:
1 2 3 4 5 6 7 8 9 10 11 12 | create table test(n1 int, n2 int) partition by range(n1, n2); create table test_1 partition of test for values from (0, 0) to (10, 100); lhrdb=## \d+ test_1 Table "public.test_1" Column | Type | Collation | Nullable | Default | Storage | Stats target | Description --------+---------+-----------+----------+---------+---------+--------------+------------- n1 | integer | | | | plain | | n2 | integer | | | | plain | | Partition of: test FOR VALUES FROM (0, 0) TO (10, 100) Partition constraint: ((n1 IS NOT NULL) AND (n2 IS NOT NULL) AND ((n1 > 0) OR ((n1 = 0) AND (n2 >= 0))) AND ((n1 < 10) OR ((n1 = 10) AND (n2 < 100)))) Access method: heap |
n1范围从0到10,n2范围从0到100。
示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 | create table test(n int) partition by range(n); create table test_1 partition of test for values from (MINVALUE) to (10); create table test_2 partition of test for values from (10) to (100); create table test_3 partition of test for values from (100) to (1000); create table test_4 partition of test for values from (1000) to (10000); lhrdb3=## \d+ test Partitioned table "public.test" Column | Type | Collation | Nullable | Default | Storage | Stats target | Description --------+---------+-----------+----------+---------+---------+--------------+------------- n | integer | | | | plain | | Partition key: RANGE (n) Partitions: test_1 FOR VALUES FROM (MINVALUE) TO (10), test_2 FOR VALUES FROM (10) TO (100), test_3 FOR VALUES FROM (100) TO (1000), test_4 FOR VALUES FROM (1000) TO (10000) lhrdb3=# lhrdb3=## \d+ test_2 Table "public.test_2" Column | Type | Collation | Nullable | Default | Storage | Stats target | Description --------+---------+-----------+----------+---------+---------+--------------+------------- n | integer | | | | plain | | Partition of: test FOR VALUES FROM (10) TO (100) Partition constraint: ((n IS NOT NULL) AND (n >= 10) AND (n < 100)) Access method: heap lhrdb3=## insert into test select generate_series(0, 9999); INSERT 0 10000 lhrdb3=## explain analyze select * from test; QUERY PLAN --------------------------------------------------------------------------------------------------------------- Append (cost=0.00..337.75 rows=17850 width=4) (actual time=0.025..3.566 rows=10000 loops=1) -> Seq Scan on test_1 (cost=0.00..35.50 rows=2550 width=4) (actual time=0.024..0.027 rows=10 loops=1) -> Seq Scan on test_2 (cost=0.00..35.50 rows=2550 width=4) (actual time=0.017..0.028 rows=90 loops=1) -> Seq Scan on test_3 (cost=0.00..35.50 rows=2550 width=4) (actual time=0.029..0.204 rows=900 loops=1) -> Seq Scan on test_4 (cost=0.00..142.00 rows=10200 width=4) (actual time=0.029..2.049 rows=9000 loops=1) Planning Time: 0.175 ms Execution Time: 4.186 ms (7 rows) |
列表分区
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 | CREATE TABLE sales (product_id int, saleroom int, province text) PARTITION BY LIST(province); CREATE TABLE sales_east PARTITION OF sales FOR VALUES IN ('山东','江苏','上海'); CREATE TABLE sales_west PARTITION OF sales FOR VALUES IN ('山西','陕西','四川'); CREATE TABLE sales_north PARTITION OF sales FOR VALUES IN ('北京','河北','辽宁'); CREATE TABLE sales_south PARTITION OF sales FOR VALUES IN ('广东','福建'); lhrdb2=## \dt List of relations Schema | Name | Type | Owner --------+-------------+-------------------+---------- public | sales | partitioned table | postgres public | sales_east | table | postgres public | sales_north | table | postgres public | sales_south | table | postgres public | sales_west | table | postgres (5 rows) lhrdb2=## insert into sales values(1,1,'山东'),(2,2,'山西'),(3,3,'北京'),(4,4,'广东'); INSERT 0 4 lhrdb2=## select * from sales; product_id | saleroom | province ------------+----------+---------- 1 | 1 | 山东 3 | 3 | 北京 2 | 2 | 山西 4 | 4 | 广东 (4 rows) lhrdb2=## select * from sales_east; product_id | saleroom | province ------------+----------+---------- 1 | 1 | 山东 (1 row) lhrdb2=## select * from sales_west; product_id | saleroom | province ------------+----------+---------- 2 | 2 | 山西 (1 row) |
绑定分区
分区表支持把普通表绑定成父表的一个分区,也支持把分区解绑为普通表。
若普通表中有数据,ATTACH操作时,默认会做数据校验。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | CREATE TABLE sales_foreign (like sales); ALTER TABLE sales ATTACH PARTITION sales_foreign FOR VALUES IN('美国','日本'); lhrdb2=## \d+ sales Partitioned table "public.sales" Column | Type | Collation | Nullable | Default | Storage | Stats target | Description ------------+---------+-----------+----------+---------+----------+--------------+------------- product_id | integer | | | | plain | | saleroom | integer | | | | plain | | province | text | | | | extended | | Partition key: LIST (province) Partitions: sales_east FOR VALUES IN ('山东', '江苏', '上海'), sales_foreign FOR VALUES IN ('美国', '日本'), sales_north FOR VALUES IN ('北京', '河北', '辽宁'), sales_south FOR VALUES IN ('广东', '福建'), sales_west FOR VALUES IN ('山西', '陕西', '四川') lhrdb2=## ALTER TABLE sales DETACH PARTITION sales_foreign; ALTER TABLE lhrdb2=## \d+ sales Partitioned table "public.sales" Column | Type | Collation | Nullable | Default | Storage | Stats target | Description ------------+---------+-----------+----------+---------+----------+--------------+------------- product_id | integer | | | | plain | | saleroom | integer | | | | plain | | province | text | | | | extended | | Partition key: LIST (province) Partitions: sales_east FOR VALUES IN ('山东', '江苏', '上海'), sales_north FOR VALUES IN ('北京', '河北', '辽宁'), sales_south FOR VALUES IN ('广东', '福建'), sales_west FOR VALUES IN ('山西', '陕西', '四川') |
查询
获取系统信息(系统表):
pg_partitioned_table 记录主表信息的系统表:
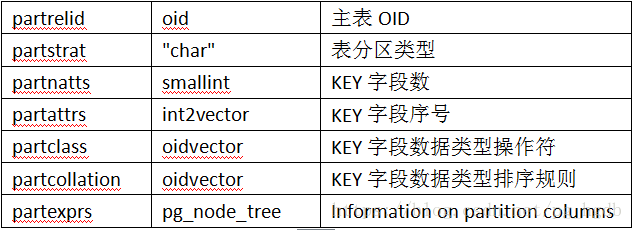
分区的信息记录在pg_class相关的字段中:
PG 11新特性
PostgreSQL 11 为分区表功能提供更多的改进。这些特性包括:hash 分区、索引增强、DML改进,以及性能优化:faster partition pruning、run-time partition pruning,、partition-wise join。
- pg11新增了hash partition
- pg11中可以建立default partition(默认分区)
- pg11中可以对partition key进行更新
- pg11中在partitioned table(主表)上建立索引,索引会自动建立在partition(子表)上
- pg11中可以在partitioned table上建立unique constraints
- 在pg11中attach分区时,会自动给该新分区建立唯一约束和索引
- pg_partition_tree函数,返回分区表详细信息,例如分区名称、上一级分区名称、是否叶子结点、层级,层级为零表示顶层主表。
- pg_partition_root函数用于当已知partition时查询出分区表顶层主表的名字
- pg_partition_ancestors返回上层分区名称,包括本层分区名称。
hash分区语法
1 2 3 4 5 6 7 8 9 | -- 主表 CREATE TABLE table_name ( column_name data_type ) PARTITION BY HASH ( { column_name } [, ... ] ) -- 子表 CREATE TABLE table_name PARTITION OF parent_table FOR VALUES WITH ( MODULUS numeric_literal, REMAINDER numeric_literal ) |
哈希分区支持多列分区,下面给出示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | create table test_hash(id int, date date) partition by hash(id); create table test_hash_1 partition of test_hash for values with(modulus 2, remainder 0); create table test_hash_2 partition of test_hash for values with(modulus 2, remainder 1); \d+ test_hash Table "public.test_hash" Column | Type | Collation | Nullable | Default | Storage | Stats target | Description --------+---------+-----------+----------+---------+---------+--------------+------------- id | integer | | | | plain | | date | date | | | | plain | | Partition key: HASH (id) Partitions: test_hash_1 FOR VALUES WITH (modulus 2, remainder 0), test_hash_2 FOR VALUES WITH (modulus 2, remainder 1) \d+ test_hash_1 Table "public.test_hash_1" Column | Type | Collation | Nullable | Default | Storage | Stats target | Description --------+---------+-----------+----------+---------+---------+--------------+------------- id | integer | | | | plain | | date | date | | | | plain | | Partition of: test_hash FOR VALUES WITH (modulus 2, remainder 0) Partition constraint: satisfies_hash_partition('16603'::oid, 2, 0, id) |
示例2:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | create table test_hash_key(x int, y int) partition by hash(x,y); create table test_hash_key_1 partition of test_hash_key for values with(modulus 2, remainder 0); create table test_hash_key_2 partition of test_hash_key for values with(modulus 2, remainder 1); \d+ test_hash_key Table "public.test_hash_key" Column | Type | Collation | Nullable | Default | Storage | Stats target | Description --------+---------+-----------+----------+---------+---------+--------------+------------- x | integer | | | | plain | | y | integer | | | | plain | | Partition key: HASH (x, y) Partitions: test_hash_key_1 FOR VALUES WITH (modulus 2, remainder 0), test_hash_key_2 FOR VALUES WITH (modulus 2, remainder 1) \d+ test_hash_key_1 Table "public.test_hash_key_1" Column | Type | Collation | Nullable | Default | Storage | Stats target | Description --------+---------+-----------+----------+---------+---------+--------------+------------- x | integer | | | | plain | | y | integer | | | | plain | | Partition of: test_hash_key FOR VALUES WITH (modulus 2, remainder 0) Partition constraint: satisfies_hash_partition('16561'::oid, 2, 0, x, y) |
默认分区
PostgreSQL 11新特性,防止插入失败,对于不符合分区约束的数据将会插入到默认分区。目前,range/list支持默认分区,hash分区不支持
语法:
1 2 3 4 | CREATE TABLE table_name PARTITION OF parent_table FOR VALUES DEFAULT |
示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 | -- range create table test_range_default partition of test_range default; \d+ test_range Table "public.test_range" Column | Type | Collation | Nullable | Default | Storage | Stats target | Description --------+---------+-----------+----------+---------+---------+--------------+------------- id | integer | | | | plain | | date | date | | | | plain | | Partition key: RANGE (date) Partitions: test_range_201801 FOR VALUES FROM ('2018-01-01') TO ('2018-02-01'), test_range_201802 FOR VALUES FROM ('2018-02-01') TO ('2018-03-01'), test_range_default DEFAULT \d+ test_range_default Table "public.test_range_default" Column | Type | Collation | Nullable | Default | Storage | Stats target | Description --------+---------+-----------+----------+---------+---------+--------------+------------- id | integer | | | | plain | | date | date | | | | plain | | Partition of: test_range DEFAULT Partition constraint: (NOT ((date IS NOT NULL) AND (((date >= '2018-01-01'::date) AND (date < '2018-02-01'::date)) OR ((date >= '2018-02-01'::date) AND (date < '2018-03-01'::date))))) -- list create table test_list_default partition of test_list default; \d+ test_list Table "public.test_list" Column | Type | Collation | Nullable | Default | Storage | Stats target | Description --------+---------+-----------+----------+---------+----------+--------------+------------- id | integer | | | | plain | | city | text | | | | extended | | Partition key: LIST (city) Partitions: test_list_hz FOR VALUES IN ('杭州'), test_list_jn FOR VALUES IN ('济南'), test_list_default DEFAULT \d+ test_list_default Table "public.test_list_default" Column | Type | Collation | Nullable | Default | Storage | Stats target | Description --------+---------+-----------+----------+---------+----------+--------------+------------- id | integer | | | | plain | | city | text | | | | extended | | Partition of: test_list DEFAULT Partition constraint: (NOT ((city IS NOT NULL) AND (city = ANY (ARRAY['杭州'::text, '济南'::text])))) -- hash create table test_hash_default partition of test_hash default; ERROR: a hash-partitioned table may not have a default partition |
默认分区可以防止插入失败:
1 2 3 4 5 6 7 8 9 | insert into test_list values (3, '北京'); select *, tableoid::regclass from test_list; id | city | tableoid ----+------+------------------- 1 | 杭州 | test_list_hz 2 | 济南 | test_list_jn 3 | 北京 | test_list_default (3 rows) |
多级分区
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 | create table test_range_list(id int, city text, date date) partition by list (city); create table test_range_list_jn partition of test_range_list for values in ('济南') partition by range(date); create table test_range_list_hz partition of test_range_list for values in ('杭州') partition by range(date); create table test_range_list_jn_201801 partition of test_range_list_jn for values from ('2018-01-01') to ('2018-02-01'); create table test_range_list_jn_201802 partition of test_range_list_jn for values from ('2018-02-01') to ('2018-03-01'); create table test_range_list_hz_201801 partition of test_range_list_hz for values from ('2018-01-01') to ('2018-02-01'); create table test_range_list_hz_201802 partition of test_range_list_hz for values from ('2018-02-01') to ('2018-03-01'); \d+ test_range_list Table "public.test_range_list" Column | Type | Collation | Nullable | Default | Storage | Stats target | Description --------+---------+-----------+----------+---------+----------+--------------+------------- id | integer | | | | plain | | city | text | | | | extended | | date | date | | | | plain | | Partition key: LIST (city) Partitions: test_range_list_hz FOR VALUES IN ('杭州'), PARTITIONED, test_range_list_jn FOR VALUES IN ('济南'), PARTITIONED \d+ test_range_list_jn Table "public.test_range_list_jn" Column | Type | Collation | Nullable | Default | Storage | Stats target | Description --------+---------+-----------+----------+---------+----------+--------------+------------- id | integer | | | | plain | | city | text | | | | extended | | date | date | | | | plain | | Partition of: test_range_list FOR VALUES IN ('济南') Partition constraint: ((city IS NOT NULL) AND (city = '济南'::text)) Partition key: RANGE (date) Partitions: test_range_list_jn_201801 FOR VALUES FROM ('2018-01-01') TO ('2018-02-01'), test_range_list_jn_201802 FOR VALUES FROM ('2018-02-01') TO ('2018-03-01') \d+ test_range_list_jn_201801 Table "public.test_range_list_jn_201801" Column | Type | Collation | Nullable | Default | Storage | Stats target | Description --------+---------+-----------+----------+---------+----------+--------------+------------- id | integer | | | | plain | | city | text | | | | extended | | date | date | | | | plain | | Partition of: test_range_list_jn FOR VALUES FROM ('2018-01-01') TO ('2018-02-01') Partition constraint: ((city IS NOT NULL) AND (city = '济南'::text) AND (date IS NOT NULL) AND (date >= '2018-01-01'::date) AND (date < '2018-02-01'::date)) |
ATTACH/DETACH 分区
语法:
1 2 3 4 5 | ALTER TABLE name ATTACH PARTITION partition_name { FOR VALUES partition_bound_spec | DEFAULT } ALTER TABLE name DETACH PARTITION partition_name |
以hash分区示例进行演示


