合 Oracle死锁的分类及其模拟过程
前言部分
导读和注意事项
各位技术爱好者,看完本文后,你可以掌握如下的技能,也可以学到一些其它你所不知道的知识,\~O(∩_∩)O\~:
① 死锁的概念及其trace文件
② 死锁的分类
③ 行级死锁的模拟
④ ITL的概念、ITL结构
⑤ ITL引发的死锁处理
⑥ ITL死锁的模拟
本文简介
写了近大半年的书了,碰到了各种困难,不过幸运的是基本上都一一克服了。前段时间工作上碰到了一个很奇怪的死锁问题,由业务发出来的SQL来看是不太可能产生死锁的,不过的的确确实实在在的产生了,那作者是碰到了哪一类的死锁呢?ITL死锁!!有关当时的案例可以参考:http://blog.itpub.net/26736162/viewspace-2124771/和http://blog.itpub.net/26736162/viewspace-2124735/。于是,作者就把死锁可能出现的情况都分类总结了一下,分享给大家,欢迎大家指出错误。本文内容也将写入作者的新书中,欢迎大家提前订阅。
死锁(DeadLock)的分类及其模拟
死锁简介
什么是死锁?
所谓死锁,是指两个或两个以上的进程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程。Oracle对于“死锁”是要做处理的,而不是不闻不问。
1 2 3 4 5 | [ZFLHRDB1:oracle]:/oracle>oerr ora 60 00060, 00000, "deadlock detected while waiting for resource" // *Cause: Transactions deadlocked one another while waiting for resources. // *Action: Look at the trace file to see the transactions and resources // involved. Retry if necessary. |
Cause: Your session and another session are waiting for are source locked by the other. This condition is known AS a deadlock. To resolve the deadlock, one or more statements were rolled back for the other session to continue work.
Action Either: l. Enter arollback statement and re—execute all statements since the last commit or 2. Wait until the lock is released, possibly a few minutes, and then re—execute the rolled back statements.
死锁的trace文件
Oracle中产生死锁的时候会在alert告警日志文件中记录死锁的相关信息,无论单机还是RAC环境都有Deadlock这个关键词,而且当发生死锁时都会生成一个trace文件,这个文件名在alert文件中都有记载。由于在RAC环境中,是由LMD(Lock Manager Daemon)进程统一管理各个节点之间的锁资源的,所以,RAC环境中trace文件是由LMD进程来生成的。
在RAC环境中,告警日志的形式如下所示:
1 2 3 | Mon Jun 20 10:10:56 2016 Global Enqueue Services Deadlock detected. More info in file /u01/app/oracle/diag/rdbms/raclhr/raclhr2/trace/raclhr2_lmd0_19923170.trc. |
在单机环境中,告警日志的形式如下所示:
1 2 | Mon Jun 20 12:10:56 2016 ORA-00060: Deadlock detected. More info in file /u01/app/oracle/diag/rdbms/dlhr/dlhr/trace/dlhr_ora_16973880.trc. |
通常来讲,对于单机环境,当有死锁发生后,在trace文件中会看到如下的日志信息:
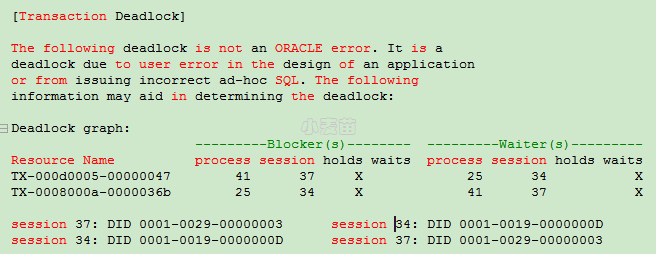
图 2-1 单机环境下的死锁
当看到trace文件时,需要确认一下产生锁的类型,是两行还是一行,是TX还是TM,如果只有一行那么说明是同一个SESSION,可能是自治事务引起的死锁。
对于RAC环境,当有死锁发生后,在trace文件中会看到如下的日志信息:

图 2-2 RAC环境下的死锁
死锁的检测时间
死锁的监测时间是由隐含参数_lm_dd_interval来控制的,在Oracle 11g中,隐含参数_lm_dd_interval的值默认为10,而在Oracle 10g中该参数默认为60,单位为秒。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | SYS@oraLHRDB2> SELECT A.INDX, 2 A.KSPPINM NAME, 3 A.KSPPDESC, 4 B.KSPPSTVL 5 FROM X$KSPPI A, 6 X$KSPPCV B 7 WHERE A.INDX = B.INDX 8 AND LOWER(A.KSPPINM) LIKE LOWER('%&PARAMETER%'); ENTER VALUE FOR PARAMETER: _lm_dd_interval OLD 8: AND LOWER(A.KSPPINM) LIKE LOWER('%&PARAMETER%') NEW 8: AND LOWER(A.KSPPINM) LIKE LOWER('%_LM_DD_INTERVAL%') INDX NAME KSPPDESC KSPPSTVL ---------- ------------------ ------------------------------ -------------------- 578 _lm_dd_interval dd time interval in seconds 10 |
可以看到该隐含参数的值为10。
死锁的分类
有人的地方就有江湖,有资源阻塞的地方就可能有死锁。Oralce中最常见的死锁分为:行级死锁(Row-Level Deadlock)和块级死锁(Block-Level Deadlock),其中,行级死锁分为①主键、唯一索引的死锁(会话交叉插入相同的主键值),②外键未加索引,③表上的位图索引遭到并发更新,④常见事务引发的死锁(例如,两个表之间不同顺序相互更新操作引起的死锁;同一张表删除和更新之间引起的死锁),⑤自治事务引发的死锁。块级死锁主要指的是ITL(Interested Transaction List)死锁。
死锁分类图如下所示:

图 2-3 死锁的分类图
行级死锁
行级锁的发生如下图所示,在A时间,TRANSACRION1和TRANSCTION2分别锁住了它们要UPDATE的一行数据,没有任何问题。但每个TRANSACTION都没有终止。接下来在B时间,它们又试图UPDATE当前正被对方TRANSACTION锁住的行,因此双方都无法获得资源,此时就出现了死锁。之所以称之为死锁,是因为无论每个TRANSACTION等待多久,这种锁都不会被释放。

行级锁的死锁一般是由于应用逻辑设计的问题造成的,其解决方法是通过分析trace文件定位出造成死锁的SQL语句、被互相锁住资源的对象及其记录等信息,提供给应用开发人员进行分析,并修改特定或一系列表的更新(UPDATE)顺序。
以下模拟各种行级死锁的产生过程,版本都是11.2.0.4。
主键、唯一索引的死锁(会话交叉插入相同的主键值)
主键的死锁其本质是唯一索引引起的死锁,这个很容易模拟出来的,新建一张表,设置主键(或创建唯一索引)后插入一个值,然后不要COMMIT,另一个会话插入另一个值,也不要COMMIT,然后再把这两个插入的值互相交换一下,在两个会话中分别插入,死锁就会产生。
会话1,sid为156:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | SYS@lhrdb> set sqlprompt "_user'@'_connect_identifier S1> " SYS@lhrdb S1> DROP TABLE T_DEADLOCK_PRIMARY_LHR; Table dropped. ====>>>>> CREATE UNIQUE INDEX IDX_TEST_LHR ON T_DEADLOCK_PRIMARY_LHR(ID); SYS@lhrdb S1> CREATE TABLE T_DEADLOCK_PRIMARY_LHR(ID NUMBER PRIMARY KEY); Table created. SYS@lhrdb S1> select userenv('sid') from dual; USERENV('SID') -------------- 156 SYS@lhrdb S1> INSERT INTO T_DEADLOCK_PRIMARY_LHR VALUES(1); 1 row created. SYS@lhrdb S1> |
会话2,sid为156:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | SYS@lhrdb> set sqlprompt "_user'@'_connect_identifier S2> " SYS@lhrdb S2> select userenv('sid') from dual; USERENV('SID') -------------- 191 SYS@lhrdb S2> INSERT INTO T_DEADLOCK_PRIMARY_LHR VALUES(2); 1 row created. SYS@lhrdb S2> INSERT INTO T_DEADLOCK_PRIMARY_LHR VALUES(1); ====>>>>> 产生了阻塞 |

1 2 3 4 5 6 7 8 9 | SELECT NVL(A.SQL_ID, A.PREV_SQL_ID) SQL_ID, A.BLOCKING_SESSION, A.SID, A.SERIAL#, A.LOGON_TIME, A.EVENT FROM GV$SESSION A WHERE A.SID IN (156,191) ORDER BY A.LOGON_TIME; |

156阻塞了191会话,即会话1阻塞了会话2。
会话1再次插入数据:
1 2 3 | SYS@lhrdb S1> INSERT INTO T_DEADLOCK_PRIMARY_LHR VALUES(2); ====>>>>> 产生了阻塞 |
此时,去会话2看的时候,已经报出了死锁的错误:

此时的阻塞已经发生了变化:

告警日志:
1 2 | Fri Sep 23 09:03:11 2016 ORA-00060: Deadlock detected. More info in file /oracle/app/oracle/diag/rdbms/lhrdb/lhrdb/trace/lhrdb_ora_25886852.trc. |
其内容可以看到很经典的一段:
1 2 3 4 5 6 7 8 9 10 11 12 | Deadlock graph: ---------Blocker(s)-------- ---------Waiter(s)--------- Resource Name process session holds waits process session holds waits TX-0008000c-000008dc 38 191 X 29 156 S TX-00030016-00000892 29 156 X 38 191 S session 191: DID 0001-0026-00000115 session 156: DID 0001-001D-0000000D session 156: DID 0001-001D-0000000D session 191: DID 0001-0026-00000115 Rows waited on: Session 191: no row Session 156: no row |

这就是主键的死锁,模拟完毕。
此时,若是会话2执行提交后,会话1就会报错,违反唯一约束:
1 2 3 4 5 6 | SYS@lhrdb S1> INSERT INTO T_DEADLOCK_PRIMARY_LHR VALUES(2); INSERT INTO T_DEADLOCK_PRIMARY_LHR VALUES(2) * ERROR at line 1: ORA-00001: unique constraint (SYS.SYS_C0011517) violated |
脚本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | 会话1: DROP TABLE T_DEADLOCK_PRIMARY_LHR; CREATE TABLE T_DEADLOCK_PRIMARY_LHR(ID NUMBER PRIMARY KEY); --CREATE UNIQUE INDEX IDX_TEST_LHR ON T_DEADLOCK_PRIMARY_LHR(ID); select userenv('sid') from dual; INSERT INTO T_DEADLOCK_PRIMARY_LHR VALUES(1); 会话2: select userenv('sid') from dual; INSERT INTO T_DEADLOCK_PRIMARY_LHR VALUES(2); INSERT INTO T_DEADLOCK_PRIMARY_LHR VALUES(1); 会话1:---死锁产生 INSERT INTO T_DEADLOCK_PRIMARY_LHR VALUES(2); SELECT NVL(A.SQL_ID, A.PREV_SQL_ID) SQL_ID, A.BLOCKING_SESSION, A.SID, A.SERIAL#, A.LOGON_TIME, A.EVENT FROM GV$SESSION A WHERE A.SID IN (156,191) ORDER BY A.LOGON_TIME; |
外键的死锁(外键未加索引)
外键未加索引很容易导致死锁。在以下两种情况下,Oracle在修改父表后会对子表加一个全表锁:
1. 如果更新了父表的主键,由于外键上没有索引,所以子表会被锁住。
2. 如果删除了父表中的一行,由于外键上没有索引,整个子表也会被锁住。
总之,就是更新或者删除父表的主键,都会导致对其子表加一个全表锁。
如果父表存在删除记录或者更改外键列的情形,那么就需要在子表上为外键列创建索引。
除了全表锁外,在以下情况下,未加索引的外键也可能带来问题:
1. 如果有ON DELETE CASCADE,而且没有对子表加索引:例如,EMP是DEPT的子表,DELETE DEPTNO = 10应该CASCADE(级联)至EMP[4]。如果EMP中的DEPTNO没有索引,那么删除DEPT表中的每一行时都会对EMP做一个全表扫描。这个全表扫描可能是不必要的,而且如果从父表删除多行,父表中每删除一行就要扫描一次子表。
2. 从父表查询子表:再次考虑EMP/DEPT例子。利用DEPTNO查询EMP表是相当常见的。如果频繁地运行以下查询(例如,生成一个报告),你会发现没有索引会使查询速度变慢:
SELECT * FROM DEPT, EMP
WHERE EMP.DEPTNO = DEPT.DEPTNO
AND DEPT.DEPTNO = :X;
那么,什么时候不需要对外键加索引呢?答案是,一般来说,当满足以下条件时不需要加索引:
1. 没有从父表删除行。
2. 没有更新父表的惟一键/主键值。
3. 没有从父表联结子表。
如果满足上述全部3个条件,那你完全可以跳过索引,不需要对外键加索引。不过个人还是强烈建议对子表添加索引,既然已经创建了外键,就不在乎再多一个索引吧,因为一个索引所增加的代价比如死锁,与缺失这个索引所带来的问题相比,是微不足道的。
子表上为外键列建立索引,可以:
1)提高针对外键列的查询或改动性能
2)减小表级锁粒度,降低死锁发生的可能性
外键的死锁可以这样通俗的理解:有两个表A和B:A是父表,B是子表。如果没有在B表中的外键加上索引,那么A表在更新或者删除主键时,都会在表B上加一个全表锁。这是为什么呢?因为我们没有给外键加索引,在更新或者删除A表主键的时候,需要查看子表B中是否有对应的记录,以判断是否可以更新删除。那如何查找呢?当然只能在子表B中一条一条找了,因为我们没有加索引吗。既然要在子表B中一条一条地找,那就得把整个子表B都锁定了。由此就会导致以上一系列问题。
实验过程:
会话1首先建立子表和父表
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | SYS@lhrdb S1> CREATE TABLE T_DEADLOCK_P_LHR (ID NUMBER PRIMARY KEY, NAME VARCHAR2(30)); --父表的主键 Table created. SYS@lhrdb S1> INSERT INTO T_DEADLOCK_P_LHR VALUES (1, 'A'); 1 row created. SYS@lhrdb S1> INSERT INTO T_DEADLOCK_P_LHR VALUES (2, 'B'); 1 row created. SYS@lhrdb S1> CREATE TABLE T_DEADLOCK_F_LHR (FID NUMBER, FNAME VARCHAR2(30), FOREIGN KEY (FID) REFERENCES T_DEADLOCK_P_LHR); --子表的外键 Table created. SYS@lhrdb S1> INSERT INTO T_DEADLOCK_F_LHR VALUES (1, 'C'); 1 row created. SYS@lhrdb S1> INSERT INTO T_DEADLOCK_F_LHR VALUES (2, 'D'); 1 row created. SYS@lhrdb S1> SYS@lhrdb S1> COMMIT; Commit complete. |
会话1执行一个删除操作,这时候在子表和父表上都加了一个Row-X(SX)锁
1 2 3 4 5 6 7 | SYS@lhrdb S1> delete from T_DEADLOCK_F_LHR where FID=1; 1 row deleted. SYS@lhrdb S1> delete from T_DEADLOCK_P_LHR where id=1; 1 row deleted. |
查询会话1的锁信息:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 | SELECT LK.SID, DECODE(LK.TYPE, 'TX', 'Transaction', 'TM', 'DML', 'UL', 'PL/SQL User Lock', LK.TYPE) LOCK_TYPE, DECODE(LK.LMODE, 0, 'None', 1, 'Null', 2, 'Row-S (SS)', 3, 'Row-X (SX)', 4, 'Share', 5, 'S/Row-X (SSX)', 6, 'Exclusive', TO_CHAR(LK.LMODE)) MODE_HELD, DECODE(LK.REQUEST, 0, 'None', 1, 'Null', 2, 'Row-S (SS)', 3, 'Row-X (SX)', 4, 'Share', 5, 'S/Row-X (SSX)', 6, 'Exclusive', TO_CHAR(LK.REQUEST)) MODE_REQUESTED, OB.OBJECT_TYPE, OB.OBJECT_NAME, LK.BLOCK, SE.LOCKWAIT FROM V$LOCK LK, DBA_OBJECTS OB, V$SESSION SE WHERE LK.TYPE IN ('TM', 'UL') AND LK.SID = SE.SID AND LK.ID1 = OB.OBJECT_ID(+) AND SE.SID IN (156,191) ORDER BY SID; |

BLOCK为0表示没有阻塞其它的锁。
会话2:执行另一个删除操作,发现这时候第二个删除语句等待
1 2 3 4 5 6 7 | SYS@lhrdb S2> delete from T_DEADLOCK_F_LHR where FID=2; 1 row deleted. SYS@lhrdb S2> delete from T_DEADLOCK_P_LHR where id=2; ====>>>>> 产生了阻塞 |


BLOCK为1表示阻塞了其它的锁。
会话1执行删除语句,死锁发生
1 2 3 | SYS@lhrdb S1> delete from T_DEADLOCK_P_LHR where id=1; ====>>>>> 产生了阻塞,而会话2产生了死锁 |

1 2 3 4 5 6 7 | SYS@lhrdb S2> delete from T_DEADLOCK_P_LHR where id=2; delete from T_DEADLOCK_P_LHR where id=2 * ERROR at line 1: ORA-00060: deadlock detected while waiting for resource |

告警日志:
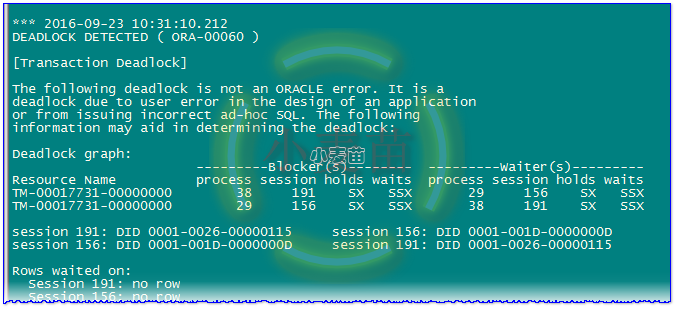
1 2 | Fri Sep 23 10:31:10 2016 ORA-00060: Deadlock detected. More info in file /oracle/app/oracle/diag/rdbms/lhrdb/lhrdb/trace/lhrdb_ora_25886852.trc. |
查看内容:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | *** 2016-09-23 10:31:10.212 DEADLOCK DETECTED ( ORA-00060 ) [Transaction Deadlock] The following deadlock is not an ORACLE error. It is a deadlock due to user error in the design of an application or from issuing incorrect ad-hoc SQL. The following information may aid in determining the deadlock: Deadlock graph: ---------Blocker(s)-------- ---------Waiter(s)--------- Resource Name process session holds waits process session holds waits TM-00017731-00000000 38 191 SX SSX 29 156 SX SSX TM-00017731-00000000 29 156 SX SSX 38 191 SX SSX session 191: DID 0001-0026-00000115 session 156: DID 0001-001D-0000000D session 156: DID 0001-001D-0000000D session 191: DID 0001-0026-00000115 Rows waited on: Session 191: no row Session 156: no row |
回滚会话建立外键列上的索引:
1 2 3 4 5 6 7 | SYS@lhrdb S1> rollback; Rollback complete. SYS@lhrdb S1> create index ind_p_f_fid on T_DEADLOCK_F_LHR(fid); Index created. |
重复上面的步骤会话1删除子表记录:
---会话1:
1 2 3 4 5 6 7 8 9 10 | SYS@lhrdb S1> delete from T_DEADLOCK_F_LHR where FID=1; 1 row deleted. SYS@lhrdb S1> delete from T_DEADLOCK_P_LHR where id=1; 1 row deleted. SYS@lhrdb S1> |
---会话2:
1 2 3 4 5 6 7 | SYS@lhrdb S2> delete from T_DEADLOCK_F_LHR where FID=2; 1 row deleted. SYS@lhrdb S2> delete from T_DEADLOCK_P_LHR where id=2; 1 row deleted. |
所有的删除操作都可以成功执行,也没有阻塞的生成,重点就是在外键列上建立索引。


脚本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | --主表 DROP TABLE T_DEADLOCK_P_LHR; CREATE TABLE T_DEADLOCK_P_LHR (ID NUMBER PRIMARY KEY, NAME VARCHAR2(30)); --父表的主键 INSERT INTO T_DEADLOCK_P_LHR VALUES (1, 'A'); INSERT INTO T_DEADLOCK_P_LHR VALUES (2, 'B'); --子表 DROP TABLE T_DEADLOCK_F_LHR; CREATE TABLE T_DEADLOCK_F_LHR (FID NUMBER, FNAME VARCHAR2(30), FOREIGN KEY (FID) REFERENCES T_DEADLOCK_P_LHR); --子表的外键 INSERT INTO T_DEADLOCK_F_LHR VALUES (1, 'C'); INSERT INTO T_DEADLOCK_F_LHR VALUES (2, 'D'); COMMIT; ---执行一个删除操作,这时候在子表和父表上都加了一个Row-S(SX)锁 delete from T_DEADLOCK_F_LHR where FID=1; delete from T_DEADLOCK_P_LHR where id=1; ---会话2:执行另一个删除操作,发现这时候第二个删除语句等待 delete from T_DEADLOCK_F_LHR where FID=2; delete from T_DEADLOCK_P_LHR where id=2; ---会话1:死锁发生 delete from T_DEADLOCK_P_LHR where id=1; ---回滚会话建立外键列上的索引: create index ind_p_f_fid on T_DEADLOCK_F_LHR(fid); --重复上面的步骤会话1删除子表记录: ---会话1: delete from T_DEADLOCK_F_LHR where FID=1; delete from T_DEADLOCK_P_LHR where id=1; ---会话2:执行另一个删除操作,发现这时候第二个删除语句等待 delete from T_DEADLOCK_F_LHR where FID=2; delete from T_DEADLOCK_P_LHR where id=2; |
位图(BITMAP)索引死锁
表上的位图索引遭到并发更新也很容易产生死锁。在有位图索引存在的表上面,其实很容易就引发阻塞与死锁。这个阻塞不是发生在表上面,而是发生在索引上。因为位图索引锁定的范围远远比普通的b-tree索引锁定的范围大。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | SYS@lhrdb S1> CREATE TABLE T_DEADLOCK_BITMAP_LHR (ID NUMBER , NAME VARCHAR2(10)); Table created. SYS@lhrdb S1> INSERT INTO T_DEADLOCK_BITMAP_LHR VALUES (1,'A'); 1 row created. SYS@lhrdb S1> INSERT INTO T_DEADLOCK_BITMAP_LHR VALUES (1,'B'); 1 row created. SYS@lhrdb S1> INSERT INTO T_DEADLOCK_BITMAP_LHR VALUES (1,'C'); 1 row created. SYS@lhrdb S1> INSERT INTO T_DEADLOCK_BITMAP_LHR VALUES (2,'A'); 1 row created. SYS@lhrdb S1> INSERT INTO T_DEADLOCK_BITMAP_LHR VALUES (2,'B'); 1 row created. SYS@lhrdb S1> INSERT INTO T_DEADLOCK_BITMAP_LHR VALUES (2,'C'); 1 row created. SYS@lhrdb S1> COMMIT; Commit complete. |
--那么在ID列上建bitmap index的话,所有ID=1的会放到一个位图中,所有ID=2的是另外一个位图,而在执行DML操作的时候,锁定的将是整个位图中的所有行,而不仅仅是DML涉及到的行。由于锁定的粒度变粗,bitmap index更容易导致死锁的发生。
会话1:此时所有ID=1的行都被锁定
1 2 3 4 5 6 7 8 | SYS@lhrdb S1> CREATE BITMAP INDEX IDX_DEADLOCK_BITMAP_LHR ON T_DEADLOCK_BITMAP_LHR(ID); Index created. SYS@lhrdb S1> UPDATE T_DEADLOCK_BITMAP_LHR SET ID=3 WHERE ID=1 AND NAME='A'; 1 row updated. |
会话2:此时所有ID=2的行都被锁定
1 2 3 4 | SYS@lhrdb S2> UPDATE T_DEADLOCK_BITMAP_LHR SET ID=4 WHERE ID=2 AND NAME='A'; 1 row updated. |
会话1:此时会话被阻塞
1 2 3 | SYS@lhrdb S1> UPDATE T_DEADLOCK_BITMAP_LHR SET ID=4 WHERE ID=2 AND NAME='B'; ====>>>>> 产生了阻塞 |

会话2:会话被阻塞
1 2 3 | SYS@lhrdb S2> UPDATE T_DEADLOCK_BITMAP_LHR SET ID=3 WHERE ID=1 AND NAME='B'; ====>>>>> 产生了阻塞 |
再回到SESSION 1,发现系统检测到了死锁的发生
1 2 3 4 5 6 | SYS@lhrdb S1> UPDATE T_DEADLOCK_BITMAP_LHR SET ID=4 WHERE ID=2 AND NAME='B'; UPDATE T_DEADLOCK_BITMAP_LHR SET ID=4 WHERE ID=2 AND NAME='B' * ERROR at line 1: ORA-00060: deadlock detected while waiting for resource |
告警日志:
1 2 | Fri Sep 23 11:20:21 2016 ORA-00060: Deadlock detected. More info in file /oracle/app/oracle/diag/rdbms/lhrdb/lhrdb/trace/lhrdb_ora_19726460.trc. |
内容:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | *** 2016-09-23 11:26:51.264 DEADLOCK DETECTED ( ORA-00060 ) [Transaction Deadlock] The following deadlock is not an ORACLE error. It is a deadlock due to user error in the design of an application or from issuing incorrect ad-hoc SQL. The following information may aid in determining the deadlock: Deadlock graph: ---------Blocker(s)-------- ---------Waiter(s)--------- Resource Name process session holds waits process session holds waits TX-0009000e-00000b0f 29 156 X 38 191 S TX-00070001-00000b2c 38 191 X 29 156 S session 156: DID 0001-001D-0000000D session 191: DID 0001-0026-00000115 session 191: DID 0001-0026-00000115 session 156: DID 0001-001D-0000000D Rows waited on: Session 156: obj - rowid = 00017734 - AAAXc0AAAAAAAAAAAA (dictionary objn - 96052, file - 0, block - 0, slot - 0) Session 191: obj - rowid = 00017734 - AAAXc0AAAAAAAAAAAA (dictionary objn - 96052, file - 0, block - 0, slot - 0) |

死锁发生的根本原因是对于资源的排他锁定顺序不一致。上面的试验中,session1对于bitmap index中的2个位图是先锁定ID=1的位图,然后请求ID=2的位图,而在此之前ID=2的位图已经被session2锁定。session2则先锁定ID=2的位图,然后请求ID=2的位图,而此前ID=1的位图已经被session1锁定。于是,session1等待session2释放ID=2的位图上的锁,session2等待session1释放ID=1的位图上的锁,死锁就发生了
而如果我们创建的是普通的B*Tree index,重复上面的试验则不会出现任何的阻塞和死锁,这是因为锁定的只是DML操作涉及到的行,而不是所有ID相同的行。
脚本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | CREATE TABLE T_DEADLOCK_BITMAP_LHR (ID NUMBER , NAME VARCHAR2(10)); INSERT INTO T_DEADLOCK_BITMAP_LHR VALUES (1,'A'); INSERT INTO T_DEADLOCK_BITMAP_LHR VALUES (1,'B'); INSERT INTO T_DEADLOCK_BITMAP_LHR VALUES (1,'C'); INSERT INTO T_DEADLOCK_BITMAP_LHR VALUES (2,'A'); INSERT INTO T_DEADLOCK_BITMAP_LHR VALUES (2,'B'); INSERT INTO T_DEADLOCK_BITMAP_LHR VALUES (2,'C'); COMMIT; CREATE BITMAP INDEX IDX_DEADLOCK_BITMAP_LHR ON T_DEADLOCK_BITMAP_LHR(ID); --会话1:此时所有ID=1的行都被锁定 UPDATE T_DEADLOCK_BITMAP_LHR SET ID=3 WHERE ID=1 AND NAME='A'; --会话2:此时所有ID=2的行都被锁定 UPDATE T_DEADLOCK_BITMAP_LHR SET ID=4 WHERE ID=2 AND NAME='A'; --会话1:此时会话被阻塞 UPDATE T_DEADLOCK_BITMAP_LHR SET ID=4 WHERE ID=2 AND NAME='B'; --会话2:会话被阻塞,再回到SESSION 1,发现系统检测到了死锁的发生 UPDATE T_DEADLOCK_BITMAP_LHR SET ID=3 WHERE ID=1 AND NAME='B'; --会话1: UPDATE T_DEADLOCK_BITMAP_LHR SET ID=4 WHERE ID=2 AND NAME='B'; UPDATE T_DEADLOCK_BITMAP_LHR SET ID=4 WHERE ID=2 AND NAME='B' * ERROR at line 1: ORA-00060: deadlock detected while waiting for resource |
常见事务引发的死锁
如果你有两个会话,每个会话都持有另一个会话想要的资源,此时就会出现死锁(deadlock)。例如,如果我的数据库中有两个表A和B,每个表中都只有一行,就可以很容易地展示什么是死锁。我要做的只是打开两个会话(例如,两个SQL*Plus会话)。在会话A中更新表A,并在会话B中更新表B。现在,如果我想在会话B中更新表A,就会阻塞。会话A已经锁定了这一行。这不是死锁;只是阻塞而已。因为会话A还有机会提交或回滚,这样会话B就能继续。如果我再回到会话A,试图更新表B,这就会导致一个死锁。要在这两个会话中选择一个作为“牺牲品”,让它的语句回滚。
想要更新表B的会话A还阻塞着,Oracle不会回滚整个事务。只会回滚与死锁有关的某条语句。会话B仍然锁定着表B中的行,而会话A还在耐心地等待这一行可用。收到死锁消息后,会话B必须决定将表B上未执行的工作提交还是回滚,或者继续走另一条路,以后再提交。一旦这个会话执行提交或回滚,另一个阻塞的会话就会继续,好像什么也没有发生过一样。
模拟一:两个表之间不同顺序相互更新操作引起的死锁
创建两个简单的表A和B,每个表中仅仅包含一个字段id。
12345678910111213141516171819202122232425262728293031323334353637[ZFZHLHRDB2:oracle]:/oracle>sqlplus / as sysdbaSQL*Plus: Release 11.2.0.4.0 Production on Mon Jun 20 09:40:24 2016Copyright (c) 1982, 2013, Oracle. All rights reserved.Connected to:Oracle Database 11g Enterprise Edition Release 11.2.0.4.0 - 64bit ProductionWith the Partitioning, Real Application Clusters, Automatic Storage Management, OLAP,Data Mining and Real Application Testing optionsSYS@raclhr2> select * from v$version;BANNER--------------------------------------------------------------------------------Oracle Database 11g Enterprise Edition Release 11.2.0.4.0 - 64bit ProductionPL/SQL Release 11.2.0.4.0 - ProductionCORE 11.2.0.4.0 ProductionTNS for IBM/AIX RISC System/6000: Version 11.2.0.4.0 - ProductionNLSRTL Version 11.2.0.4.0 - ProductionSYS@raclhr2> show parameter clusterNAME TYPE VALUE------------------------------------ ----------- ------------------------------cluster_database boolean TRUEcluster_database_instances integer 2cluster_interconnects stringSYS@raclhr2> create table A (id int);Table created.SYS@raclhr2> create table B (id int);Table created.
2、每张表中仅初始化一条数据
1 2 3 4 5 6 7 8 9 10 11 | SYS@raclhr2> insert into A values (1); 1 row created. SYS@raclhr2> insert into B values (2); 1 row created. SYS@raclhr2> commit; Commit complete. |
3、在第一个会话session1中更新表A中的记录“1”为“10000”,不提交;在第二个会话session2中更新表B中的记录“2”为“20000”,不提交