合 Oracle等待事件队列等待之enq US - contention
Tags: Oracle等待事件enq US - contention
前言部分
导读和注意事项
各位技术爱好者,看完本文后,你可以掌握如下的技能,也可以学到一些其它你所不知道的知识,~O(∩_∩)O~:
① enq: US - contention等待事件的解决
② 一般等待事件的解决办法
③ 队列等待的基本知识
故障分析及解决过程
故障环境介绍
| 项目 | source db |
|---|---|
| db 类型 | RAC |
| db version | 11.2.0.4.0 |
| db 存储 | ASM |
| OS版本及kernel版本 | AIX 64位 7.1.0.0 |
故障发生现象及报错信息
最近系统做压测,碰到的问题比较多,今天同事发了个AWR报告,说是系统响应很慢,我简单看了下,简单分析下吧:

270分钟时间而DB Time为2000多分钟,DB Time太高了,负载很大,很可能有异常的等待事件,系统配置还是比较牛逼的。
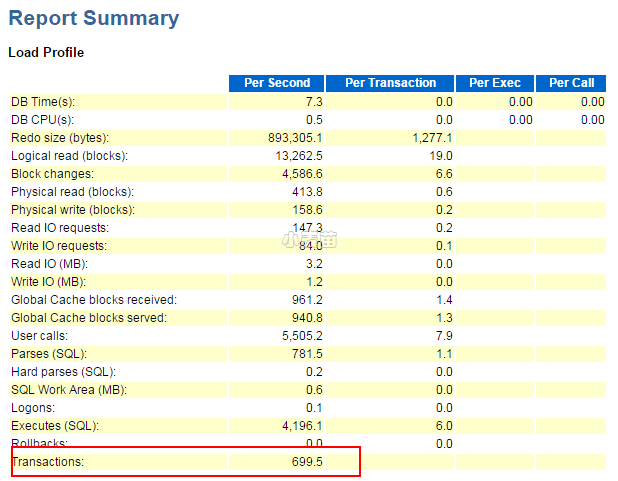
事务量很大,其它个别参数有点问题,不一一解说了。等待事件很明显了:
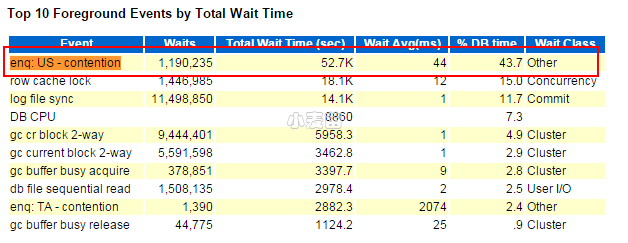
AWR的其它部分就不分析了,首先这个等待事件:enq: US - contention比较少见,查了一下资料,有点收获:
SELECT * FROM V$EVENT_NAME WHERE NAME = 'enq: US - contention';

SELECT * FROM v$lock_type d WHERE d.TYPE='US';

"enq: US - contention",这个event说明事务在队列中等待UNDO Segment,通常是由于UNDO空间不足导致的。
在对此事件说明之前,需要理解在使用AUM(atuomatic undo management)时,回滚段在何时联机或脱机。AUM与RBU(rollback segment management)不同,回滚段的管理是Oracle自动完成的。使用AUM时,回滚段的联机或脱机的时刻如下:
1)在执行alter database open的时候将回滚段联机
2)通过alter system set undo_tablespace=xxx 修改撤销表空间时,将原来的回滚段脱机后,再将新的回滚段联机。
3)通过SMON,自动脱机或者联机回滚段,如果一段时间内,事务量增加,联机状态的回滚段也会增加,一段时间内若是没有实物或事务减少,回滚段就会被smon进程脱机。
为了同步将回滚段联机或脱机的过程,执行该工作的服务器进程或后台进程应获得US锁,每个回滚段非配一个US锁,ID1=Undo segment#。若在获得US锁的过程中发生争用,则等待enq:US-contention事件。服务器进程应该在开始事务时分配到回滚段,但如果不存在可用的回滚段时,应该创建新的回滚段或将脱机状态的回滚段联机。在实现此项工作期间,服务器进程为了获得US锁而等待,等待占有可用回滚段。
这是oracle10g中开始出现的bug(在11.1.0.7中仍有这个BUG),当因为系统activity增加或者降低的时候,oracle SMON进程会自动ONLINE或者OFFLINE rollback segments。这样导致某些与undo segments相关的latch或者enqueue被hold住太长时间,导致系统很多活跃session都开始等待enq: US - contention。可以同时使用以下解决方法:
1. 设置event让SMON不自动OFFLINE回滚段
alter system set events '10511 trace name context forever, level 1';
2. 设置参数_rollback_segment_count :表示有多少rollback segment要处于online的状态;可以将该数值设置为数据库最繁忙的时候的回滚段数目。
alter system set "_rollback_segment_count"=1000 SID='*';
这里以"_"开头的为隐藏参数,通过show parameter 是看不到的,可以通过以下语句:
select a.ksppinm name, b.ksppstvl value, a.ksppdesc description
from x$ksppi a, x$ksppcv b
where a.indx = b.indx
and a.ksppinm like '%_rollback_segment_count%';
3. undo autotune bug多多。最好disable。
alter system set "_undo_autotune"= false;
这种方法就是关闭了UNDO的自动调整功能,同时也能解决掉UNDO表空间会在很长时间都一直保持着使用率是接近100%的问题。
4. 有一个patch: A fix to bug 7291739 is to set a new hidden parameter, _highthreshold_undoretention to set a high threshold for undo retention completely distinct from maxquerylen.
alter system set "_highthreshold_undoretention"=;
- 增加undo表空间
alter tablespace UNDOTBS1 add datafile '+DATA1' size 30G;
- 设置undo表空间的NOGUARANTEE
select tablespace_name, retention from dba_tablespaces where tablespace_name like 'UNDO%';
ALTER TABLESPACE UNDOTBS RETENTION NOGUARANTEE;
- 减少UNDO_RETENTION的时间
SQL> show parameter undo
NAME TYPE VALUE
------------------ ---------------------- --------
undo_management string AUTO
undo_retention integer 10800
- 重启数据库节点
故障分析及解决
我们查询ASH视图看看当时的情况:
SELECT D.SQL_ID,CHR(BITAND(P1, -16777216) / 16777215) ||