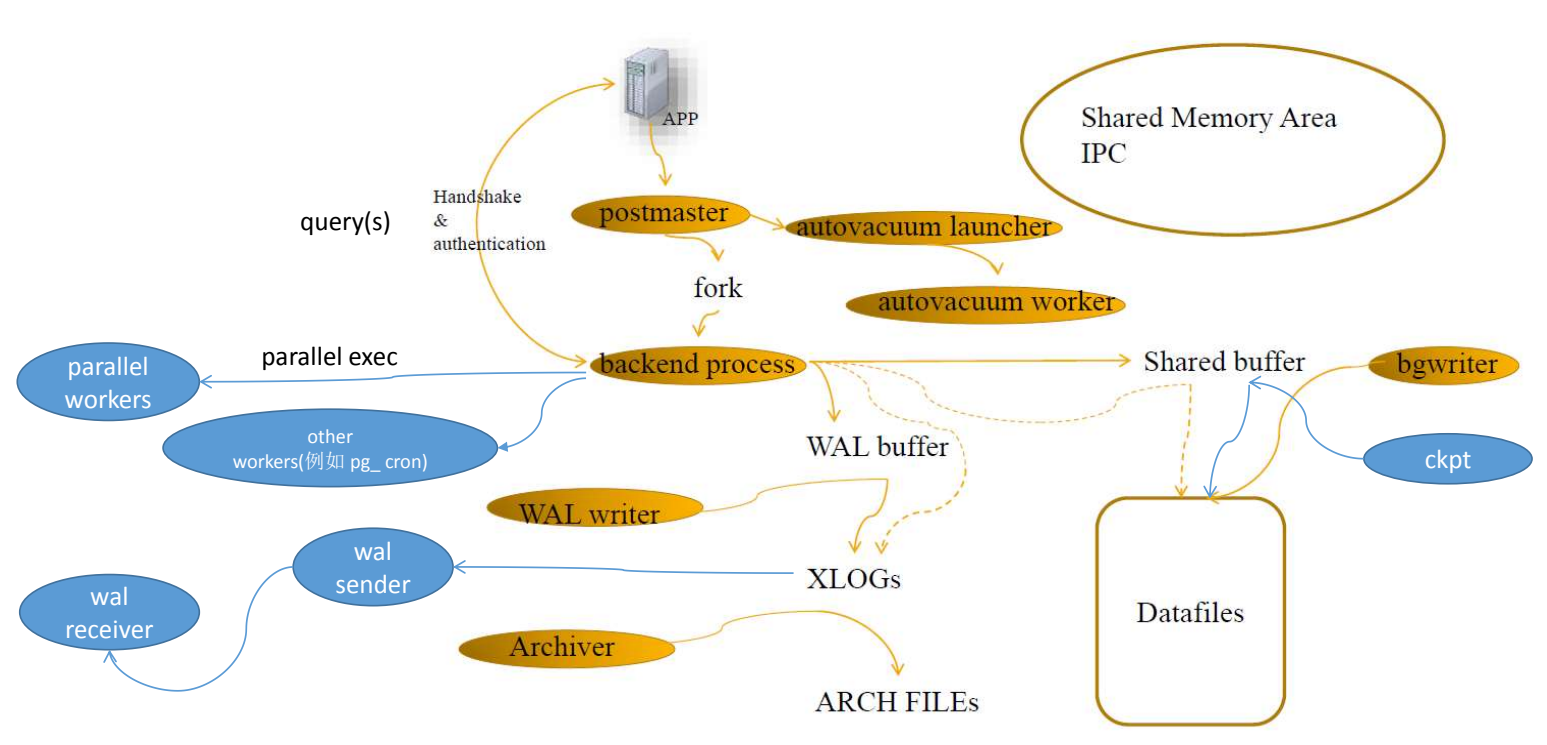
合 常用的psql命令
简介
psql是一个PostgreSQL的基于终端的前端。它让你能交互式地键入查询,把它们发送给PostgreSQL,并且查看查询结果。或者,输入可以来自于一个文件或者命令行参数。此外,psql还提供一些元命令和多种类似 shell 的特性来为编写脚本和自动化多种任务提供便利。
psql 是 PostgreSQL 中的一个命令行交互式客户端工具,它允许你交互地键入 SQL 命令,然后把它们发送给 PostgreSQL 服务器,再显示 SQL 或命令的结果。
输入的内容允许来自一个文件,此外它还提供了一些元命令和多种类似 shell 的特性来实现书写脚本,以及对大量任务的自动化工作。
特性:方便快捷、没有图形化工具使用上的一些限制
1 2 3 4 5 6 7 8 9 | -- 远程登陆 psql -U postgres -h 192.168.66.35 -d postgres -p15432 -- 从Postgresql 9.2开始,还可以使用URI格式进行连接:psql postgresql://myuser:mypasswd@myhost:5432/mydb psql postgresql://postgres:lhr@192.168.66.35:15432/postgres -- 加connect_timeout参数保证会话不断开 psql postgresql://xxt:lhr@127.0.0.1:8104/lhrdb?connect_timeout=10 |
其中,各部分的含义如下:
username:要连接的数据库的用户名。password:连接数据库所使用的密码。hostname:数据库服务器的主机名或IP地址。port:数据库服务器的端口号,默认为5432。dbname:要连接的数据库名称。
请注意,使用URI格式连接时,密码是明文传递的,因此需要小心保护连接字符串的安全性,避免密码泄露。
执行脚本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 | 1.准备sql脚本文件tmp.sql create table public.stu(id int,name varchar); Insert into public.stu values(1,'a'); Insert into public.stu values(2,'a'); Insert into public.stu values(3,'a'); Insert into public.stu values(4,'a'); 2.演练以下元命令 \e #编辑脚本文件 #执行脚本文件的方法有以下几种方式,效果相同 \i /home/postgres/tmpscript/tmp.sql psql -f /home/postgres/tmpscript/tmp.sql psql < /home/postgres/tmpscript/tmp.sql 3.演示输出重定向 \o /home/postgres/select.out #打开文件重定向输出 Select * from stu; \o #关闭重定向文件 testdb=# \! cat /home/postgres/select.out id | name ----+------ 1 | a 2 | a 3 | a 4 | a (4 rows) 示例4:psql设置详细的打印输出 \set VERBOSITY verbose postgres=# select a; ERROR: column "a" does not exist LINE 1: select a; ^ postgres=# \set VERBOSITY verbose postgres=# select a; ERROR: 42703: column "a" does not exist --可以报出问题的代码 LINE 1: select a; ^ LOCATION: errorMissingColumn, parse_relation.c:3293 |
常用选项
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 | \d [ table ] 列出数据库中的表,或(如果声明了)表 table 的列/字段.如果表名是用统配符 (“*”)声明的,列出所有表和表的列/字段信息. \da 列出所有可用聚集. \dd object 列出 pg_description 里对声明的对象的描述,对象可以是一个表,表中的列/字段,类型,操作符或聚集. 小技巧:并非所有对象在 pg_description 里有描述.此后期命令在快速获取 Postgres 内部特性时很有用. \df 列出函数. \di 只列出索引. \do 只列出操作符. \ds 只列出序列. \dS 列出系统表和索引. \dt 只列出非系统表. \dT 列出类型. \e [ filename ] 编辑当前查询缓冲或文件 filename 的内容. \E [ filename ] 编辑当前查询缓冲或文件 filename 的内容并且在编辑结束后执行之. \f [ separator ] 设置域分隔符.缺省是单个空白. \g [ { filename | |command } ] 将当前查询输入缓冲送给后端并且(可选的)将输出放到 filename 或通过管道将输出送给一个分离的Unix shell 用以执行 command. \h [ command ] 给出声明的 SQL 命令的语法帮助.如果 command 不是一个定义的 SQL 命令(或在 psql 里没有文档),或没有声明 command ,这时 psql将列出可获得帮助的所有命令的列表.如果命令 command 是一个通配符(“*”),则给出所有 SQL 命令的语法帮助. \H 切换 HTML3 输出.等效于 -H 命令行选项. \i filename 从文件 filename 中读取查询到输入缓冲. \l 列出服务器上所有数据库. \m 切换老式监视器样的表输出,这时表周围有边界字符包围着.这是标准 SQL 输出.缺省时,psql 只包括列/字段间的分隔符. \o [ { filename | |command } ] 将后面的查询结果输出到文件 filename 或通过管道将后面结果输出到一个独立的Unix shell 里执行 command.如果没有声明参数,将查询结果输出到 stdout. \p 打印当前查询缓冲区. \q 退出 psql 程序. \r 重置(清空)查询缓冲区. \s [ filename ] 将命令行历史打印出或是存放到 filename.如果省略 filename ,将不会把后继的命令存放到历史文件中.此选项只有在 psql 配置成使用输入行时才有效. \t 切换输出的列/字段名的信息头和行记数脚注(缺省是开). \T table_options 允许你在使用HTML 3.0 格式输出时声明放在表 table ... 中的标记选项.例如,border 将给你的表以边框.这必须和 H 后期命令一起使用. \x 切换扩展行格式.当打开时,每一行将在左边打印列/字段名而在右边打印列/字段值.这对于那些不能在一行输出的超长行是很有用的.HTML 行输出模式也支持这个标记. \w filename 将当前查询缓冲区输出到文件 filename. \z 生成一个带有正确 ACL(赋予/禁止 权限)的数据库中所有表的输出列表. ! [ command ] 回到一个独立的Unix shell或执行一个Unix 命令 command. \? 获得关于反斜杠 (“”) 命令的帮助. |
一般选项
1 2 3 4 5 6 7 8 9 10 11 | \c[onnect] [数据库名|- [用户名称]] 联接到新的数据库 (当前为 "test") \cd [目录名] 改变当前的工作目录 \copyright 显示 PostgreSQL 用法和发布信息 \encoding [编码] 显示或设置客户端编码 \h [名字] SQL 命令的语法帮助, 用 * 可以看所有命令的帮助 \q 退出 psql \set [名字 [值]] 设置内部变量, 如果没有参数就列出所有 \timing 查询计时开关切换 (目前是 关闭) \unset 名字 取消(删除)内部变量 ! [命令] 在 shell 里执行命令或者开始一个交互的 shell |
信息选项
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | \d [名字] 描述表, 索引, 序列, 或者视图 \d{t|i|s|v|S} [模式] (加 "+" 获取更多信息) 列出表/索引/序列/视图/系统表 \da [模式] 列出聚集函数 \db [模式] 列出表空间 (加 "+" 获取更多的信息) \dc [模式] 列出编码转换 \dC 列出类型转换 \dd [模式] 显示目标的注释 \dD [模式] 列出域 \df [模式] 列出函数 (加 "+" 获取更多的信息) \dg [模式] 列出组 \dn [模式] 列出模式 (加 "+" 获取更多的信息) \do [名字] 列出操作符 \dl 列出大对象, 和 lo_list 一样 \dp [模式] 列出表, 视图, 序列的访问权限 \dT [模式] 列出数据类型 (加 "+" 获取更多的信息) \du [模式] 列出用户 \l 列出所有数据库 (加 "+" 获取更多的信息) \z [模式] 列出表, 视图, 序列的访问权限 (和 dp 一样) |
其它
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 | 命令: ABORT 描述: 终止当前事务 语法: ABORT [ WORK | TRANSACTION ] 命令: ALTER DATABASE 描述: 改变一个数据库 语法: ALTER DATABASE 名字 SET 参数 { TO | = } { 值 | DEFAULT } ALTER DATABASE 名字 RESET 参数 ALTER DATABASE 名字 RENAME TO 新名字 ALTER DATABASE 名字 OWNER TO 新属主 命令: ALTER GROUP 描述: 改变一个用户组 语法: ALTER GROUP 组名称 ADD USER 用户名称 [, ... ] ALTER GROUP 组名称 DROP USER 用户名称 [, ... ] ALTER GROUP 组名称 RENAME TO 新名称 命令: ALTER INDEX 描述: 改变一个索引的定义 语法: ALTER INDEX 索引名称 动作 [, ... ] ALTER INDEX 索引旧名称 RENAME TO 索引新名称 动作为以下之一: OWNER TO 新属主 SET TABLESPACE indexspace_name 命令: ALTER SEQUENCE 描述: 改变一个序列生成器的定义 语法: ALTER SEQUENCE 名字 [ INCREMENT [ BY ] 递增 ] [MINVALUE 最小值 | NO MINVALUE ] [ MAXVALUE 最大值 | NO MAXVALUE ] [ RESTART [ WITH ] 开始 ] [ CACHE 缓存 ] [ [ NO ] CYCLE ] 命令: ALTER TABLE 描述: 改变一个表的定义 语法: ALTER TABLE [ ONLY ] 表名 [ ] action [, ... ] ALTER TABLE [ ONLY ] 表名 [ ] RENAME [ COLUMN ] 字段名 TO 新字段名 ALTER TABLE 表名 RENAME TO 新表名 action 为下面的一种: ADD [ COLUMN ] 字段名 类型 [ 字段约束 [ ... ] ] DROP [ COLUMN ] 字段名 [ RESTRICT | CASCADE ] ALTER [ COLUMN ] 字段名 TYPE 类型 [ USING 表达式 ] ALTER [ COLUMN ] 字段名 SET DEFAULT 表达式 ALTER [ COLUMN ] 字段名 DROP DEFAULT ALTER [ COLUMN ] 字段名 { SET | DROP } NOT NULL ALTER [ COLUMN ] 字段名 SET STATISTICS integer ALTER [ COLUMN ] 字段名 SET STORAGE { PLAIN | EXTERNAL | EXTENDED | MAIN } ADD 表约束 DROP CONSTRAINT 约束名字 [ RESTRICT | CASCADE ] CLUSTER ON 索引名称 SET WITHOUT CLUSTER SET WITHOUT OIDS OWNER TO 新属主 SET TABLESPACE 表空间名字 命令: ALTER TRIGGER 描述: 改变一个触发器的定义 语法: ALTER TRIGGER 名字 ON 表 RENAME TO 新名字 命令: ALTER USER 描述: 改变一个数据库用户 语法: ALTER USER name [ [ WITH ] option [ ... ] ] where option can be: CREATEDB | NOCREATEDB | CREATEUSER | NOCREATEUSER | [ ENCRYPTED | UNENCRYPTED ] PASSWORD 'password' | VALID UNTIL 'abstime' ALTER USER name RENAME TO newname ALTER USER name SET parameter { TO | = } { value | DEFAULT } 命令: COPY 描述: 在一个文件和一个表之间拷贝数据 语法: COPY 表名 [ ( 字段 [, ...] ) ] FROM { '文件名' | STDIN } [ [ WITH ] [ BINARY ] [ OIDS ] [ DELIMITER [ AS ] 'delimiter' ] [ NULL [ AS ] 'null string' ] [ CSV [ QUOTE [ AS ] 'quote' ] [ ESCAPE [ AS ] 'escape' ] [ FORCE NOT NULL column [, ...] ] COPY 表名 [ ( 字段 [, ...] ) ] TO { '文件名' | STDOUT } [ [ WITH ] [ BINARY ] [ OIDS ] [ DELIMITER [ AS ] 'delimiter' ] [ NULL [ AS ] 'null string' ] [ CSV [ QUOTE [ AS ] 'quote' ] [ ESCAPE [ AS ] 'escape' ] [ FORCE QUOTE column [, ...] ] 命令: CREATE TABLE 描述: 定义一个新的表 语法: CREATE [ [ GLOBAL | LOCAL ] { TEMPORARY | TEMP } ] TABLE table_name ( { column_name data_type [ DEFAULT default_expr ] [ column_constraint [ ... ] ] | table_constraint | LIKE parent_table [ { INCLUDING | EXCLUDING } DEFAULTS ] } [, ... ] ) [ INHERITS ( parent_table [, ... ] ) ] [ WITH OIDS | WITHOUT OIDS ] [ ON COMMIT { PRESERVE ROWS | DELETE ROWS | DROP } ] [ TABLESPACE tablespace ] where column_constraint is: [ CONSTRAINT constraint_name ] { NOT NULL | NULL | UNIQUE [ USING INDEX TABLESPACE tablespace ] | PRIMARY KEY [ USING INDEX TABLESPACE tablespace ] | CHECK (expression) | REFERENCES reftable [ ( refcolumn ) ] [ MATCH FULL | MATCH PARTIAL | MATCH SIMPLE ] [ ON DELETE action ] [ ON UPDATE action ] } [ DEFERRABLE | NOT DEFERRABLE ] [ INITIALLY DEFERRED | INITIALLY IMMEDIATE ] and table_constraint is: [ CONSTRAINT constraint_name ] { UNIQUE ( column_name [, ... ] ) [ USING INDEX TABLESPACE tablespace ] | PRIMARY KEY ( column_name [, ... ] ) [ USING INDEX TABLESPACE tablespace ] | CHECK ( expression ) | FOREIGN KEY ( column_name [, ... ] ) REFERENCES reftable [ ( refcolumn [, ... ] ) ] [ MATCH FULL | MATCH PARTIAL | MATCH SIMPLE ] [ ON DELETE action ] [ ON UPDATE action ] } [ DEFERRABLE | NOT DEFERRABLE ] [ INITIALLY DEFERRED | INITIALLY IMMEDIATE ] |
选项
-a--echo-all把所有非空输入行按照它们被读入的形式打印到标准输出(不适用于交互式行读取)。这等效于把变量
ECHO设置为all。-A--no-align切换到非对齐输出模式(默认输出模式是
对齐的)。这等效于\pset format unaligned。-b--echo-errors把失败的 SQL 命令打印到标准错误输出。这等效于把变量
ECHO设置为errors。-ccommandcommand指定psql执行一个给定的命令字符串
command。这个选项可以重复多次并且以任何顺序与-f选项组合在一起。当-c或者-f被指定时,psql不会从标准输入读取命令,直到它处理完序列中所有的-c和-f选项之后终止。command必须是一个服务器完全可解析的命令字符串(即不包含psql相关的特性)或者单个反斜线命令。因此不能在一个-c选项中混合SQL和psql元命令。要那样做,可以使用多个-c选项或者把字符串用管道输送到psql中,例如:psql -c '\x' -c 'SELECT * FROM foo;'或者echo '\x \\ SELECT * FROM foo;' | psql(\\是分隔符元命令)。每一个被传递给-c的SQL命令字符串会被当做一个单独的请求发送给服务器。因此,即便该字符串包括多个SQL命令,服务器也会把它当做一个事务来执行,除非在该字符串中有显式的BEGIN/COMMIT命令把它划分成多个事务(服务器如何处理多查询字符串的更多细节请参考第 52.2.2.1 节)。此外,psql只会打印出该字符串中最后一个SQL命令的结果。这和从文件中读取同一字符串或者把同一字符串传给psql的标准输出时的行为不同,因为那两种情况下psql会独立地发送每一个SQL命令。由于这种行为,把多于一个SQL命令放在-c字符串中通常会得到意料之外的结果。最好使用多个-c命令或者把多个命令输送给psql的标准输入,按照上文所说的使用echo或者通过一个 shell,例如:psql <<EOF \x SELECT * FROM foo; EOF--csv切换到CSV(逗号分隔值)输出模式。 这相当于
\pset format csv。-ddbnamedbname指定要连接的数据库的名称。这等效于指定
dbname为命令行上的第一个非选项参数。dbname可以是 连接字符串。 如果是这样,连接字符串参数将覆盖任何冲突的命令行选项。-e--echo-queries也把发送到服务器的所有 SQL 命令复制到标准输出。这等效于把变量
ECHO设置为queries。-E--echo-hidden回显
\d以及其他反斜线命令生成的实际查询。可以用它来学习psql的内部操作。这等效于把变量ECHO_HIDDEN设置为on。-ffilenamefilename从文件
filename而不是标准输入中读取命令。这个选项可以被重复多次,也可以以任意顺序与-c选项组合。当-c或者-f被指定时,psql不会从标准输入读取命令,直到它处理完序列中所有的-c和-f选项之后终止。除此以外,这个选项很大程度上等价于元命令\i。如果filename是-(连字符),那么会读取标准输入直到遇见一个 EOF 指示或者\q元命令。这种方式可以用把自多个文件的输入组合成一种交互式输入。不过注意在这种情况下不会使用 Readline(很像指定了-n的情况)。使用这个选项与psql <filename有细微的不同。通常,两种形式都可以做到我们所期望的,但是使用-f-Fseparatorseparator使用
separator作为非对齐输出的域分隔符。这等效于\pset fieldsep或者\f。-hhostnamehostname指定运行服务器的机器的主机名。如果这个值由一个斜线开始,它会被用作 Unix 域套接字的目录。
-H--html切换到HTML输出模式。这等效于
\pset format html或者\H命令。-l--list列出所有可用的数据库,然后退出。其他非连接选项会被忽略。这与元命令
\list类似。在使用这个选项时,psql将连接到数据库postgres,除非在命令行上提及一个不同的数据(选项-d或非选项参数,可能是通过一个服务项,但不能通过一个环境变量)。-Lfilenamefilename除了把所有查询输出写到普通输出目标之外,还写到文件
filename中。-n--no-readline不使用Readline做行编辑并且不使用命令历史。在剪切和粘贴时,关掉 Tab 展开会有所帮助。
-ofilenamefilename把所有查询输出放到文件
filename中。这等效于命令\o。-pportport指定服务器用于监听连接的 TCP 端口或者本地 Unix 域套接字文件扩展。默认是
PGPORT环境变量的值,如果没有设置,则默认为编译时指定的端口号(通常是5432)。-Passignmentassignment以
\pset的形式指定打印选项。注意,这里你必须用一个等号而不是空格来分隔名称和值。例如,要设置输出格式为LaTeX,应该写成-P format=latex。-q--quiet指定psql应该安静地工作。默认情况下,它会打印出欢迎消息以及多种输出。如果使用了这个选项,以上那些就都不会输出。在使用
-c选项时,配合这个选项很有用。这等效于设置变量QUIET为on。-Rseparatorseparator把
separator用作非对齐输出的记录分隔符。这等效于\pset recordsep命令。-s--single-step运行在单步模式中。这意味着在每个命令被发送给服务器之前都会提示用户一个可以取消执行的选项。使用这个选项可以调试脚本。
-S--single-line运行在单行模式中,其中新行会终止一个 SQL 命令,就像分号的作用一样。注意这种模式被提供给那些坚持使用它的用户,但是并不一定要使用它。特别地,如果在一行中混合了SQL和元命令,那对于没有经的用户来说,它们的执行顺序可能不总是那么清晰。
-t--tuples-only关闭打印列名和结果行计数页脚等。这等效于
\t或者\pset tuples_only命令。-Ttable_optionstable_options指定要替换HTML
table标签的选项。详见\pset tableattr。-Uusernameusername作为用户
username而不是默认用户连接到数据库(当然,你必须具有这样做的权限)。-vassignmentassignmentassignment执行一次变量赋值,和
\set元命令相似。注意你必须在命令行上用等号分隔名字和值(如果有)。要重置一个变量,去掉等号就行。要把一个变量置为空值,使用等号但是去掉值。这些赋值在命令行处理期间被完成,因此反映连接状态的变量将在稍后被覆盖。-V--version打印psql版本并且退出。
-w--no-password从不发出一个口令提示。如果服务器要求口令认证并且口令不能从其他来源(例如一个
.pgpass文件)获得,那儿连接尝试将失败。这个选项对于批处理任务和脚本有用,因为在其中没有一个用户来输入口令。注意这个选项将对整个会话保持设置,并且因此它会影响元命令\connect的使用,就像初始的连接尝试那样。-W--password强制psql在连接到一个数据库之前提示要求一个口令,即使口令不会被使用。如果服务器需要口令认证并且口令不能从其他来源获得,例如
.pgpass文件,psql 在任何情况下都会提示输入口令。 然而,psql 将浪费一次连接尝试来发现服务器想要一个口令。在某些情况下值得用-W来避免额外的连接尝试。注意这个选项将对整个会话保持设置,并且因此它会影响元命令\connect的使用,就像初始的连接尝试那样。-x--expanded打开扩展表格式模式。这等效于
\x或者\pset expanded命令。-X,--no-psqlrc不读取启动文件(要么是系统范围的
psqlrc文件,要么是用户的~/.psqlrc文件)。-z--field-separator-zero设置非对齐输出的域分隔符为零字节。这等效于
\pset fieldsep_zero。-0--record-separator-zero设置非对齐输出的记录分隔符为零字节。例如,这对与
xargs -0配合有关。这等效于\pset recordsep_zero。-1--single-transaction这个选项只能被用于与一个或者多个
-c以及/或者-f选项组合。它会让psql在第一个上述选项之前发出一条BEGIN命令并且在最后一个上述选项之后发出一条COMMIT命令,这样就把所有的命令都包裹在一个事务中。这个选项可以保证要么所有的命令都成功地完成,要么不应用任何更改。如果命令本身包含BEGIN、COMMIT或者ROLLBACK,这个选项将不会得到想要的效果。还有,如果当个命令不能在一个事务块中执行,指定这个选项将导致整个事务失败。-?--help[=topic]显示有关psql的帮助并且退出。可选的
topic参数(默认为options)选择要解释哪一部分的psql:commands描述psql的反斜线命令;options描述可以被传递给psql的命令行选项;而variables则显示有关psql配置变量的帮助。
退出状态
如果psql正常完成,它会向 shell 返回 0。如果它自身发生一个致命错误(例如内存用完、找不到文件),它会返回 1。如果到服务器的连接出问题并且事务不是交互式的,它会返回 2。如果在脚本中发生错误,它会返回 3 并且变量ON_ERROR_STOP会被设置。
用法
连接到数据库
psql是一个常规PostgreSQL客户端应用。为了连接到数据库,你需要知道你的目标数据库的名称、主机名和该服务器的端口号,还有要作为哪个用户名连接。可以通过命令行选项告知psql这些参数,分别是-d、-h、-p以及-U。如果发现一个参数不属于任何选项,它将被解释为数据库名称(如果已经给出数据库名称,就解释为用户名)。并非所有这些选项都是必需的,它们都有可用的默认值。如果省略主机名,psql将通过一个 Unix 域套接字连接到本地主机上的服务器,或者通过 TCP/IP 连接到没有 Unix 域套接字的主机上的localhost。默认端口号则在编译时决定。由于数据库服务器使用相同的默认值,大多数情况下你将不必指定端口。默认的用户名是你的操作系统用户名,它也会是默认的数据库名。注意你不一定能连接到任意用户名下的任何数据库。你的数据库管理员应该已经告知过你有关你的访问权限。
当默认值不是很符合实际时,可以把环境变量PGDATABASE、PGHOST、PGPORT以及PGUSER设置为适当的值,这样也能节省一些敲打键盘的工作(额外的环境变量可见第 33.14 节)。用一个~/.pgpass文件来避免定期输入密码也很方便。详见第 33.15 节。
另一种指定连接参数的方法是用一个conninfo字符串或者一个URI,它可以被用来替代数据库名。这种机制可以让我们对连接具有很广的控制权。例如:
1 2 | $ psql "service=myservice sslmode=require" $ psql postgresql://dbmaster:5433/mydb?sslmode=require |
用这种方式,你也可以把LDAP用于第 33.17 节中描述的连接参数查找。可用连接选项的更多信息请见第 33.1.2 节。
如果由于任何原因(例如权限不足、服务器没有在目标主机上运行等)导致连接无法建立,psql将返回一个错误并且终止。
如果标准输入和标准输出都是一个终端,那么psql会把客户端编码设置成“auto”,这会使psql从区域设置(Unix 系统上的LC_CTYPE环境变量)中检测合适的客户端编码。如果这样不起作用,可以使用环境变量PGCLIENTENCODING覆盖客户端编码。
输入 SQL 命令
在正常操作时,psql会提供一个提示符,该提示符是psql当前连接到的数据库名称后面跟上字符串=>。例如:
1 2 3 4 5 | $ psql testdb psql (13.1) Type "help" for help. testdb=> |
在提示符下,用户可以键入SQL命令。正常情况下,当碰到一个表示命令终结的分号时,输入的行会被发送给服务器。一行的结束并不表示命令的完结。因此,为了清晰,可以把命令散布在多个行上。如果命令被发送并且执行而不产生错误,该命令的结果将会显示在屏幕上。
如果不可信用户对还没有采用安全方案使用模式的一个而数据库拥有访问,通过从search_path移除公共可写的方案来开始你的会话。人们可以在连接字符串中加入options=-csearch_path=或者在其他SQL命令之前发出SELECT pg_catalog.set_config('search_path', '', false)。这种考虑并非专门针对psql,它适用于每一种执行任意SQL命令的接口。
只要执行命令,psql还会测试LISTEN和NOTIFY产生的异步通知。
虽然 C 风格的注释块会被传给服务器处理并且移除,psql会自己移除掉 SQL 标准的注释。
元命令
你输入到psql中的任何以未加引用的反斜线开始的东西都是一个psql元命令,它们由psql自行处理。这些命令让psql对管理和编写脚本更有用。元命令常常被称作斜线或者反斜线命令。
psql命令的格式是用反斜线后面直接跟上一个命令动词,然后是一些参数。参数与命令动词和其他参数之间用任意多个空白字符分隔开。
要在一个参数中包括空白,可以将它加上单引号。要在一个参数中包括一个单引号,则需要在文本中写上两个单引号。任何包含在单引号中的东西都服从与 C 语言中\n(新行)、\t(制表符)、\b(退格)、\r(回车)、\f(换页)、\digits(10 进制)以及\xdigits(16 进制)类似的替换规则。单引号内文本中的其他任何字符(不管它是什么)前面的反斜线都没有实际意义(会被忽略)。
如果在一个参数中出现一个未加引号的冒号(:)后面跟着一个psql变量名,它会被该变量的值替换, 如下面的SQL Interpolation所述。在其中描述的形式:'variable_name'和:"variable_name"也有同样的效果。:{?variable_name}语法允许测试一个变量是否被定义。它会被TRUE或FALSE替换。用一个反斜线转义该冒号可以防止它被替换。
在一个参数中,封闭在反引号(`形式会打印一个错误消息并且在这类字符出现在值中时不替换该变量值。)中的文本会被当做一个传递给shell的命令行。该命令的输出(移除任何拖尾的新行)会替换反引号文本。在封闭在反引号的文本中,不会有特别的引号或者其他处理发生,:variable_name的出现除外,其中variable_name是一个会被其值替换的psql变量名。此外,Also, appearances of :'variable_name'的出现会被替换为该变量的值,而值会被适当地加以引用以变成一个单一shell命令参数(后一种形式几乎总是优先,除非你非常确定变量中有什么)。因为回车和换行字符在所有的平台上都不能被安全地引用,:'variable_name'
有些命令把SQL标识符(例如一个表名)当作参数。这些参数遵循SQL的语法规则:无引号的字母被强制变为小写,而双引号(")可以保护字母避免大小写转换并且允许在标识符中包含空白。 在双引号内,成对的双引号会被缩减为结果名称中的单个双引号。例如,FOO"BAR"BAZ会被解释成fooBARbaz,而"A weird"" name"会变成A weird" name。
对参数的解析会在行尾或者碰到另一个未加引号的反斜线时停止。一个未加引号的反斜线被当做新元命令的开始。特殊的序列\\(两个反斜线)表示参数结束并且应继续解析SQL命令(如果还有)。使用这种方法,SQL命令和psql命令可以被自由地混合在一行中。但是无论在何种情况中,元命令的参数都无法跨越一行。
很多元命令作用在当前查询缓冲区上。这就是一个缓冲区而已,它保存任何已经被键入但是还没有发送到服务器执行的SQL命令文本。这将包括之前输入的行以及在该元命令同一行上出现在前面的任何文本。
可以使用下列元命令:
\a如果当前的表输出格式是非对齐的,则切换成对齐格式。如果不是非对齐格式,则设置成非对齐格式。保留这个命令是为了向后兼容性。更一般的方案请见
\pset。\cor\connect [ -reuse-previous=on|off] [dbname[username] [host] [port] |conninfo]与一台PostgreSQL服务器建立一个新连接。可以使用位置语法(数据库名称、用户、主机和端口中的一个或多个)指定要使用的连接参数,或者使用第 33.1.1 节中详细介绍的
conninfo连接串。如果没有给出参数,则使用与以前相同的参数建立新连接。把dbname、username、host或者port中的任何一个指定为-等价于省略该参数。新连接可以重用之前连接的连接参数;不仅是数据库名称、用户、主机和端口,还有其他设置,例如sslmode。默认情况下,参数会在位置语法中重复使用,但在给出conninfo字符串时不会。传递-reuse-previous=on或-reuse-previous=off的第一个参数会覆盖该默认值。如果重复使用参数,则任何未明确指定为位置参数或在conninfo字符串中的参数都将从现有连接的参数中获取。一个例外是,如果host设置使用位置语法从其先前的值更改,则现有连接参数中存在的任何hostaddr设置都将被删除。当命令既不指定也不重用特定参数时,将使用 libpq 默认值。如果新连接成功地被建立,之前的连接会被关闭。如果连接尝试失败(错误的用户名、访问被拒绝等),在psql处于交互模式的情况下会保留之前的连接。但是当执行一个非交互式脚本时出现连接尝试失败,处理将被立即停止,并且报出一个错误。这种区别一方面可以帮助用户发现打字错误,另一方面也可以作为一种安全机制防止脚本在错误的数据库上执行动作。例子:=> \c mydb myuser host.dom 6432 => \c service=foo => \c "host=localhost port=5432 dbname=mydb connect_timeout=10 sslmode=disable" => \c -reuse-previous=on sslmode=require -- changes only sslmode => \c postgresql://tom@localhost/mydb?application_name=myapp\C [title]设置查询结果的任何表的标题,或者重置这类标题。这个命令等效于
\pset titletitle``(这个命令的名称来自于“caption”,因为它之前只被用来在HTML表格中设置标题)。\cd [directory]把当前工作目录改为
directory。如果不带参数,则切换到当前用户的主目录。提示要打印当前的工作目录,可以使用\! pwd。\conninfo输出有关当前数据库连接的信息。
\copy {table[ (column_list) ] } from {'filename'| program'command'| stdin | pstdin } [ [ with ] (option[, ...] ) ] [ wherecondition]\copy {table[ (column_list) ] | (query) } to {'filename'| program'command'| stdout | pstdout } [ [ with ] (option[, ...] ) ]执行一次前端拷贝。这个操作会运行一个SQL COPY命令,不过不是服务器读取或者写入指定的文件,而是由psql读写文件并且把数据从本地文件系统导向服务器。这意味着文件的可访问性和权限是本地用户的而非服务器上的,并且不需要 SQL 超级用户特权。当
program被指定时,command被psql执行并且传给command的数据或者从command传出的数据会在服务器和客户端之间流动。同样地,执行特权是本地用户的而非服务器上的,并且不需要 SQL 超级用户特权。对于\copy ... from stdin,数据行从发出该命令的同一来源读取,一直到读到\.或者数据流到达EOF。这个选项可以用来填充内嵌在一个 SQL 脚本文件中的表。对于\copy ... to stdout,输出被发送到与psql命令输出相同的位置,并且COPYcount命令的状态不会被打印(因为它会被一个数据行搞乱)。要读/写psql的标准输入或者输出而不管当前命令的来源或者\o选项,可以写from pstdin或者to pstdout。这个命令的语法和SQL [COPY](http://postgres.cn/docs/13/sql-copy.html)命令类似。所有除开数据来源/目的地的选项都和[COPY](http://postgres.cn/docs/13/sql-copy.html)指定的一样。因此,\copy元命令由特殊的解析规则。与大部分其他元命令不同,该行的所有剩余部分总是会被当做\copy的参数,并且在参数中不会执行变量篡改以及反引号展开。提示获得与\copy ... to相同结果的另一种方法是使用SQLCOPY ... TO STDOUT命令并使用\gfilename或\ g |program终止它。 与\copy不同,此方法允许命令跨越多行; 此外,可以使用变量插值和反引号扩展。提示这些操作不如带有文件或程序数据源或目标的SQLCOPY\copyright显示PostgreSQL的版权以及发布条款。
\crosstabview [colV[colH[colD[sortcolH] ] ] ]执行当前的查询缓冲区(像
\g那样)并且在一个交叉表格子中显示结果。该查询必须返回至少三列。由colV标识的输出列会成为垂直页眉并且colH所标识的输出列会成为水平页眉。colD标识显示在格子中的输出列。sortcolH标识用于水平页眉的可选的排序列。每一个列说明可以是一个列编号(从 1 开始)或者一个列名。常用的 SQL 大小写折叠和引用规则适用于列名。如果省略,colV被当做列 1 并且colH被当做列 2。colH必须和colV不同。如果没有指定colD,那么在查询结果中必须正好有三列,并且colV和colH之外的那一列会被当做colD。垂直页眉显示为最左边的列,它包含列colV中找到的值,值的顺序和查询结果中的顺序相同,但是重复值会被移除。水平页眉显示为第一行,它包含列colH中找到的值,其中的重复值被移除。默认情况下,这些值会以查询结果中相同的顺序出现。但是如果给出了可选的sortcolH参数,它标识一个值必须为整数编号的列,并且来自colH的值将会根据相应的sortcolH值排序后出现在水平页眉中。在交叉表格子中,对于colH的每一个可区分的值x以及colV的每一个可区分的值y,位于交叉点(x,y)的单元包含colH值为x且colV值为y的查询结果行中colD列的值。如果没有这样的行,则该单元为空。如果有多个这样的行,则会报告一个错误。\d[S+] [pattern]对于每一个匹配
pattern的关系(表、视图、物化视图、索引、序列或者外部表)或者组合类型,显示所有的列、它们的类型、表空间(如果非默认表空间)以及任何诸如NOT NULL或者默认值的特殊属性。相关的索引、约束、规则以及触发器也会被显示。对于外部表,还会显示相关的外部服务器(下文的Patterns中定义了“匹配模式”)。对于某些类型的关系,\d会为每一列显示额外的信息:对于序列会显示列值,对于索引显示被索引的表达式,对于外部表显示外部数据包装器选项。命令形式\d+是一样的,不过会显示更多信息:与该表的列相关的任何注释,表中是否存在 OID,如果关系是视图则显示视图定义,非默认的replica identity设置。默认情况下只会显示用户创建的对象,提供一个模式或者S修饰符可以把系统对象包括在内。注意如果使用\d但不带有pattern参数,它等价于\dtvmsE,后者将显示所有可见的表、视图、物化视图、序列和外部表的列表。这纯粹是一种便利措施。\da[S] [pattern]列出聚集函数,以及它们的返回类型和它们所操作的数据类型。如果指定了
pattern,只显示名称匹配该模式的聚集。默认情况下只会显示用户创建的对象,提供一个模式或者S修饰符可以把系统对象包括在内。\dA[+] [pattern]列出访问方法。如果指定了
pattern,只显示名称匹配该模式的访问方法。如果在命令名称后面追加+,则与访问方法相关的处理器函数和描述也会和访问方法本身一起被列出。\dAc[+] [access-method-pattern[input-type-pattern]]列出运算符类(请参阅 第 37.16.1 节)。 如果指定了
access-method-pattern,则仅列出与名称与该模式匹配的访问方法关联的运算符类。 如果指定了input-type-pattern,则仅列出与名称与该模式匹配的输入类型关联的运算符类。 如果将+附加到命令名称,则会列出每个运算符类别及其关联的运算符系列和所有者。\dAf[+] [access-method-pattern[input-type-pattern]]列出运算符系列(请参阅 第 37.16.5 节)。 如果指定了
access-method-pattern,则仅列出与名称与该模式匹配的访问方法关联的运算符系列。 如果指定了input-type-pattern,则仅列出与名称与该模式匹配的输入类型关联的运算符系列。 如果将+附加到命令名称,则会列出每个运算符系列及其所有者。\dAo[+] [access-method-pattern[operator-family-pattern]]列出与运算符系列关联的运算符(请参阅 第 37.16.2 节)。 如果指定了
access-method-pattern,则仅列出与名称与该模式匹配的访问方法关联的运算符系列的成员。 如果指定了operator-family-pattern,则仅列出名称与该模式匹配的运算符系列的成员。 如果将+附加到命令名称,则会列出每个运算符及其排序运算符系列(如果它是排序运算符)。\dAp[+] [access-method-pattern[operator-family-pattern]]列出与运算符系列相关的支持函数(请参阅 第 37.16.3 节)。 如果指定了
access-method-pattern,则仅列出与名称与该模式匹配的访问方法关联的运算符系列的函数。 如果指定了operator-family-pattern,则仅列出名称与该模式匹配的运算符系列的函数。 如果将+附加到命令名称,则会详细显示函数及其实际参数列表。\db[+] [pattern]列出表空间。如果指定了
pattern,只显示名称匹配该模式的表空间。如果在命令名称后面追加+,则与表空间相关的选项、磁盘上的尺寸、权限以及描述也会和表空间本身一起被列出。\dc[S+] [pattern]列出字符集编码之间的转换。如果指定了
pattern,只列出名称匹配该模式的转换。默认情况下只会显示用户创建的对象,提供一个模式或者S修饰符可以把系统对象包括在内。如果在命令名称后面追加+,则每一个对象相关的描述也会被列出。\dC[+] [pattern]列出类型转换。如果指定了
pattern,只列出源类型和目标类型匹配该模式的转换。如果在命令名称后面追加+,则每一个对象相关的描述也会被列出。\dd[S] [pattern]显示
约束、操作符类、操作符族、规则以及触发器类型对象的描述。所有其他注释可以通过那些对象类型相应的反斜线命令查看。\dd显示匹配pattern的对象的描述,如果没有给出参数则显示合适类型的可见对象的描述。但是在任一种情况下都只列出具有描述的对象。默认情况下只会显示用户创建的对象,提供一个模式或者S修饰符可以把系统对象包括在内。对象的描述可以用SQL命令COMMENT创建。\dD[S+] [pattern]列出域。如果指定了
pattern,只有名称匹配该模式的域会被显示。默认情况下,只有用户创建的对象会被显示,可以提供一个模式或者S修饰符以包括系统对象。如果+被追加到命令名称上,每一个被列出的对象会带有其相关的权限和描述。\ddp [pattern]列出默认的访问特权设置。对那些默认特权设置已经被改变得与内建默认值不同的角色(以及模式,如果适用),为每一个角色(以及模式)显示一项。如果指定了
pattern,只列出角色名称或者模式名称匹配该模式的项。ALTER DEFAULT PRIVILEGES命令被用来设置默认访问特权。在第 5.7 节中解释了显示的特权的含义。\dE[S+] [pattern]\di[S+] [pattern]\dm[S+] [pattern]\ds[S+] [pattern]\dt[S+] [pattern]\dv[S+] [pattern]在这一组命令中,字母
E、i、m、s、t和v分别对应着外部表、索引、物化视图、序列、表和视图。你可以以任何顺序指定这些字母中的任意一个或者多个,这样可以得到这些类型的对象的列表。例如,\dti会列出表和索引。如果在命令名称后面追加+,则会列出每个对象及其持久性状态(永久、临时或未记录)、磁盘上的物理大小以及相关的描述(如果有)。如果指定了pattern,只列出名称匹配该模式的对象。默认情况下只会显示用户创建的对象,提供一个模式或者S修饰符可以把系统对象包括在内。\des[+] [pattern]列出外部服务器(助记:“外部服务器”)。如果指定了
pattern,只列出名称匹配该模式的那些服务器。如果使用了\des+形式,将显示每个服务器的完整描述,包括该服务器的 访问特权、类型、版本、选项和描述。\det[+] [pattern]列出外部表(助记:“外部表”)。如果指定了
pattern,只列出表名称或者模式名称匹配该模式的项。如果使用了\det+选项,一般选项和外部表描述也会被显示。\deu[+] [pattern]列出用户映射(助记:“外部用户”)。如果指定了
pattern,只列出用户名匹配该模式的那些映射。如果使用了\deu+形式,有关每个映射的额外信息也会被显示。小心\deu+可能也会显示远程用户的用户名和口令,所以要小心不要把它们泄露出去。\dew[+] [pattern]列出外部数据包装器(助记:“外部包装器”)。如果指定了
pattern,只列出名称匹配该模式的那些外部数据包装器。如果使用了\dew+形式,外部数据包装器的访问特权、选项和描述也会被显示。\df[anptwS+] [pattern]列出函数,以及它们的结果数据类型、参数数据类型和函数类型,函数类型被分为“agg”(聚集)、“normal”、“procedure”、“trigger”以及“window”。如果要只显示指定类型的函数,可以在该命令上增加相应的字母
a、n、p、t或者w。如果指定了pattern,只显示名称匹配该模式的函数。默认情况下只会显示用户创建的对象,提供一个模式或者S修饰符可以把系统对象包括在内。如果使用了\df+形式,则有关每个函数的额外信息也会被显示,包括易失性、并行安全性、拥有者、安全性分类、访问特权、语言、源代码和描述。提示如果要查找接收指定数据类型参数或者返回指定类型值的函数,可以使用分页器的搜索能力来滚动显示\df输出。\dF[+] [pattern]列出文本搜索配置。如果指定了
pattern,只显示名称匹配该模式的配置。如果使用了\dF+形式,每种配置的完整描述也会被显示,包括底层的文本搜索解析器和用于每一种解析器记号类型的字典列表。\dFd[+] [pattern]列出文本搜索字典。如果指定了
pattern,只显示名称匹配该模式的字典。如果使用了\dFd+形式,有关每一种选中的字典的额外信息也会被显示,包括底层的文本搜索模板和选项值。\dFp[+] [pattern]列出文本搜索解析器。如果指定了
pattern,只显示名称匹配该模式的解析器。如果使用了\dFp+形式,每一种解析器的完整描述也会被显示,包括底层的函数和可识别的记号类型列表。\dFt[+] [pattern]列出文本搜索模板。如果指定了
pattern,只显示名称匹配该模式的模板。如果使用了\dFt+形式,每一种模板有关的额外信息也会被显示,包括底层的函数名称。\dg[S+] [pattern]列出数据库角色(因为“用户”和“组”的概念已经被统一成“角色”,这个命令现在等价于
\du)。默认情况下只会显示用户创建的角色,提供一个模式或者S修饰符可以把系统角色包括在内。如果指定了pattern,只列出名称匹配该模式的那些角色。如果使用了\dg+形式,有关每种角色的额外信息也将被显示,当前这种形式会为角色增加显示注释。\dl这是
\lo_list的一个别名,它显示大对象的列表。\dL[S+] [pattern]列出过程语言。如果指定了
pattern,只列出名称匹配该模式的语言。默认情况下只会显示用户创建的语言,提供一个模式或者S修饰符可以把系统对象包括在内。如果向命令名称追加+,则每一种语言会和它的调用处理器、验证器、访问特权以及它是否为系统对象一起列出。\dn[S+] [pattern]列出模式(名字空间)。如果指定了
pattern,只列出名称匹配该模式的模式。默认情况下只会显示用户创建的对象,提供一个模式或者S修饰符可以把系统对象包括在内。如果向命令名称追加+,每个对象会与它相关的权限及描述(如果有)一起被列出。\do[S+] [pattern]列出操作符及其操作数和结果类型。如果指定了
pattern,只列出名称匹配该模式的操作符。默认情况下只会显示用户创建的对象,提供一个模式或者S修饰符可以把系统对象包括在内。如果向命令名称追加+,有关每个操作符的额外信息也将被显示,当前只包括底层函数的名称。\dO[S+] [pattern]列出排序规则。如果指定了
pattern,只列出名称匹配该模式的排序规则。默认情况下只会显示用户创建的对象,提供一个模式或者S修饰符可以把系统对象包括在内。如果向命令名称追加+,每个排序规则将和它相关的描述(如果有)一起被列出。注意只有可用于当前数据库编码的排序规则会被显示,因此在同一个安装下的不同数据库中执行此命令可能会得到不同的结果。\dp [pattern]列出表、视图和序列,包括与它们相关的访问特权。如果指定了
pattern,只列出名称匹配该模式的表、视图以及序列。GRANT和REVOKE命令被用来设置访问特权。所显示的特权的含义在第 5.7 节中有介绍。\dP[itn+] [pattern]列出分区关系。如果指定了
pattern,则仅列出名称与模式匹配的条目。 修改符t(表)和i(索引)可以追加到命令中,筛选要列出的关系类型。默认会列出分区表和索引。如果用了修饰符n(“nested”)或指定了模式,则包括非根分区关系,并显示每个分区关系的父级的列。如果+被附加到命令名中,那么还会显示每个关系分区的大小总和,以及关系的描述。 如果n与_相结合,将显示两种大小:一种包含直接连接的叶分区的总大小,另一种显示所有分区的总大小,包括间接附加的子分区。\drds [role-pattern[database-pattern] ]列出已定义的配置设置。这些设置可以是针对角色的、针对数据库的或者同时针对两者的。
role-pattern和database-pattern分别被用来选择要列出的角色和数据库。如果省略它们或者指定了``,则会列出所有设置,分别会包括针对角色和针对数据库的设置。ALTER ROLE以及ALTER DATABASE命令可以用来定义一个角色以及一个数据库的配置设置。\dRp[+] [pattern]列出复制的publication。如果指定有
pattern,只有那些名称匹配该模式的publication会被列出。如果+被追加到命令的名称上,与每个publication相关的表也会被显示。\dRs[+] [pattern]列出复制的订阅。如果指定有
pattern,只有那些名字匹配该模式的订阅才会被列出。如果+被追加到命令的名称上,订阅的额外属性会被显示。\dT[S+] [pattern]列出数据类型。如果指定了
pattern,只列出名称匹配该模式的类型。如果向命令名称追加+,每一种类型、其内部名称和尺寸、允许的值(如果是一种enum类型)以及相关权限会被一同列出。默认情况下只会显示用户创建的对象,提供一个模式或者S修饰符可以把系统对象包括在内。\du[S+] [pattern]列出数据库角色(因为“用户”和“组”的概念已经被统一成“角色”,这个命令现在等价于
\dg)。默认情况下只会显示用户创建的角色,提供一个模式或者S修饰符可以把系统角色包括在内。如果指定了pattern,只列出名称匹配该模式的那些角色。如果使用了\du+形式,有关每一种角色的额外信息也会被显示,当前只会多显示角色的注释。\dx[+] [pattern]列出已安装的扩展。如果指定了
pattern,只列出名称匹配该模式的那些扩展。如果使用了\dx+形式,所有属于每个匹配扩展的对象会被列出。\dy[+] [pattern]列出事件触发器。如果指定了
pattern,只列出名称匹配该模式的事件触发器。如果在命令名称后面加上+,还会为每个列出的对象显示其相关的描述。\e或\edit[filename] [line_number]如果指定了
filename,则它是被编辑的文件,在编辑器退出后,该文件的内容会被拷贝到当前查询缓冲区中。如果没有给定filename,当前查询缓冲区会被拷贝到一个临时文件中,并且接着以相同的方式编辑。或者,如果当前查询缓冲区为空,则最近被执行的查询会被拷贝到一个临时文件并且以同样的方式编辑。然后会根据psql的一般规则重新解析查询缓冲区的新内容,把整个缓冲区当作一个单一行来处理。任何完整的查询都会立即执行; 也就是说,如果查询缓冲区包含分号或以分号结尾,则执行该点之前的所有内容并将其从查询缓冲区中删除。查询缓冲区中剩余的内容将重新显示。输入分号或者\g会把它发送出去,输入\r会通过清除查询缓冲区来取消它。把缓冲区当作单一行主要会影响元命令:缓冲区中在一个元命令之后的任何东西都将被当作该元命令的参数,即便元命令之后的内容跨越多行也是如此。(因此不能以这种方式来制作使用元命令的脚本。应该使用\i。)如果指定了一个行号,psql将会把游标(注意不是服务器端的游标)定位到文件或者查询缓冲区的指定行上。注意如果给出了一个全是数字的参数,psql就会假定它是行号而不是文件名。提示有关如何配置和自定义编辑器的信息,请参见下面的Environment。\echotext[ ... ]将经过计算的参数打印到标准输出,以空格分隔,后跟换行符。这可以用来在脚本的输出中间混入信息,例如:
=> *\echodate* Tue Oct 26 21:40:57 CEST 1999如果第一个参数是一个没有加引号的-n,则不会加上最后的新行(第一个参数也不会)。提示如果使用\o命令来重定向查询的输出,你可能希望使用\qecho来取代这个命令。另请参见\warn。\ef [function_description[line_number] ]这个命令会以一个
CREATE OR REPLACE FUNCTION或CREATE OR REPLACE PROCEDURE命令的形式取出并且编辑指定函数或过程的定义。编辑的方式与\edit完全相同。在编辑器退出后,在编辑器退出后,则会立即执行更新的命令。否则重新显示;可以键入分号或者\g把它发出,也可以用\r取消之。目标函数可以单独用名称或者用名称和参数(例如foo(integer, text))来指定。如果有多于一个函数具有同样的名称,则必须给出参数的类型。如果没有指定函数,将会给出一个空白的CREATE FUNCTION模板来编辑。如果指定了一个行号,psql将把游标定位在该函数体的指定行上(注意函数体通常不是开始于文件的第一行)。和大部分其他元命令不同,该行的整个剩余部分总是会被当作\ef的参数,并且在参数中不会执行变量篡改以及反引号展开。提示有关如何配置和自定义编辑器可见下面的Environment。\encoding [encoding]设置客户端字符集编码。如果没有参数,这个命令会显示当前的编码。
\errverbose以最详细的程度重复最近的服务器错误消息,就好像
VERBOSITY被设置为verbose且SHOW_CONTEXT被设置为always。\ev [view_name[line_number] ]这个命令会以一个
CREATE OR REPLACE VIEW的形式取出并且编辑指定函数的定义。编辑的方式与\edit完全相同。在编辑器退出后,如果向其添加分号,则会立即执行更新的命令。否则重新显示;可以键入分号或者\g把它发出,也可以用\r取消之。如果没有指定函数,将会给出一个空白的CREATE VIEW模板来编辑。如果指定了一个行号,psql将把游标定位在该视图定义的指定行上。和大部分其他元命令不同,该行的整个剩余部分总是会被当作\ev的参数,并且在参数中不会执行变量篡改以及反引号展开。\f [string]设置用于非对齐查询输出的域分隔符。默认值是竖线(
|)。它等效于\pset fieldsep。\g [ (option=value[...]) ] [filename]\g [ (option=value[...]) ] [ |command]把当前查询缓冲区发送给服务器执行。如果括号出现在
\g之后,它们将包围以空格分隔的option=value格式选项子句列表,其解释方式与\psetoptionvalue命令相同,但仅在此查询期间生效。 在此列表中,=符号周围不允许有空格,但选项子句之间需要空格。 如果省略=value,命名的option的更改方式与\psetoption相同,没有明确的value。如果给定了filename或|command参数,则查询的输出将写入命名文件或通过管道传输到给定的 shell 命令,而不是像往常一样显示它。 仅当查询成功返回零个或多个元组时才会写入文件或命令,而不是在查询失败或者是不返回数据的 SQL 命令时写入。如果当前查询缓冲区为空,则重新执行最近一次被发送的查询。除了这种行为之外,没有参数的\g实际上等效于一个分号。对于参数,\g提供了一个替代\o命令的“一次性”,另外还允许对通常由\pset设置的输出格式选项进行一次性调整。当最后一个参数以|开始时,则该行的所有剩余部分总是会被当做要执行的command,并且在参数中不会执行变量篡改以及反引号展开。该行的剩余部分会被简单地按字面传给shell。\gdesc显示当前查询缓冲区的结果的描述(即列名和数据类型)。查询不会被实际执行,不过,如果它含有某种类型的语法错误,该错误将被以通常的方式报出。如果当前查询缓冲区为空,则会描述最近被发送的查询。
pg11中在psql中新增了
\gdesc元命令,\gdesc用于显示最近一个查询的列名和列的数据类型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 | postgres=# SELECT COUNT(*) AS num_settings FROM pg_settings ; num_settings -------------- 290 (1 row) postgres=# \gdesc Column | Type --------------+-------- num_settings | bigint (1 row) postgres=# select version(); version ---------------------------------------------------------------------------------------------------------- PostgreSQL 11.10 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-39), 64-bit (1 row) postgres=# postgres=# select * from pg_database; datname | datdba | encoding | datcollate | datctype | datistemplate | datallowconn | datconnlimit | datlastsysoid | datfrozenxid | datminmxid | dattablespace | datacl -----------+--------+----------+-------------+-------------+---------------+--------------+--------------+---------------+--------------+------------+---------------+------------------------------- postgres | 10 | 6 | en_US.UTF-8 | en_US.UTF-8 | f | t | -1 | 13880 | 561 | 1 | 1663 | template1 | 10 | 6 | en_US.UTF-8 | en_US.UTF-8 | t | t | -1 | 13880 | 561 | 1 | 1663 | {=c/pg1110,pg1110=CTc/pg1110} template0 | 10 | 6 | en_US.UTF-8 | en_US.UTF-8 | t | f | -1 | 13880 | 561 | 1 | 1663 | {=c/pg1110,pg1110=CTc/pg1110} (3 rows) postgres=# \gdesc Column | Type ---------------+----------- datname | name datdba | oid encoding | integer datcollate | name datctype | name datistemplate | boolean datallowconn | boolean datconnlimit | integer datlastsysoid | oid datfrozenxid | xid datminmxid | xid dattablespace | oid datacl | aclitem[] (13 rows) postgres=# |
\gexec把当前查询缓冲区发送到服务器,然后该查询输出(如果有)中的每一行的每一列都当作一个要被执行的 SQL 语句。例如,要在
my_table的每一列上都创建一个索引:=> *SELECT format('create index on my_table(%I)', attname)* -> *FROM pg_attribute* -> *WHERE attrelid = 'my_table'::regclass AND attnum > 0* -> *ORDER BY attnum* -> *\gexec* CREATE INDEX CREATE INDEX CREATE INDEX CREATE INDEX产生的查询会按照其所在行被返回的顺序执行,如果有多个列,则同一行中按照从左至右的顺序执行。NULL 域会被忽略。产生的查询会被原样发送给服务器处理,因此它们即不能是psql元命令,也不能包含psql变量引用。如果其中任何一个查询失败,剩余查询的执行将会继续,除非设置了ON_ERROR_STOP。每个查询的执行都遵照ECHO的处理(在使用\gexec时,通常建议设置ECHO为all或者queries)。查询日志、单步模式、计时以及其他查询执行特性也适用于每一个生成的查询。如果当前查询缓冲区为空,则会重新执行最近被发送的查询。\gset [prefix]把当前查询输入缓冲区发送给服务器并且将查询的输出存储在psql变量中(参见下面的Variables)。被执行的查询必须只返回一行。该行的每一列会被存储到一个单独的变量中,变量和该列的名字一样。例如:
=> *SELECT 'hello' AS var1, 10 AS var2* -> *\gset* => *\echo :var1 :var2* hello 10如果指定了一个prefix,那么该字符串会被追加在该查询的输出列名称之前用来创建要使用的变量名:=> *SELECT 'hello' AS var1, 10 AS var2MARKDOWN_HASH81d8614ecf0542347798f0dae6237b54MARKDOWNHASH\gset result* => *\echo :result_var1 :result_var2* hello 10如果一个列的结果为 NULL,那么对应的变量会被重置而不是被设置。如果查询失败或者没有返回一行,则不会有任何变量被更改。如果当前查询缓冲区为空,则重新执行最近被发送的查询。\gx [ (option=value[...]) ] [filename]\gx [ (option=value[...]) ] [ |command]\gx等效于\g,\gx等价于\g,除了它强制此查询的扩展输出模式,就好像expanded=on被包含在列表中\pset选项。请参考\x。\hor\help[command]给出指定SQL命令的语法帮助。如果没有指定
command,则psql会列出可以显示语法帮助的所有命令。如果command是一个星号(),则会显示所有SQL命令的语法帮助。与大部分其他元命令不同,该行的所有剩余部分总是会被当做\help的参数,并且在参数中不会执行变量篡改以及反引号展开。注意为了简化输入,由几个词构成的命令不需要被加上引号。因此,键入*\help alter table\Hor\html开启HTML查询输出格式。如果HTML格式已经开启,这会把它切换回默认的对齐文本格式。这个命令是为了兼容性和方便,有关设置其他输出选项请见
\pset。\ior\includefilename从文件
filename读取输入并且把它当作从键盘输入的命令来执行。如果filename是-(连字符),那么会一直读取标准输入直到碰到一个 EOF 指示符或者\q元命令。这可以用来把交互式输入与文件输入混杂。注意只有在最外层激活了 readline 行为的情况下才将会使用 readline 行为。注意如果想在屏幕上看到被读入的行,必须把变量ECHO设置成all。\ifexpression\elifexpression\else\endif这一组命令实现可嵌套的条件块。条件块必须以一个
\if开始并且以一个\endif结束。两者之间可能有任意数量的\elif子句,后面也可能有选择地跟着一个单一的\else子句。一般查询以及其他类型的反斜线命令可以出现在这些命令之间构成条件块。\if和\elif命令读取它们的参数并且将它们作为布尔表达式进行计算。如果表达式得到真则处理正常继续下去,否则会跳过下面的行直到到达一个匹配的\elif、\else或者\endif。一旦一个\if或者\elif测试成功,同一个块中后面的\elif命令的参数将不会被计算但会被当作为假。跟在一个\else后面的行只有在先前的匹配的\if或\elif成功时才被处理。就像任何其他反斜线命令参数一样,\if或者\elif命令的expression参数服从变量篡改以及反引号展开。然后会像一个on/off选项变量的值一样来计算它。因此,对下列项无歧义、大小写无关的匹配都是有效的值:true、false、1、0、on、off、yes、no。例如,t、T以及tR都将被认为是真。无法被正确计算为真或假的表达式将产生一个警告并且被当做假。正在被跳过的行还是会被正常地解析以标识查询和反斜线命令,但是查询不会被发送到服务器,并且非条件(\if、\elif、\else、\endif)反斜线命令会被忽略。条件命令会被检查以判断嵌套是否有效。被跳过的行中的变量引用不会被展开,并且也不会执行反引号展开。一个给定条件块中的所有反斜线命令必须出现在相同的源文件中。如果在所有的本地\if块被关闭之前,主输入文件或者一个\include进来的文件上就达到了EOF,则psql将产生一个错误。这里是一个例子:1234567891011121314151617-- 检查数据库中两个单独记录的存在性并且把结果存在单独的psql变量中SELECTEXISTS(SELECT 1 FROM customer WHERE customer_id = 123) as is_customer,EXISTS(SELECT 1 FROM employee WHERE employee_id = 456) as is_employee\gset\if :is_customerSELECT * FROM customer WHERE customer_id = 123;\elif :is_employee\echo 'is not a customer but is an employee'SELECT * FROM employee WHERE employee_id = 456;\else\if yes\echo 'not a customer or employee'\else\echo 'this will never print'\endif\endif\iror\include_relativefilename\ir命令类似于\i,但是以不同的方式处理相对路径文件名。在交互模式中执行时,这两个命令的行为相同。不过,当被从脚本中调用时,\ir相对于脚本所在的目录而不是根据当前工作目录来解释文件名。\l[+]or\list[+] [pattern]列出服务器中的数据库并且显示它们的名称、拥有者、字符集编码以及访问特权。如果指定了
pattern,则只列出名称匹配该模式的数据库。如果向命令名称追加+,则还会显示数据库的尺寸、默认表空间以及描述(尺寸信息只对当前用户能连接的数据库可用)。\lo_exportloid从数据库中读取具有OID
loid的大对象并且将它写入到filename。注意这和服务器函数lo_export有微妙的不同,后者会以运行数据库服务器的用户权限来执行并且运行在服务器的文件系统上。提示使用\lo_list可以找出大对象的OID。\lo_importfilename[comment]把该文件存储到PostgreSQL大对象。可选地,它可以把给定的注释关联到该对象。例如:
foo=> *\lo_import '/home/peter/pictures/photo.xcf' 'a picture of me'* lo_import 152801该响应表示该大对象得到的对象 ID 是 152801,未来可以用这个 ID 来访问这个新创建的大对象。为了便于阅读,推荐总是给每一个对象都关联人类可读的注释。OID 和注释都可以用\lo_list命令查看。注意这个命令和服务器端的lo_import有微妙的不同,因为它以本地文件系统上的本地用户的身份运行,而不是服务器用户和文件系统。\lo_list显示当前存储在数据库中的所有PostgreSQL大对象,同时显示它们的任何注释。
\lo_unlinkloid``从数据库中删除OID为
loid的大对象。提示使用\lo_list可以找出该大对象的OID。\oor\out [filename]\oor\out [ |command]安排把未来的查询结果保存到文件
filename中或者用管道导向到 shell 命令command。如果没有指定参数,查询输出会被重置到标准输出。如果该参数以|开始,则该行的所有剩余部分总是会被当做要执行的command,并且在参数中不会执行变量篡改以及反引号展开。该行的剩余部分会被简单地按字面传给shell。“查询结果”包括从数据库服务器得到的所有表、命令响应和提示,还有查询数据库的各种反斜线命令(如\d)的输出,但不包括错误消息。提示要在查询结果之间混入文本输出,可以使用\qecho。\por\print把当前查询缓冲区打印到标准输出。如果当前查询缓冲区为空,会打印最近被执行的查询。
本人提供Oracle(OCP、OCM)、MySQL(OCP)、PostgreSQL(PGCA、PGCE、PGCM)等数据库的培训和考证业务,私聊QQ646634621或微信dbaup66,谢谢!