合 阿里开源ETL工具之DataX和DataX Web介绍
- 一. DataX 3.0概览
- 设计理念
- 当前使用现状
- DataX 商业版本
- 二、DataX3.0框架设计
- 三. DataX3.0插件体系
- 四、DataX3.0核心架构
- 核心模块介绍:
- DataX调度流程:
- 五、DataX 3.0六大核心优势
- 可靠的数据质量监控
- 丰富的数据转换功能
- 精准的速度控制
- 强劲的同步性能
- 健壮的容错机制
- 极简的使用体验
- 阿里云DataWorks数据集成
- System Requirements
- Quick Start
- DataX帮助
- 结构图
- 特性
- 功能介绍
- 1.执行器配置(使用开源项目xxl-job)
- 执行器属性说明
- 2.创建数据源
- 3.创建任务模版
- 4. 构建JSON脚本
- 5.批量创建任务
- 6.任务创建介绍(关联模版创建任务不再介绍,具体参考4. 构建JSON脚本)
- 支持DataX任务,Shell任务,Python任务,PowerShell任务
- 7. 任务列表
- 8. 可以点击查看日志,实时获取日志信息,终止正在执行的datax进程
- 9.任务资源监控
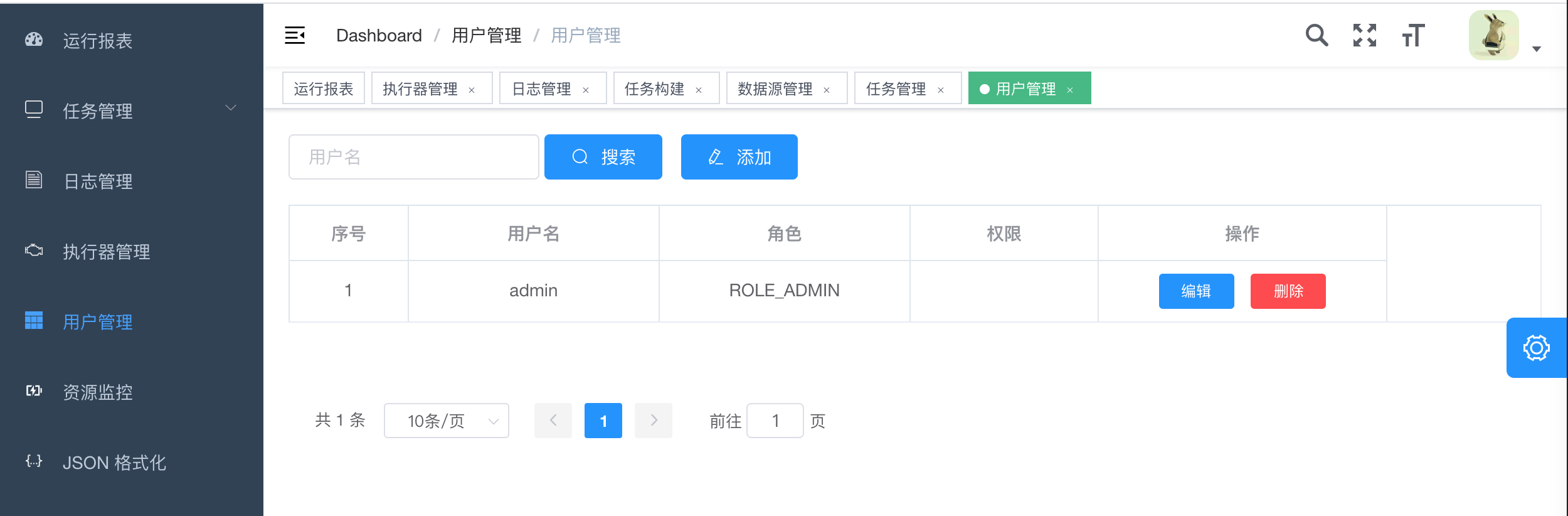
- 10. admin可以创建用户,编辑用户信息
- UI
- 安装配置
- 系统要求
- 基础软件安装
- 环境准备
- 1)基础软件安装
- DataX Web安装包准备
- 1)下载官方提供的版本tar版本包
- 2) 编译打包(官方提供的tar包跳过)
- Linux环境开始部署
- 1)解压安装包
- 2)执行一键安装脚本
- 3)数据库初始化
- 4) 配置
- 5)启动服务
- - 一键启动所有服务
- - 一键取消所有服务
- 6)查看服务(注意!注意!)
- 7)运行
- 8) 运行日志
- 9)集群部署
- 开发环境部署
- 1 创建数据库
- 执行bin/db下面的datax_web.sql文件(注意老版本更新语句有指定库名)
- 2 修改项目配置
- 修改datax_admin下resources/application.yml文件
- 2.修改datax_executor下resources/application.yml文件
- datax-web 注意事项
- 使用
- 1 项目管理
- 2 执行器管理
- 3 数据源管理
- 3.1 数据源说明
- 3.2 数据源添加
- 4 任务管理-DataX任务模板
- 5 任务管理-任务构建
- 5.1 步骤1 构建reader
- 5.2 步骤2 构建writer
- 5.3 步骤3 字段映射
- 5.4 步骤4 构建
- 5.5 提示构建成功后转向“任务管理”模块
- 6 任务管理-任务管理
- 7 任务管理-批量构建
![]()
阿里云开源离线同步工具DataX3.0介绍
GitHub:
https://github.com/alibaba/DataX
https://github.com/alibaba/DataX/blob/master/introduction.md
https://github.com/alibaba/DataX/blob/master/userGuid.md
一. DataX 3.0概览
DataX 是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle、SqlServer、PostgreSQL等)、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、Hologres、DRDS 等各种异构数据源之间稳定高效的数据同步功能。DataX 是阿里云 DataWorks数据集成 的开源版本,在阿里巴巴集团内被广泛使用的离线数据同步工具/平台。
DataX本身作为数据同步框架,将不同数据源的同步抽象为从源头数据源读取数据的Reader插件,以及向目标端写入数据的Writer插件,理论上DataX框架可以支持任意数据源类型的数据同步工作。同时DataX插件体系作为一套生态系统, 每接入一套新数据源该新加入的数据源即可实现和现有的数据源互通。
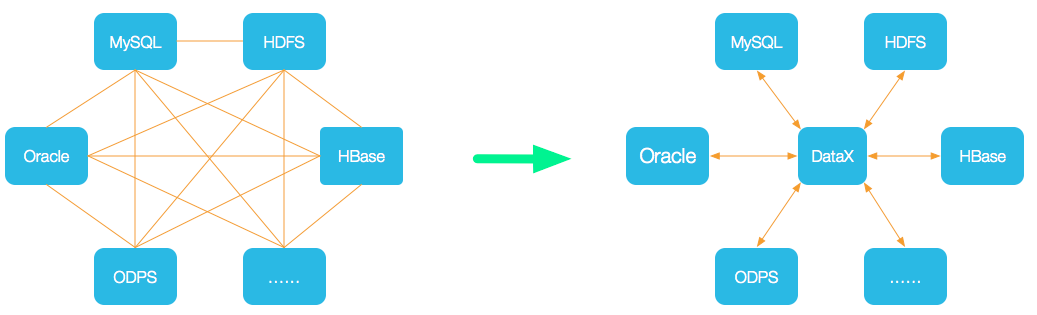
设计理念
为了解决异构数据源同步问题,DataX将复杂的网状的同步链路变成了星型数据链路,DataX作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,便能跟已有的数据源做到无缝数据同步。
当前使用现状
DataX在阿里巴巴集团内被广泛使用,承担了所有大数据的离线同步业务,并已持续稳定运行了6年之久。目前每天完成同步8w多道作业,每日传输数据量超过300TB。
此前已经开源DataX1.0版本,此次介绍为阿里云开源全新版本DataX3.0,有了更多更强大的功能和更好的使用体验。Github主页地址:https://github.com/alibaba/DataX
DataX 商业版本
阿里云DataWorks数据集成是DataX团队在阿里云上的商业化产品,致力于提供复杂网络环境下、丰富的异构数据源之间高速稳定的数据移动能力,以及繁杂业务背景下的数据同步解决方案。目前已经支持云上近3000家客户,单日同步数据超过3万亿条。DataWorks数据集成目前支持离线50+种数据源,可以进行整库迁移、批量上云、增量同步、分库分表等各类同步解决方案。2020年更新实时同步能力,2020年更新实时同步能力,支持10+种数据源的读写任意组合。提供MySQL,Oracle等多种数据源到阿里云MaxCompute,Hologres等大数据引擎的一键全增量同步解决方案。
商业版本参见: https://www.aliyun.com/product/bigdata/ide
二、DataX3.0框架设计

DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。
- Reader:Reader为数据采集模块,负责采集数据源的数据,将数据发送给Framework。
- Writer: Writer为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
- Framework:Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
三. DataX3.0插件体系
经过几年积累,DataX目前已经有了比较全面的插件体系,主流的RDBMS数据库、NOSQL、大数据计算系统都已经接入。DataX目前支持数据如下:
| 类型 | 数据源 | Reader(读) | Writer(写) | 文档 |
|---|---|---|---|---|
| RDBMS 关系型数据库 | MySQL | √ | √ | 读 、写 |
| Oracle | √ | √ | 读 、写 | |
| SQLServer | √ | √ | 读 、写 | |
| PostgreSQL | √ | √ | 读 、写 | |
| DRDS | √ | √ | 读 、写 | |
| 达梦 | √ | √ | [读]() 、[写]() | |
| 通用RDBMS(支持所有关系型数据库) | √ | √ | [读]() 、[写]() | |
| 阿里云数仓数据存储 | ODPS | √ | √ | 读 、写 |
| ADS | √ | 写 | ||
| OSS | √ | √ | 读 、写 | |
| OCS | √ | √ | 读 、写 | |
| NoSQL数据存储 | OTS | √ | √ | 读 、写 |
| Hbase0.94 | √ | √ | 读 、写 | |
| Hbase1.1 | √ | √ | 读 、写 | |
| MongoDB | √ | √ | 读 、写 | |
| Hive | √ | √ | 读 、写 | |
| 无结构化数据存储 | TxtFile | √ | √ | 读 、写 |
| FTP | √ | √ | 读 、写 | |
| HDFS | √ | √ | 读 、写 | |
| Elasticsearch | √ | 写 |
DataX Framework提供了简单的接口与插件交互,提供简单的插件接入机制,只需要任意加上一种插件,就能无缝对接其他数据源。详情请看:DataX数据源指南
四、DataX3.0核心架构
DataX 3.0 开源版本支持单机多线程模式完成同步作业运行,本小节按一个DataX作业生命周期的时序图,从整体架构设计非常简要说明DataX各个模块相互关系。

核心模块介绍:
- DataX完成单个数据同步的作业,我们称之为Job,DataX接受到一个Job之后,将启动一个进程来完成整个作业同步过程。DataX Job模块是单个作业的中枢管理节点,承担了数据清理、子任务切分(将单一作业计算转化为多个子Task)、TaskGroup管理等功能。
- DataXJob启动后,会根据不同的源端切分策略,将Job切分成多个小的Task(子任务),以便于并发执行。Task便是DataX作业的最小单元,每一个Task都会负责一部分数据的同步工作。
- 切分多个Task之后,DataX Job会调用Scheduler模块,根据配置的并发数据量,将拆分成的Task重新组合,组装成TaskGroup(任务组)。每一个TaskGroup负责以一定的并发运行完毕分配好的所有Task,默认单个任务组的并发数量为5。
- 每一个Task都由TaskGroup负责启动,Task启动后,会固定启动Reader—>Channel—>Writer的线程来完成任务同步工作。
- DataX作业运行起来之后, Job监控并等待多个TaskGroup模块任务完成,等待所有TaskGroup任务完成后Job成功退出。否则,异常退出,进程退出值非0
DataX调度流程:
举例来说,用户提交了一个DataX作业,并且配置了20个并发,目的是将一个100张分表的mysql数据同步到odps里面。 DataX的调度决策思路是:
- DataXJob根据分库分表切分成了100个Task。
- 根据20个并发,DataX计算共需要分配4个TaskGroup。
- 4个TaskGroup平分切分好的100个Task,每一个TaskGroup负责以5个并发共计运行25个Task。
五、DataX 3.0六大核心优势
可靠的数据质量监控
完美解决数据传输个别类型失真问题
DataX旧版对于部分数据类型(比如时间戳)传输一直存在毫秒阶段等数据失真情况,新版本DataX3.0已经做到支持所有的强数据类型,每一种插件都有自己的数据类型转换策略,让数据可以完整无损的传输到目的端。
提供作业全链路的流量、数据量运行时监控
DataX3.0运行过程中可以将作业本身状态、数据流量、数据速度、执行进度等信息进行全面的展示,让用户可以实时了解作业状态。并可在作业执行过程中智能判断源端和目的端的速度对比情况,给予用户更多性能排查信息。
提供脏数据探测
在大量数据的传输过程中,必定会由于各种原因导致很多数据传输报错(比如类型转换错误),这种数据DataX认为就是脏数据。DataX目前可以实现脏数据精确过滤、识别、采集、展示,为用户提供多种的脏数据处理模式,让用户准确把控数据质量大关!
丰富的数据转换功能
DataX作为一个服务于大数据的ETL工具,除了提供数据快照搬迁功能之外,还提供了丰富数据转换的功能,让数据在传输过程中可以轻松完成数据脱敏,补全,过滤等数据转换功能,另外还提供了自动groovy函数,让用户自定义转换函数。详情请看DataX3的transformer详细介绍。
精准的速度控制
还在为同步过程对在线存储压力影响而担心吗?新版本DataX3.0提供了包括通道(并发)、记录流、字节流三种流控模式,可以随意控制你的作业速度,让你的作业在库可以承受的范围内达到最佳的同步速度。
12345"speed": {"channel": 5,"byte": 1048576,"record": 10000}强劲的同步性能
DataX3.0每一种读插件都有一种或多种切分策略,都能将作业合理切分成多个Task并行执行,单机多线程执行模型可以让DataX速度随并发成线性增长。在源端和目的端性能都足够的情况下,单个作业一定可以打满网卡。另外,DataX团队对所有的已经接入的插件都做了极致的性能优化,并且做了完整的性能测试。性能测试相关详情可以参照每单个数据源的详细介绍:DataX数据源指南
健壮的容错机制
DataX作业是极易受外部因素的干扰,网络闪断、数据源不稳定等因素很容易让同步到一半的作业报错停止。因此稳定性是DataX的基本要求,在DataX 3.0的设计中,重点完善了框架和插件的稳定性。目前DataX3.0可以做到线程级别、进程级别(暂时未开放)、作业级别多层次局部/全局的重试,保证用户的作业稳定运行。
线程内部重试
DataX的核心插件都经过团队的全盘review,不同的网络交互方式都有不同的重试策略。
线程级别重试
目前DataX已经可以实现TaskFailover,针对于中间失败的Task,DataX框架可以做到整个Task级别的重新调度。
极简的使用体验
易用
下载即可用,支持linux和windows,只需要短短几步骤就可以完成数据的传输。请点击:Quick Start
详细
DataX在运行日志中打印了大量信息,其中包括传输速度,Reader、Writer性能,进程CPU,JVM和GC情况等等。
传输过程中打印传输速度、进度等

传输过程中会打印进程相关的CPU、JVM等
在任务结束之后,打印总体运行情况


阿里云DataWorks数据集成
目前DataX的已有能力已经全部融和进阿里云的数据集成,并且比DataX更加高效、安全,同时数据集成具备DataX不具备的其它高级特性和功能。可以理解为数据集成是DataX的全面升级的商业化用版本,为企业可以提供稳定、可靠、安全的数据传输服务。与DataX相比,数据集成主要有以下几大突出特点:
支持实时同步:
支持数据处理:https://help.aliyun.com/document_detail/146777.html
离线同步数据源种类大幅度扩充:
新增比如:DB2、Kafka、Hologres、MetaQ、SAPHANA、达梦等等,持续扩充中
离线同步支持的数据源:https://help.aliyun.com/document_detail/137670.html
具备同步解决方案:
DataX安装下载
下载: DataX下载地址:http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
System Requirements
- Linux
- JDK(1.8以上,推荐1.8)
- Python(推荐Python2.6.X)
- Apache Maven 3.x (Compile DataX)
Quick Start
工具部署
- 方法一、直接下载DataX工具包:DataX下载地址
下载后解压至本地某个目录,进入bin目录,即可运行同步作业:
123tar -xvf datax.tar.gz$ cd {YOUR_DATAX_HOME}/bin$ python datax.py {YOUR_JOB.json}自检脚本:
1python {YOUR_DATAX_HOME}/bin/datax.py {YOUR_DATAX_HOME}/job/job.json- 方法二、下载DataX源码,自己编译:DataX源码
(1)、下载DataX源码:
1$ git clone git@github.com:alibaba/DataX.git(2)、通过maven打包:
12$ cd {DataX_source_code_home}$ mvn -U clean package assembly:assembly -Dmaven.test.skip=true打包成功,日志显示如下:
123456[INFO] BUILD SUCCESS[INFO] -----------------------------------------------------------------[INFO] Total time: 08:12 min[INFO] Finished at: 2015-12-13T16:26:48+08:00[INFO] Final Memory: 133M/960M[INFO] -----------------------------------------------------------------打包成功后的DataX包位于 {DataX_source_code_home}/target/datax/datax/ ,结构如下:
123$ cd {DataX_source_code_home}$ ls ./target/datax/datax/bin conf job lib log log_perf plugin script tmp配置示例:从stream读取数据并打印到控制台
- 第一步、创建作业的配置文件(json格式)
可以通过命令查看配置模板: python datax.py -r {YOUR_READER} -w {YOUR_WRITER}
1234567891011121314151617181920212223242526272829303132333435363738394041$ cd {YOUR_DATAX_HOME}/bin$ python datax.py -r streamreader -w streamwriterDataX (UNKNOWN_DATAX_VERSION), From Alibaba !Copyright (C) 2010-2015, Alibaba Group. All Rights Reserved.Please refer to the streamreader document:https://github.com/alibaba/DataX/blob/master/streamreader/doc/streamreader.mdPlease refer to the streamwriter document:https://github.com/alibaba/DataX/blob/master/streamwriter/doc/streamwriter.mdPlease save the following configuration as a json file and usepython {DATAX_HOME}/bin/datax.py {JSON_FILE_NAME}.jsonto run the job.{"job": {"content": [{"reader": {"name": "streamreader","parameter": {"column": [],"sliceRecordCount": ""}},"writer": {"name": "streamwriter","parameter": {"encoding": "","print": true}}}],"setting": {"speed": {"channel": ""}}}}根据模板配置json如下:
12345678910111213141516171819202122232425262728293031323334353637#stream2stream.json{"job": {"content": [{"reader": {"name": "streamreader","parameter": {"sliceRecordCount": 10,"column": [{"type": "long","value": "10"},{"type": "string","value": "hello,你好,世界-DataX"}]}},"writer": {"name": "streamwriter","parameter": {"encoding": "UTF-8","print": true}}}],"setting": {"speed": {"channel": 5}}}}- 第二步:启动DataX
12$ cd {YOUR_DATAX_DIR_BIN}$ python datax.py ./stream2stream.json同步结束,显示日志如下:
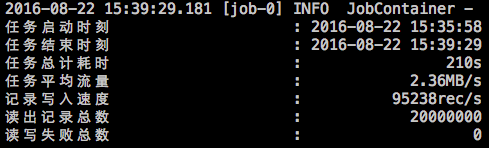
123456789...2015-12-17 11:20:25.263 [job-0] INFO JobContainer -任务启动时刻 : 2015-12-17 11:20:15任务结束时刻 : 2015-12-17 11:20:25任务总计耗时 : 10s任务平均流量 : 205B/s记录写入速度 : 5rec/s读出记录总数 : 50读写失败总数 : 0
DataX帮助
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 | [root@docker35 bin]# python datax.py DataX (DATAX-OPENSOURCE-3.0), From Alibaba ! Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved. Usage: datax.py [options] job-url-or-path Options: -h, --help show this help message and exit Product Env Options: Normal user use these options to set jvm parameters, job runtime mode etc. Make sure these options can be used in Product Env. -j <jvm parameters>, --jvm=<jvm parameters> Set jvm parameters if necessary. --jobid=<job unique id> Set job unique id when running by Distribute/Local Mode. -m <job runtime mode>, --mode=<job runtime mode> Set job runtime mode such as: standalone, local, distribute. Default mode is standalone. -p <parameter used in job config>, --params=<parameter used in job config> Set job parameter, eg: the source tableName you want to set it by command, then you can use like this: -p"-DtableName=your-table-name", if you have mutiple parameters: -p"-DtableName=your-table-name -DcolumnName=your-column-name".Note: you should config in you job tableName with ${tableName}. -r <parameter used in view job config[reader] template>, --reader=<parameter used in view job config[reader] template> View job config[reader] template, eg: mysqlreader,streamreader -w <parameter used in view job config[writer] template>, --writer=<parameter used in view job config[writer] template> View job config[writer] template, eg: mysqlwriter,streamwriter Develop/Debug Options: Developer use these options to trace more details of DataX. -d, --debug Set to remote debug mode. --loglevel=<log level> Set log level such as: debug, info, all etc. [root@lhrdatax datax]# python ./bin/datax.py ./job/job.json DataX (DATAX-OPENSOURCE-3.0), From Alibaba ! Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved. 2021-10-09 16:07:14.109 [main] INFO VMInfo - VMInfo# operatingSystem class => sun.management.OperatingSystemImpl 2021-10-09 16:07:14.126 [main] INFO Engine - the machine info => osInfo: Red Hat, Inc. 1.8 25.282-b08 jvmInfo: Linux amd64 3.10.0-1127.10.1.el7.x86_64 cpu num: 8 totalPhysicalMemory: -0.00G freePhysicalMemory: -0.00G maxFileDescriptorCount: -1 currentOpenFileDescriptorCount: -1 GC Names [PS MarkSweep, PS Scavenge] MEMORY_NAME | allocation_size | init_size PS Eden Space | 256.00MB | 256.00MB Code Cache | 240.00MB | 2.44MB Compressed Class Space | 1,024.00MB | 0.00MB PS Survivor Space | 42.50MB | 42.50MB PS Old Gen | 683.00MB | 683.00MB Metaspace | -0.00MB | 0.00MB 2021-10-09 16:07:14.163 [main] INFO Engine - { "content":[ { "reader":{ "name":"streamreader", "parameter":{ "column":[ { "type":"string", "value":"DataX" }, { "type":"long", "value":19890604 }, { "type":"date", "value":"1989-06-04 00:00:00" }, { "type":"bool", "value":true }, { "type":"bytes", "value":"test" } ], "sliceRecordCount":100000 } }, "writer":{ "name":"streamwriter", "parameter":{ "encoding":"UTF-8", "print":false } } } ], "setting":{ "errorLimit":{ "percentage":0.02, "record":0 }, "speed":{ "byte":10485760 } } } 2021-10-09 16:07:14.204 [main] WARN Engine - prioriy set to 0, because NumberFormatException, the value is: null 2021-10-09 16:07:14.208 [main] INFO PerfTrace - PerfTrace traceId=job_-1, isEnable=false, priority=0 2021-10-09 16:07:14.208 [main] INFO JobContainer - DataX jobContainer starts job. 2021-10-09 16:07:14.213 [main] INFO JobContainer - Set jobId = 0 2021-10-09 16:07:14.248 [job-0] INFO JobContainer - jobContainer starts to do prepare ... 2021-10-09 16:07:14.249 [job-0] INFO JobContainer - DataX Reader.Job [streamreader] do prepare work . 2021-10-09 16:07:14.250 [job-0] INFO JobContainer - DataX Writer.Job [streamwriter] do prepare work . 2021-10-09 16:07:14.251 [job-0] INFO JobContainer - jobContainer starts to do split ... 2021-10-09 16:07:14.253 [job-0] INFO JobContainer - Job set Max-Byte-Speed to 10485760 bytes. 2021-10-09 16:07:14.255 [job-0] INFO JobContainer - DataX Reader.Job [streamreader] splits to [1] tasks. 2021-10-09 16:07:14.255 [job-0] INFO JobContainer - DataX Writer.Job [streamwriter] splits to [1] tasks. 2021-10-09 16:07:14.300 [job-0] INFO JobContainer - jobContainer starts to do schedule ... 2021-10-09 16:07:14.309 [job-0] INFO JobContainer - Scheduler starts [1] taskGroups. 2021-10-09 16:07:14.314 [job-0] INFO JobContainer - Running by standalone Mode. 2021-10-09 16:07:14.331 [taskGroup-0] INFO TaskGroupContainer - taskGroupId=[0] start [1] channels for [1] tasks. 2021-10-09 16:07:14.349 [taskGroup-0] INFO Channel - Channel set byte_speed_limit to -1, No bps activated. 2021-10-09 16:07:14.350 [taskGroup-0] INFO Channel - Channel set record_speed_limit to -1, No tps activated. 2021-10-09 16:07:14.380 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[0] attemptCount[1] is started 2021-10-09 16:07:14.783 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[0] is successed, used[403]ms 2021-10-09 16:07:14.784 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] completed it's tasks. 2021-10-09 16:07:24.370 [job-0] INFO StandAloneJobContainerCommunicator - Total 100000 records, 2600000 bytes | Speed 253.91KB/s, 10000 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.039s | All Task WaitReaderTime 0.071s | Percentage 100.00% 2021-10-09 16:07:24.371 [job-0] INFO AbstractScheduler - Scheduler accomplished all tasks. 2021-10-09 16:07:24.372 [job-0] INFO JobContainer - DataX Writer.Job [streamwriter] do post work. 2021-10-09 16:07:24.373 [job-0] INFO JobContainer - DataX Reader.Job [streamreader] do post work. 2021-10-09 16:07:24.373 [job-0] INFO JobContainer - DataX jobId [0] completed successfully. 2021-10-09 16:07:24.374 [job-0] INFO HookInvoker - No hook invoked, because base dir not exists or is a file: /usr/local/datax/hook 2021-10-09 16:07:24.377 [job-0] INFO JobContainer - [total cpu info] => averageCpu | maxDeltaCpu | minDeltaCpu -1.00% | -1.00% | -1.00% [total gc info] => NAME | totalGCCount | maxDeltaGCCount | minDeltaGCCount | totalGCTime | maxDeltaGCTime | minDeltaGCTime PS MarkSweep | 0 | 0 | 0 | 0.000s | 0.000s | 0.000s PS Scavenge | 0 | 0 | 0 | 0.000s | 0.000s | 0.000s 2021-10-09 16:07:24.378 [job-0] INFO JobContainer - PerfTrace not enable! 2021-10-09 16:07:24.379 [job-0] INFO StandAloneJobContainerCommunicator - Total 100000 records, 2600000 bytes | Speed 253.91KB/s, 10000 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.039s | All Task WaitReaderTime 0.071s | Percentage 100.00% 2021-10-09 16:07:24.380 [job-0] INFO JobContainer - 任务启动时刻 : 2021-10-09 16:07:14 任务结束时刻 : 2021-10-09 16:07:24 任务总计耗时 : 10s 任务平均流量 : 253.91KB/s 记录写入速度 : 10000rec/s 读出记录总数 : 100000 读写失败总数 : 0 |
DataX Web
https://gitee.com/WeiYe-Jing/datax-web
https://github.com/WeiYe-Jing/datax-web
https://segmentfault.com/u/weiye_jing/articles
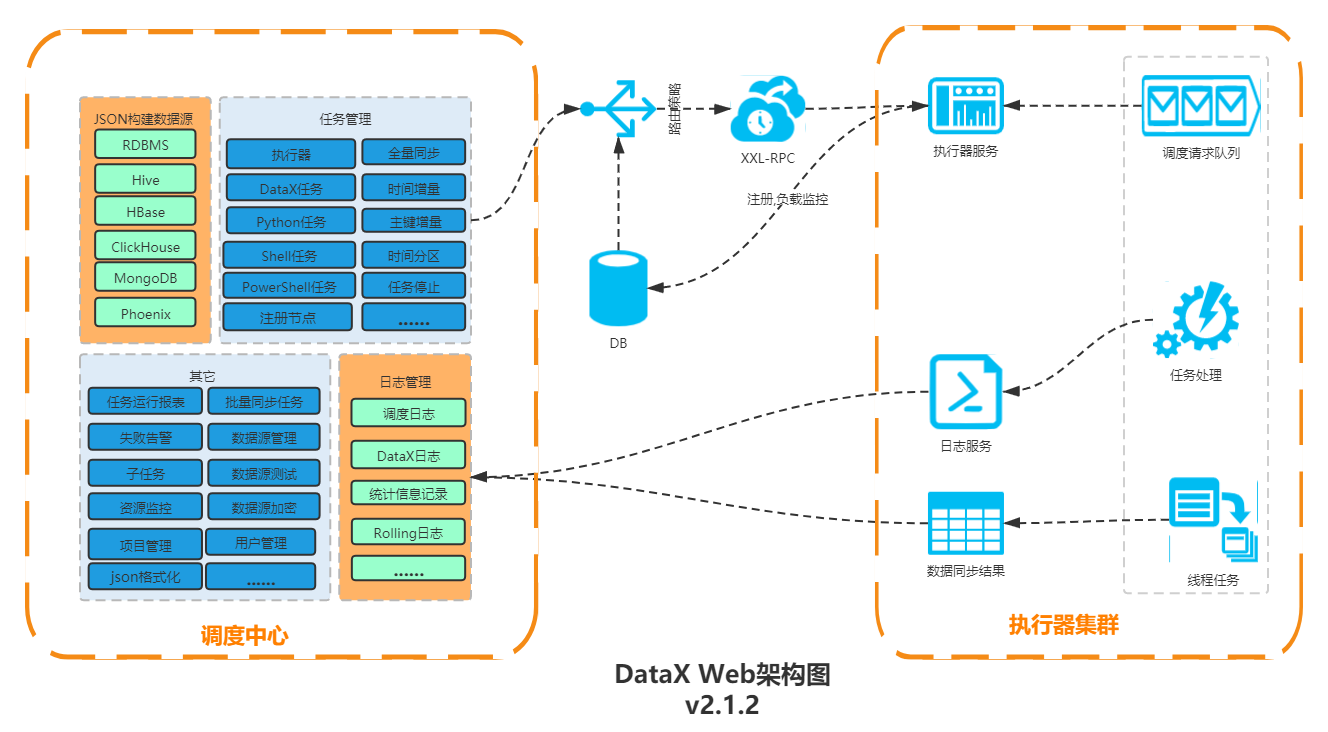
DataX Web是在DataX之上开发的分布式数据同步工具,提供简单易用的 操作界面,降低用户使用DataX的学习成本,缩短任务配置时间,避免配置过程中出错。用户可通过页面选择数据源即可创建数据同步任务,支持RDBMS、Hive、HBase、ClickHouse、MongoDB等数据源,RDBMS数据源可批量创建数据同步任务,支持实时查看数据同步进度及日志并提供终止同步功能,集成并二次开发xxl-job可根据时间、自增主键增量同步数据。
任务"执行器"支持集群部署,支持执行器多节点路由策略选择,支持超时控制、失败重试、失败告警、任务依赖,执行器CPU.内存.负载的监控等等。后续还将提供更多的数据源支持、数据转换UDF、表结构同步、数据同步血缘等更为复杂的业务场景。
结构图
特性
- 1、通过Web构建DataX Json;
- 2、DataX Json保存在数据库中,方便任务的迁移,管理;
- 3、Web实时查看抽取日志,类似Jenkins的日志控制台输出功能;
- 4、DataX运行记录展示,可页面操作停止DataX作业;
- 5、支持DataX定时任务,支持动态修改任务状态、启动/停止任务,以及终止运行中任务,即时生效;
- 6、调度采用中心式设计,支持集群部署;
- 7、任务分布式执行,任务"执行器"支持集群部署;
- 8、执行器会周期性自动注册任务, 调度中心将会自动发现注册的任务并触发执行;
- 9、路由策略:执行器集群部署时提供丰富的路由策略,包括:第一个、最后一个、轮询、随机、一致性HASH、最不经常使用、最近最久未使用、故障转移、忙碌转移等;
- 10、阻塞处理策略:调度过于密集执行器来不及处理时的处理策略,策略包括:单机串行(默认)、丢弃后续调度、覆盖之前调度;
- 11、任务超时控制:支持自定义任务超时时间,任务运行超时将会主动中断任务;
- 12、任务失败重试:支持自定义任务失败重试次数,当任务失败时将会按照预设的失败重试次数主动进行重试;
- 13、任务失败告警;默认提供邮件方式失败告警,同时预留扩展接口,可方便的扩展短信、钉钉等告警方式;
- 14、用户管理:支持在线管理系统用户,存在管理员、普通用户两种角色;
- 15、任务依赖:支持配置子任务依赖,当父任务执行结束且执行成功后将会主动触发一次子任务的执行, 多个子任务用逗号分隔;
- 16、运行报表:支持实时查看运行数据,以及调度报表,如调度日期分布图,调度成功分布图等;
- 17、指定增量字段,配置定时任务自动获取每次的数据区间,任务失败重试,保证数据安全;
- 18、页面可配置DataX启动JVM参数;
- 19、数据源配置成功后添加手动测试功能;
- 20、可以对常用任务进行配置模板,在构建完JSON之后可选择关联模板创建任务;
- 21、jdbc添加hive数据源支持,可在构建JSON页面选择数据源生成column信息并简化配置;
- 22、优先通过环境变量获取DataX文件目录,集群部署时不用指定JSON及日志目录;
- 23、通过动态参数配置指定hive分区,也可以配合增量实现增量数据动态插入分区;
- 24、任务类型由原来DataX任务扩展到Shell任务、Python任务、PowerShell任务;
- 25、添加HBase数据源支持,JSON构建可通过HBase数据源获取hbaseConfig,column;
- 26、添加MongoDB数据源支持,用户仅需要选择collectionName即可完成json构建;
- 27、添加执行器CPU、内存、负载的监控页面;
- 28、添加24类插件DataX JSON配置样例
- 29、公共字段(创建时间,创建人,修改时间,修改者)插入或更新时自动填充
- 30、对swagger接口进行token验证
- 31、任务增加超时时间,对超时任务kill datax进程,可配合重试策略避免网络问题导致的datax卡死。
- 32、添加项目管理模块,可对任务分类管理;
- 33、对RDBMS数据源增加批量任务创建功能,选择数据源,表即可根据模板批量生成DataX同步任务;
- 34、JSON构建增加ClickHouse数据源支持;
- 35、执行器CPU.内存.负载的监控页面图形化;
- 36、RDBMS数据源增量抽取增加主键自增方式并优化页面参数配置;
- 37、更换MongoDB数据源连接方式,重构HBase数据源JSON构建模块;
- 38、脚本类型任务增加停止功能;
- 39、rdbms json构建增加postSql,并支持构建多个preSql,postSql;
- 40、数据源信息加密算法修改及代码优化;
- 41、日志页面增加DataX执行结果统计数据;
功能介绍
操作流程如下:
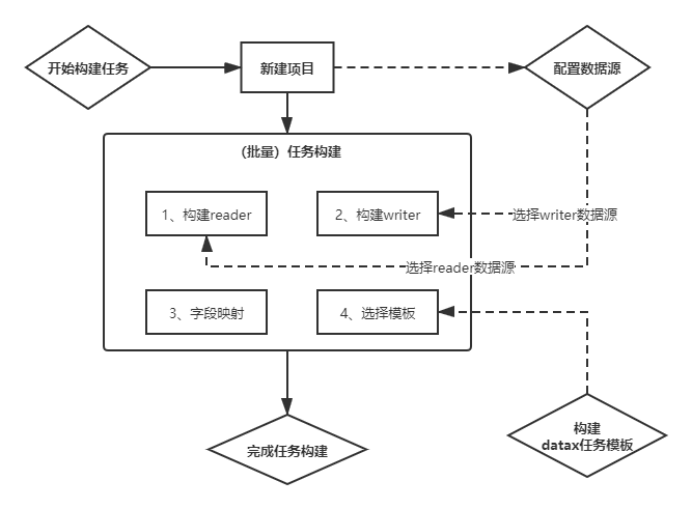
1.执行器配置(使用开源项目xxl-job)
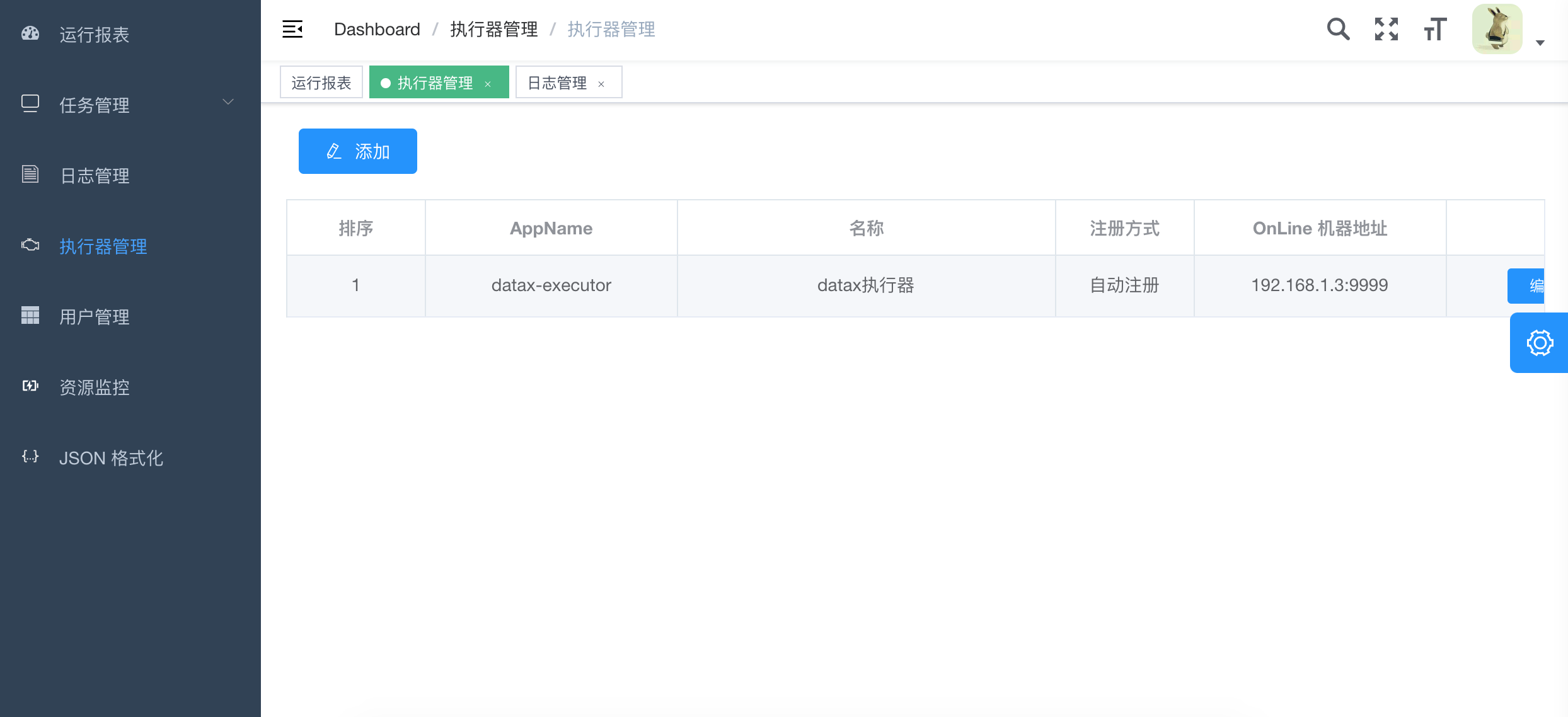
- 1、"调度中心OnLine:"右侧显示在线的"调度中心"列表, 任务执行结束后, 将会以failover的模式进行回调调度中心通知执行结果, 避免回调的单点风险;
- 2、"执行器列表" 中显示在线的执行器列表, 可通过"OnLine 机器"查看对应执行器的集群机器;
执行器属性说明
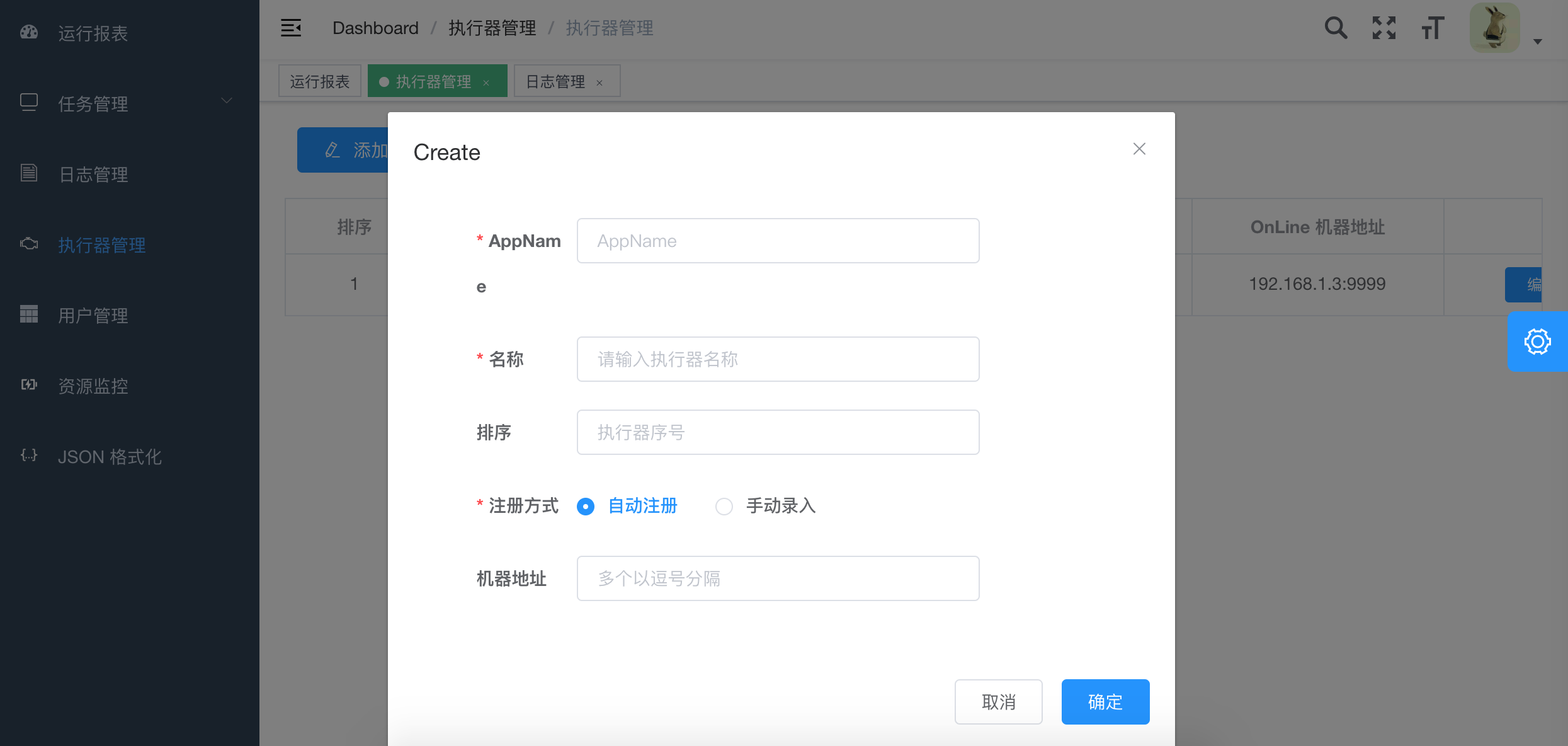
1、AppName: (与datax-executor中application.yml的datax.job.executor.appname保持一致)
每个执行器集群的唯一标示AppName, 执行器会周期性以AppName为对象进行自动注册。可通过该配置自动发现注册成功的执行器, 供任务调度时使用;
2、名称: 执行器的名称, 因为AppName限制字母数字等组成,可读性不强, 名称为了提高执行器的可读性;
3、排序: 执行器的排序, 系统中需要执行器的地方,如任务新增, 将会按照该排序读取可用的执行器列表;
4、注册方式:调度中心获取执行器地址的方式;
自动注册:执行器自动进行执行器注册,调度中心通过底层注册表可以动态发现执行器机器地址;
手动录入:人工手动录入执行器的地址信息,多地址逗号分隔,供调度中心使用;
5、机器地址:"注册方式"为"手动录入"时有效,支持人工维护执行器的地址信息;
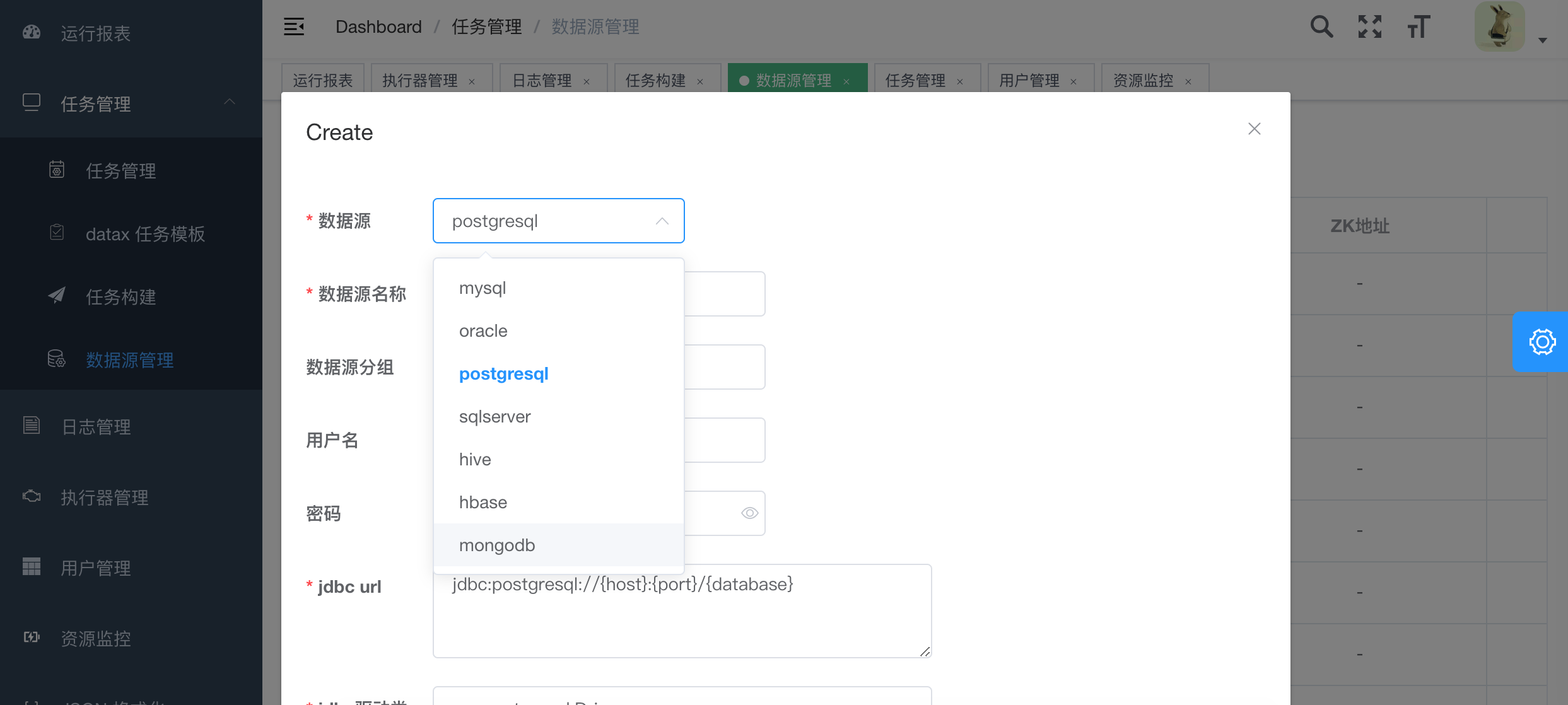
2.创建数据源
第四步使用
3.创建任务模版

第四步使用
4. 构建JSON脚本
- 1.步骤一,步骤二,选择第二步中创建的数据源,JSON构建目前支持的数据源有hive,mysql,oracle,postgresql,sqlserver,hbase,mongodb,clickhouse 其它数据源的JSON构建正在开发中,暂时需要手动编写。
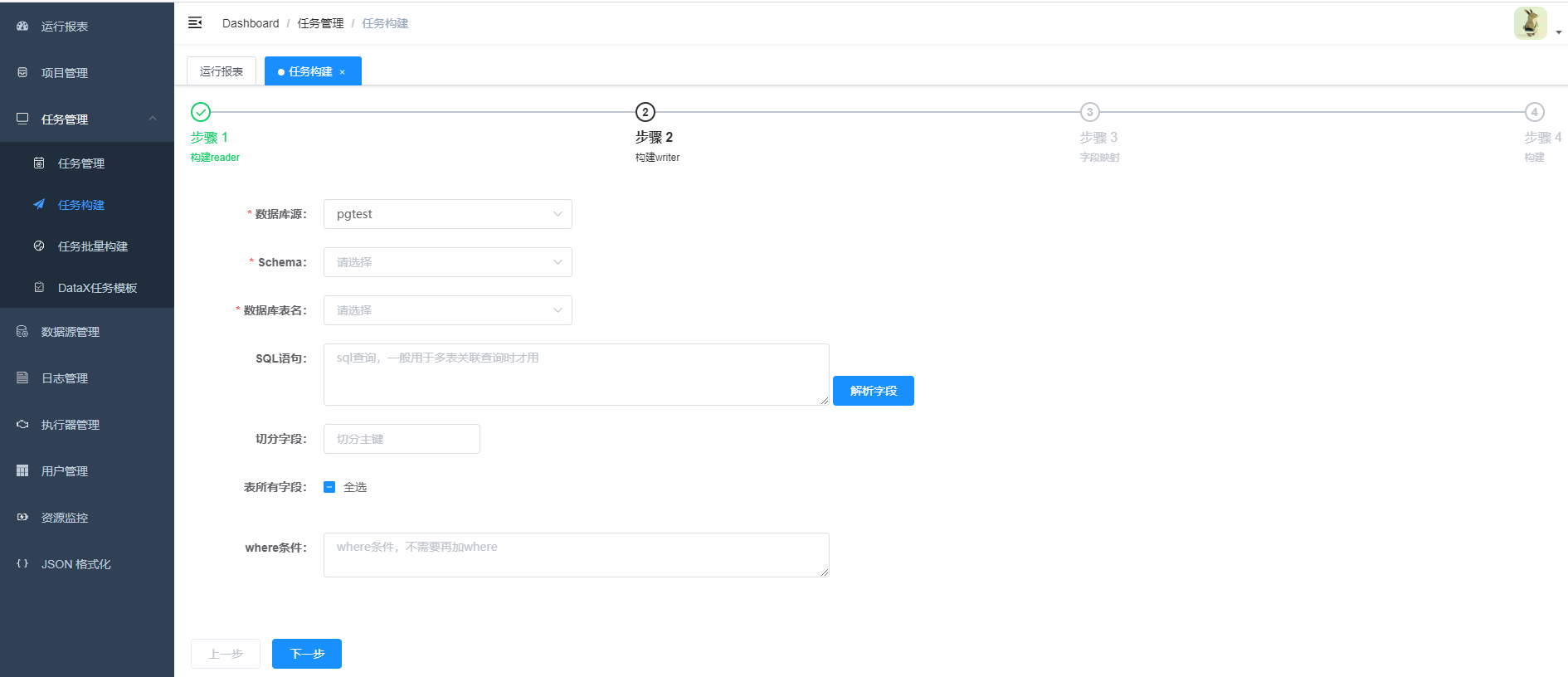
- 2.字段映射
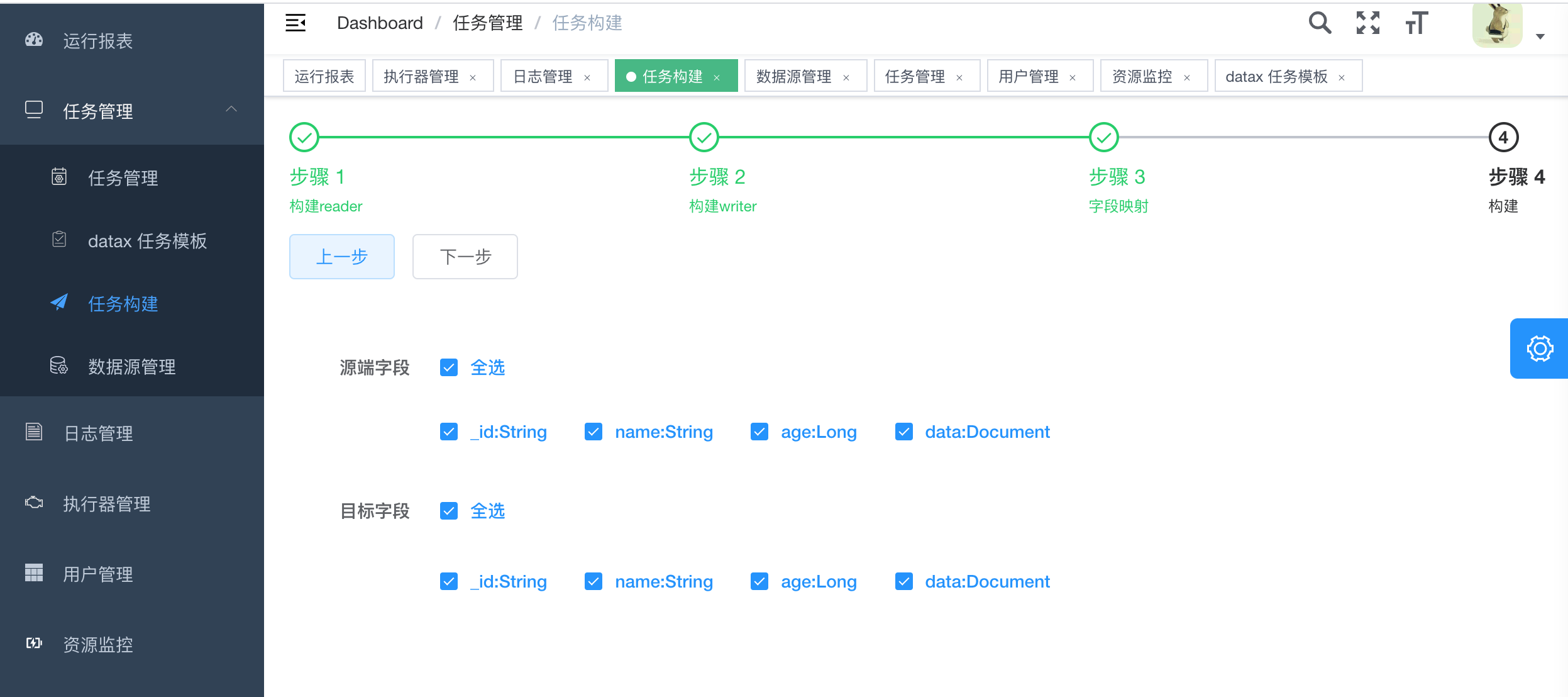
- 3.点击构建,生成json,此时可以选择复制json然后创建任务,选择datax任务,将json粘贴到文本框。也可以点击选择模版,直接生成任务。
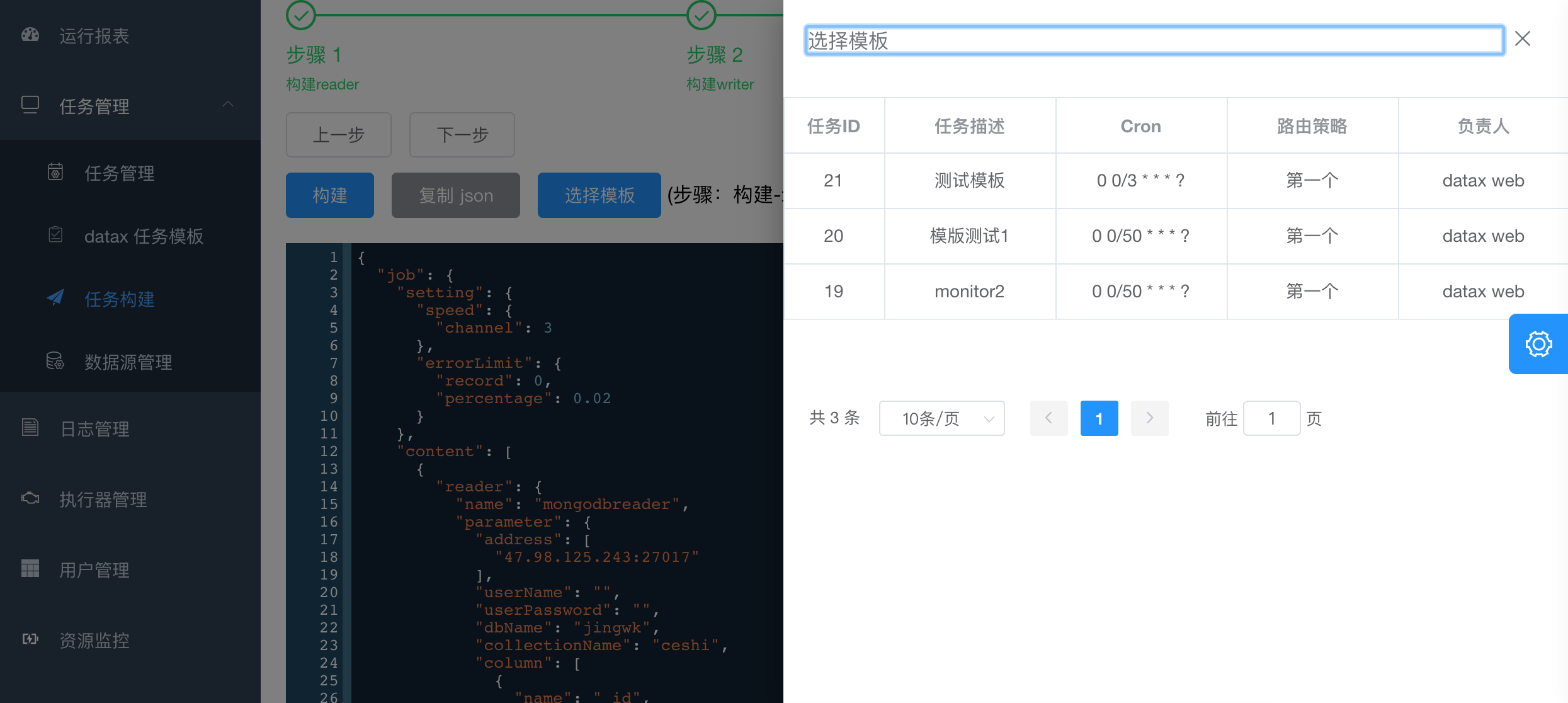
5.批量创建任务
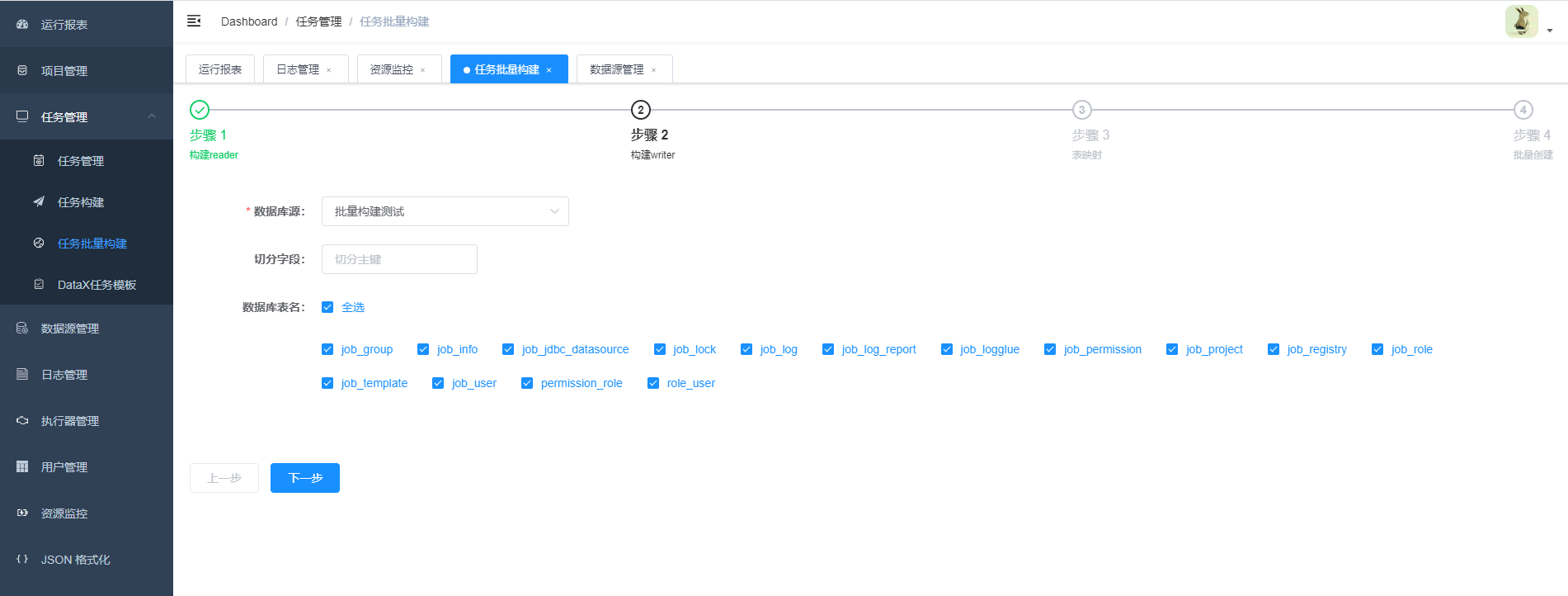
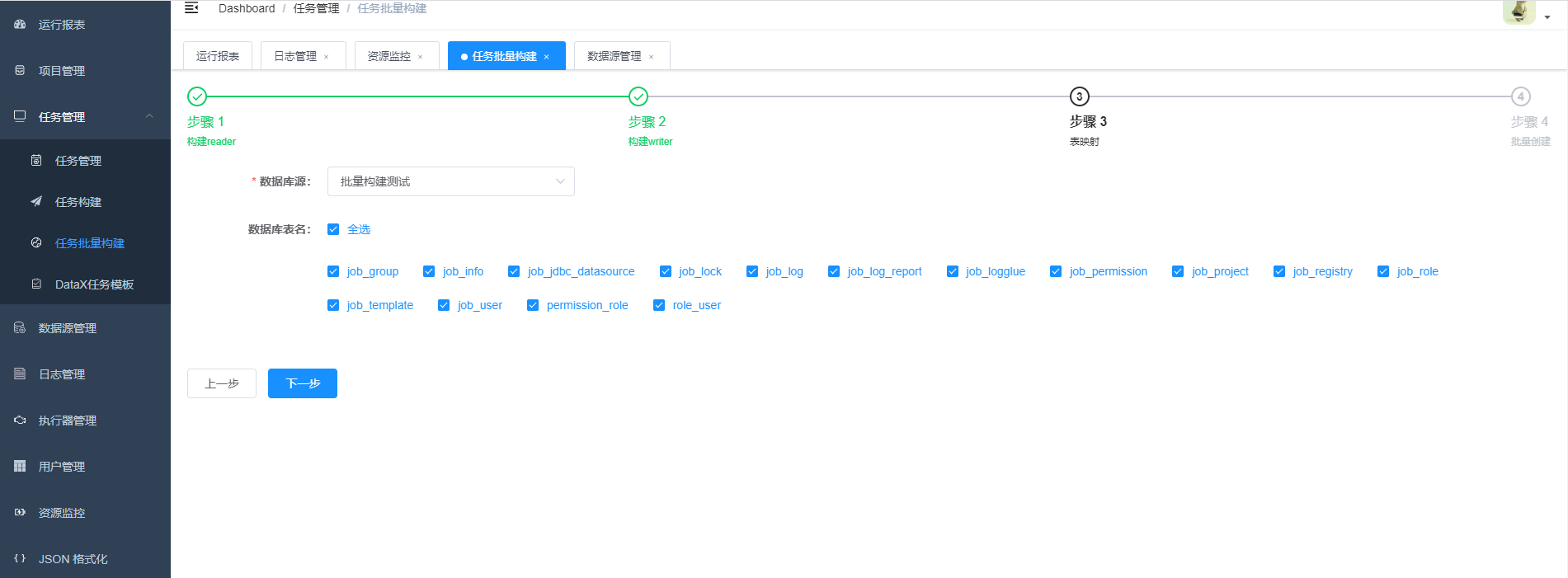
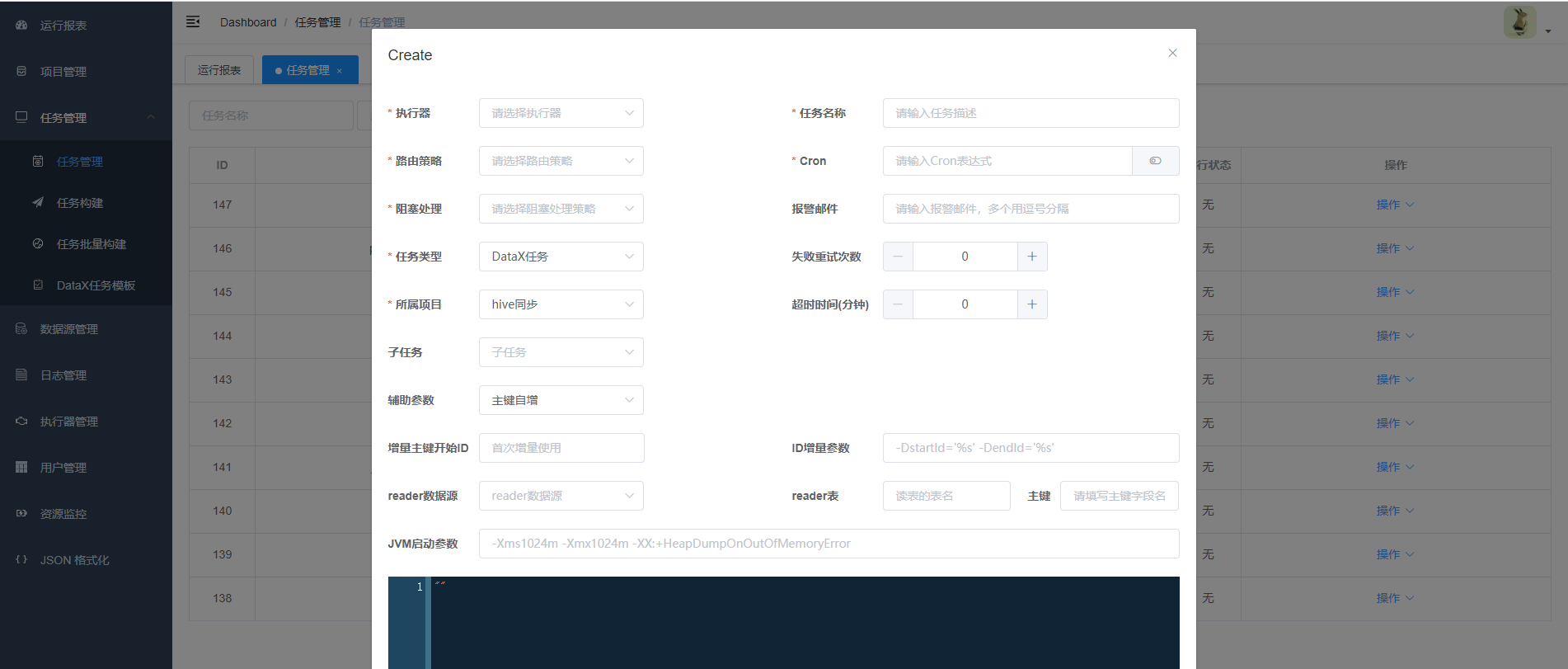
6.任务创建介绍(关联模版创建任务不再介绍,具体参考4. 构建JSON脚本)
支持DataX任务,Shell任务,Python任务,PowerShell任务
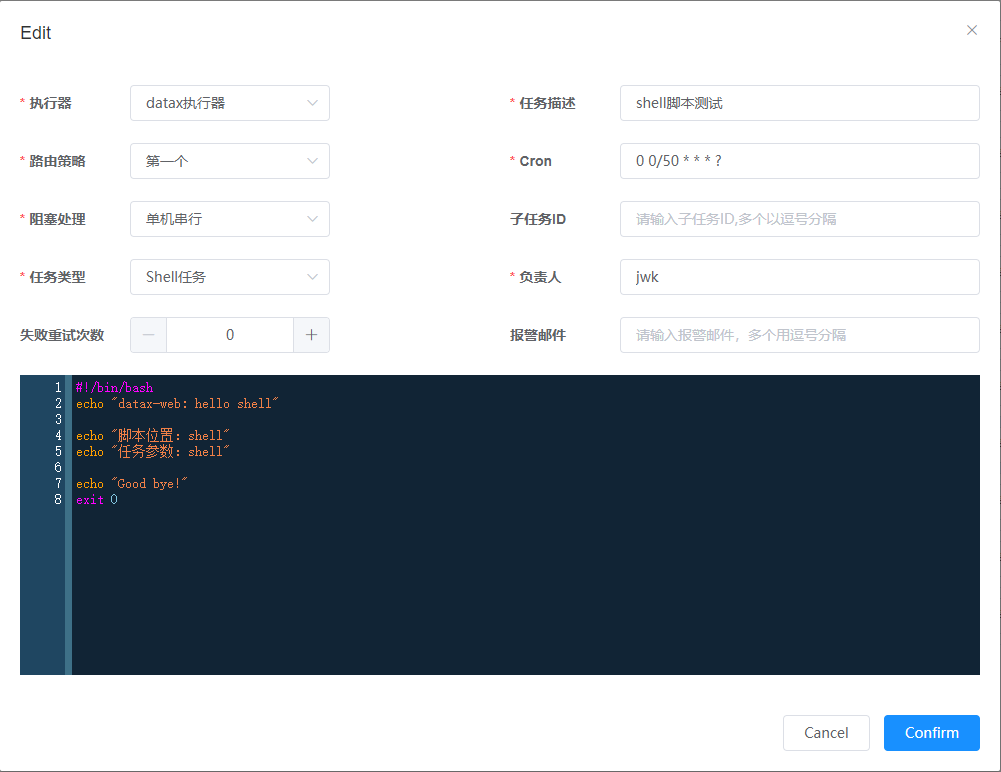
阻塞处理策略:调度过于密集执行器来不及处理时的处理策略;
- 单机串行:调度请求进入单机执行器后,调度请求进入FIFO队列并以串行方式运行;
- 丢弃后续调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,本次请求将会被丢弃并标记为失败;
- 覆盖之前调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,将会终止运行中的调度任务并清空队列,然后运行本地调度任务;
增量增新建议将阻塞策略设置为丢弃后续调度或者单机串行
- 设置单机串行时应该注意合理设置重试次数(失败重试的次数*每次执行时间<任务的调度周期),重试的次数如果设置的过多会导致数据重复,例如任务30秒执行一次,每次执行时间需要20秒,设置重试三次,如果任务失败了,第一个重试的时间段为1577755680-1577756680,重试任务没结束,新任务又开启,那新任务的时间段会是1577755680-1577758680
7. 任务列表
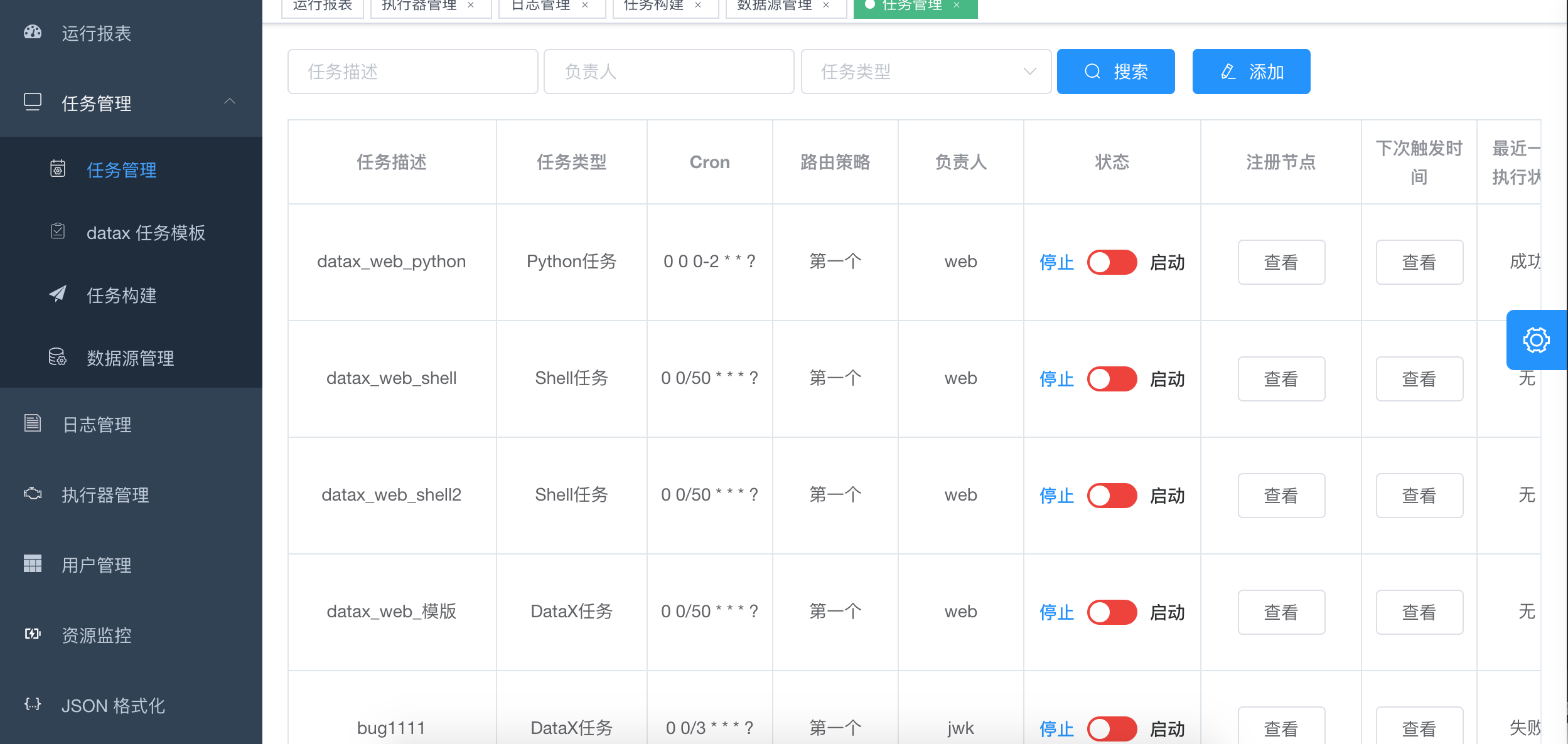
8. 可以点击查看日志,实时获取日志信息,终止正在执行的datax进程
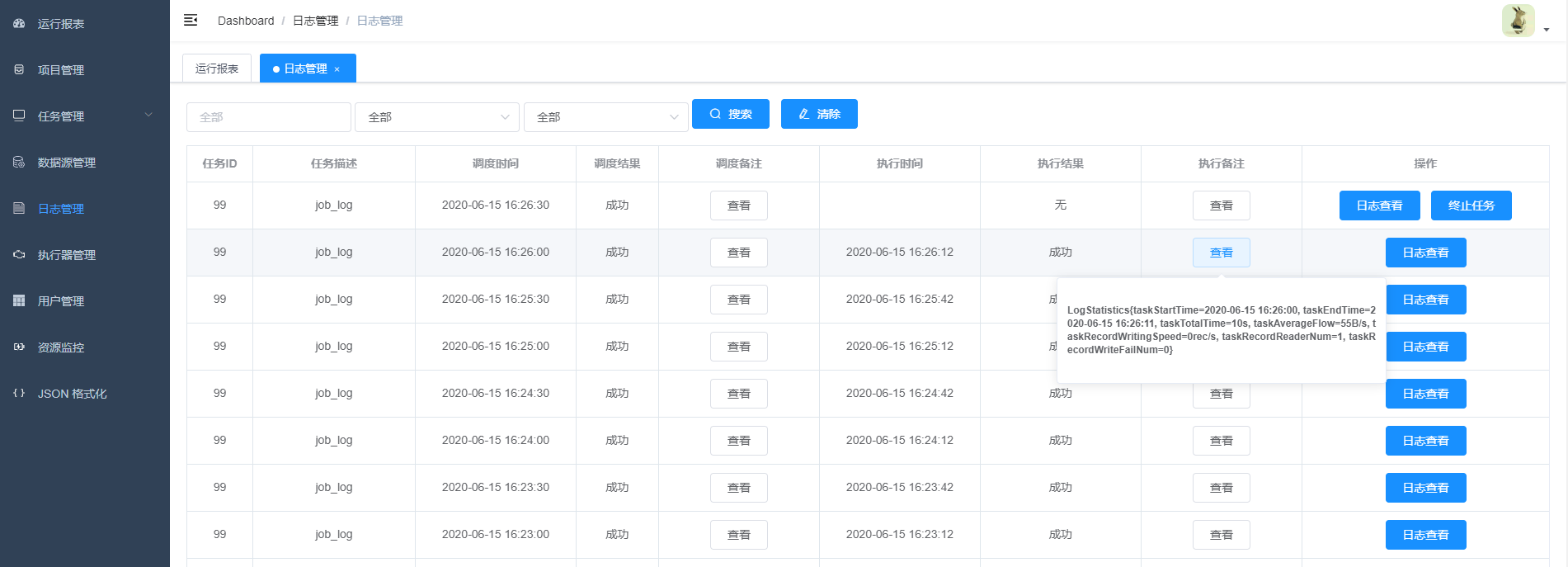
9.任务资源监控
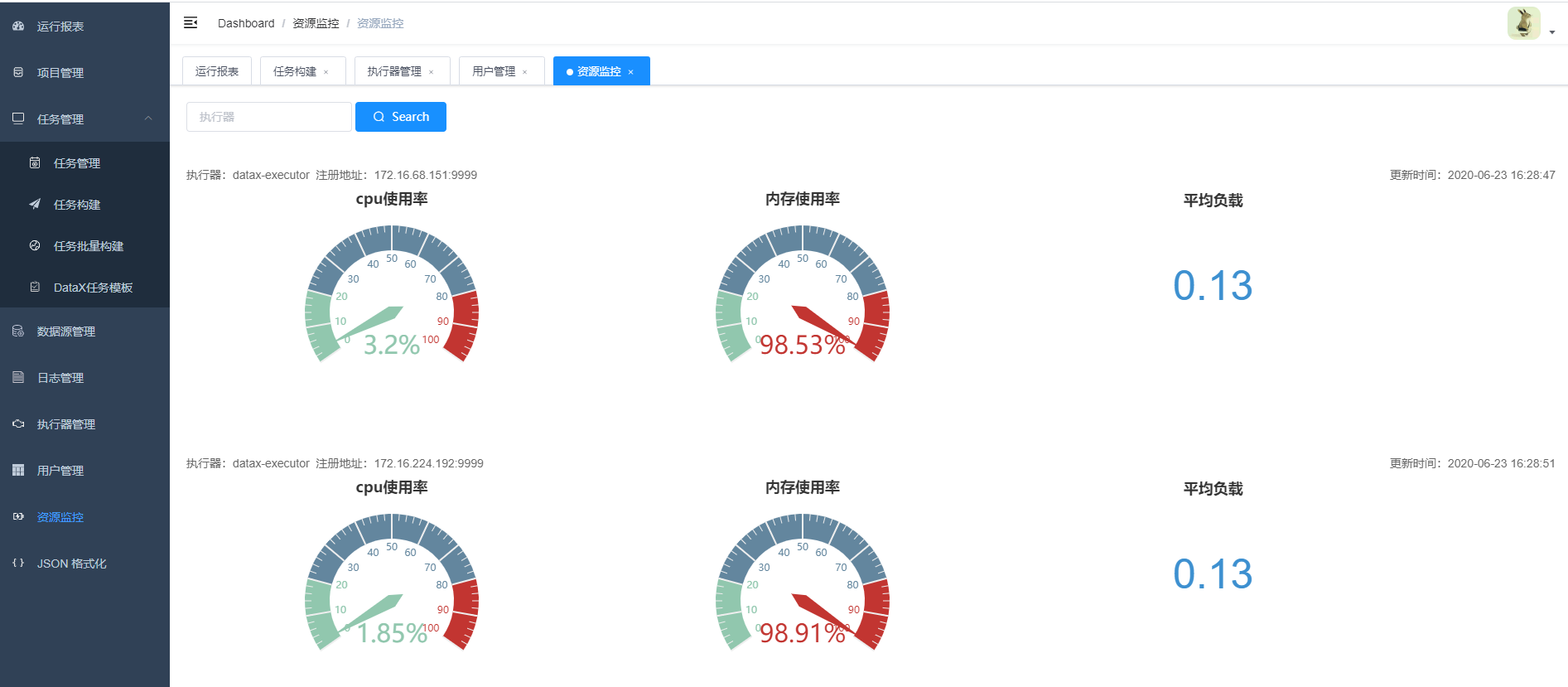
10. admin可以创建用户,编辑用户信息
UI
安装配置
请点击:Quick Start:https://github.com/WeiYe-Jing/datax-web/blob/master/userGuid.md
Linux:一键部署:https://github.com/WeiYe-Jing/datax-web/blob/master/doc/datax-web/datax-web-deploy.md
系统要求
- Language: Java 8(jdk版本建议1.8.201以上)
Python2.7(支持Python3需要修改替换datax/bin下面的三个python文件,替换文件在doc/datax-web/datax-python3下) - Environment: MacOS, Windows,Linux
- Database: Mysql5.7
基础软件安装
- MySQL (5.5+) 必选,对应客户端可以选装, Linux服务上若安装mysql的客户端可以通过部署脚本快速初始化数据库
- JDK (1.8.0_xxx) 必选
- Maven (3.6.1+) 必选
- DataX 必选
- Python (2.x) (支持Python3需要修改替换datax/bin下面的三个python文件,替换文件在doc/datax-web/datax-python3下) 必选,主要用于调度执行底层DataX的启动脚本,默认的方式是以Java子进程方式执行DataX,用户可以选择以Python方式来做自定义的改造
环境准备
1)基础软件安装
- MySQL (5.5+) 必选,对应客户端可以选装, Linux服务上若安装mysql的客户端可以通过部署脚本快速初始化数据库
- JDK (1.8.0_xxx) 必选
- Maven (3.6.1+) 必选
- DataX 必选
- Python (2.x) (支持Python3需要修改替换datax/bin下面的三个python文件,替换文件在doc/datax-web/datax-python3下)
必选,主要用于调度执行底层DataX的启动脚本,默认的方式是以Java子进程方式执行DataX,用户可以选择以Python方式来做自定义的改造
DataX Web安装包准备
1)下载官方提供的版本tar版本包
百度网盘:https://pan.baidu.com/s/13yoqhGpD00I82K4lOYtQhg
提取码:cpsk
2) 编译打包(官方提供的tar包跳过)
直接从Git上面获得源代码,在项目的根目录下执行如下命令
1 | mvn clean install |
执行成功后将会在工程的build目录下生成安装包
1 | build/datax-web-{VERSION}.tar.gz |
Linux环境开始部署
1)解压安装包
在选定的安装目录,解压安装包