合 阿里数据同步工具Otter和Canal简介
Tags: MySQL高可用主从复制双主数据同步OtterCanal跨机房阿里
常见问题
1. canal和otter的关系?
答: 在回答这问题之前,首先来看一张canal&otter和mysql复制的类比图.
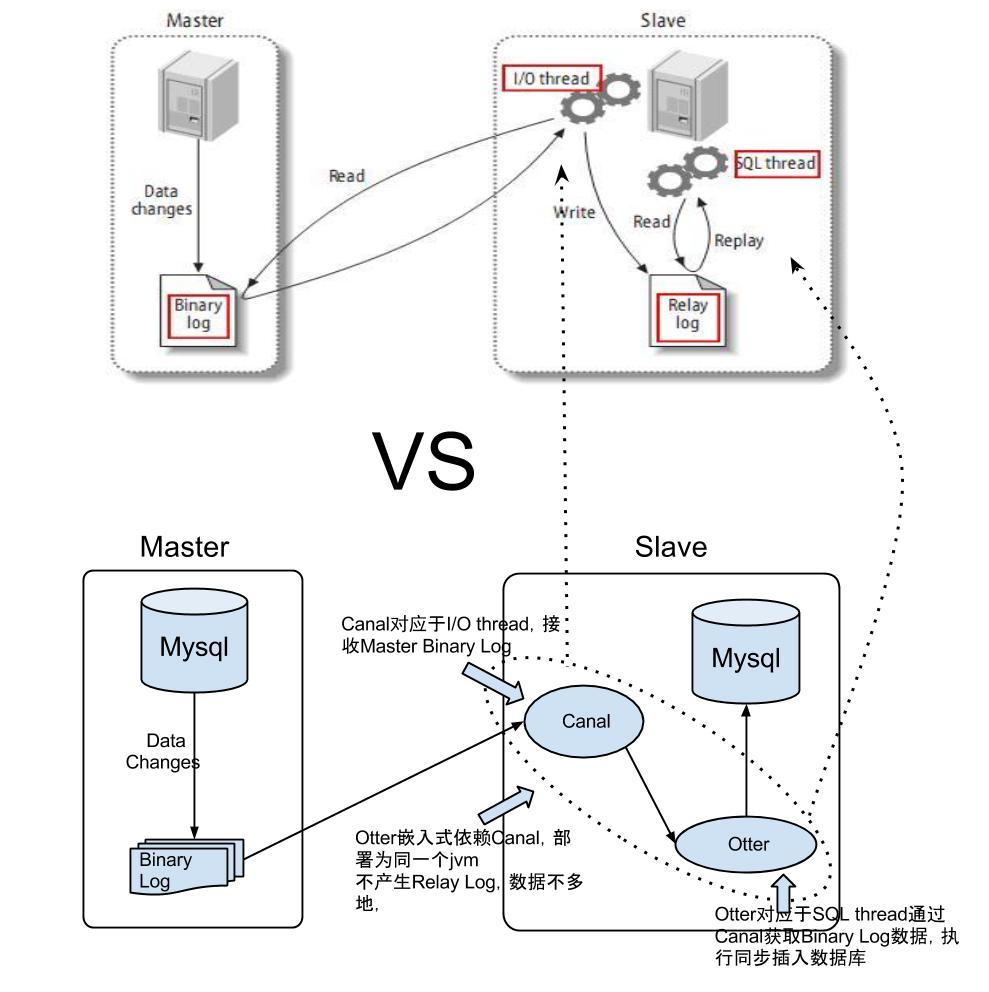
mysql的自带复制技术可分成三步:
- master将改变记录到二进制日志(binary log)中(这些记录叫做二进制日志事件,binary log events,可以通过show binlog events进行查看);
- slave将master的binary log events拷贝到它的中继日志(relay log),这里是I/O thread线程.
- slave重做中继日志中的事件,将改变反映它自己的数据,这里是SQL thread线程.
基于canal&otter的复制技术和mysql复制类似,具有类比性.
- Canal对应于I/O thread,接收Master Binary Log.
- Otter对应于SQL thread,通过Canal获取Binary Log数据,执行同步插入数据库.
两者的区别在于:
- otter目前嵌入式依赖canal,部署为同一个jvm,目前设计为不产生Relay Log,数据不落地.
- otter目前允许自定义同步逻辑,解决各类需求.
a. ETL转化. 比如Slave上目标表的表名,字段名,字段类型不同,字段个数不同等.
b. 异构数据库. 比如Slave可以是oracle或者其他类型的存储,nosql等.
c. M-M部署,解决数据一致性问题
d. 基于manager部署,方便监控同步状态和管理同步任务.
2. canal目前支持的数据库版本?
答: 支持mysql系列的5.1 ~ 5.6/5.7、8.x版本(5.1.x , 5.5.x , 5.6.x , 5.7.x , 8.0.x),mariadb 5/10版本. (全面支持ROW/STATEMENT/MIXED几种binlog格式的解析)
3. otter目前支持的数据库情况?
答:这里总结了一下
- otter依赖canal解决数据库增量日志,所以会受到canal的版本支持限制,仅支持mysql系列,不支持oracle做为master库进行解析.
- mysql做为master,otter只支持ROW模式的数据同步,其他两种模式不支持. (只有ROW模式可保证数据的最终一致性)
- 目标库,也就是slave,可支持mysql/oracle,也就是说可以将mysql的数据同步到oracle库中,反过来不行.
4. otter目前存在的同步限制?
答:这里总结了一下
- 暂不支持无主键表同步. (同步的表必须要有主键,对于insert操作,无主键会报错,无主键表update会是一个全表扫描,效率比较差)
- 支持部分ddl同步 (支持create table / drop table / alter table / truncate table / rename table / create index / drop index,其他类型的暂不支持,比如grant,create user,trigger等等),同时ddl语句不支持幂等性操作,所以出现重复同步时,会导致同步挂起,可通过配置高级参数:跳过ddl异常,来解决这个问题.
- 不支持带外键的记录同步. (数据载入算法会打散事务,进行并行处理,会导致外键约束无法满足)
- 数据库上trigger配置慎重. (比如源库,有一张A表配置了trigger,将A表上的变化记录到B表中,而B表也需要同步。如果目标库也有这trigger,在同步时会插入一次A表,2次B表,因为A表的同步插入也会触发trigger插入一次B表,所以有2次B表同步.)
5. otter同步相比于mysql的优势?
答:
- 管理&运维方便. otter为纯java开发的系统,提供web管理界面,一站式管理整个公司的数据库同步任务.
- 同步效率提升. 在保证数据一致性的前提下,拆散原先Master的事务内容,基于pk hash的并发同步,可以有效提升5倍以上的同步效率.
- 自定义同步功能. 支持基于增量复制的前提下,定义ETL转化逻辑,完成特殊功能.
- 异地机房同步. 相比于mysql异地长距离机房的复制效率,比如阿里巴巴杭州和美国机房,复制可以提升20倍以上. 长距离传输时,master向slave传输binary log可能会是一个瓶颈.
- 双A机房同步. 目前mysql的M-M部署结构,不支持解决数据的一致性问题,基于otter的双向复制+一致性算法,可完美解决这个问题,真正实现双A机房.
- 特殊功能.
a. 支持图片同步. 数据库中的一条记录,比如产品记录,会在数据库里存在一张图片的path路径,可定义规则,在同步数据的同时,将图片同步到目标.
6. node jvm内存不够用,如何解决?
node出现java.lang.OutOfMemoryError : Gc overhead limit exceeded.
答:
单node建议的同步任务,建议控制下1~2w tps以下,不然内存不够用. 出现不够用时,具体的解决方案:
- 调大node的-Xms,-Xmx内存设置,默认为3G,heap区大概是2GB
减少每个同步的任务内存配置.
a. canal配置里有个内存存储buffer记录数参数,默认是32768,代表32MB的binlog,解析后在内存中会占用100MB的样子.
b. pipeline配置里有个批次大小设置,默认是6000,代表每次获取6MB左右,解析后在内存占用=并行度6MB3,大概也是100MB的样子.所以默认参数,全速跑时,单个通道占用200MB的样子,2GB能跑几个大概能估算出来了
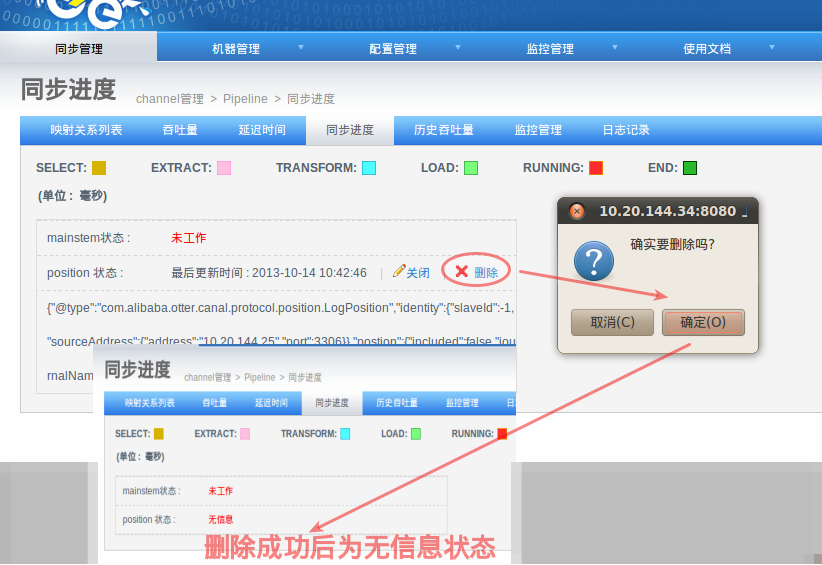
7. 源库binlog不正确,如何重置同步使用新的位点开始同步?
场景:
- 源库binlog被删除,比如出现:Could not find first log file name in binary log index file
- 源库binlog出现致命解析错误,比如运行过程使用了删除性质的ddl,drop table操作,导致后续binlog在解析时无法获取表结构.
答:
首先需要理解一下canal的位置管理,主要有两个位点信息:起始位置 和 运行位置(记录最后一次正常消费的位置). 优先加载运行位置,第一次启动无运行位置,就会使用起始位置进行初始化,第一次客户端反馈了ack信号后,就会记录运行位置.
所以重置位置的几步操作:
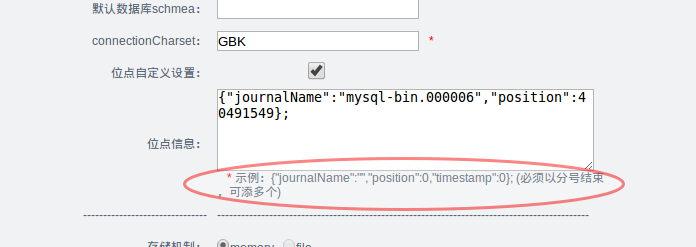
删除运行位置. (pipeline同步进度页面配置)

配置起始位置. (canal配置页面)
本人提供Oracle(OCP、OCM)、MySQL(OCP)、PostgreSQL(PGCA、PGCE、PGCM)等数据库的培训和考证业务,私聊QQ646634621或微信dbaup66,谢谢!