合 GreenPlum数据库日常维护运维(持续更新)
Tags: GreenPlum整理自网络脚本小麦苗常用DBA脚本脚本分享日常维护日常运维
👉 本文共约15631个字,系统预计阅读时间或需59分钟。
目录
集群修复
查看节点状态
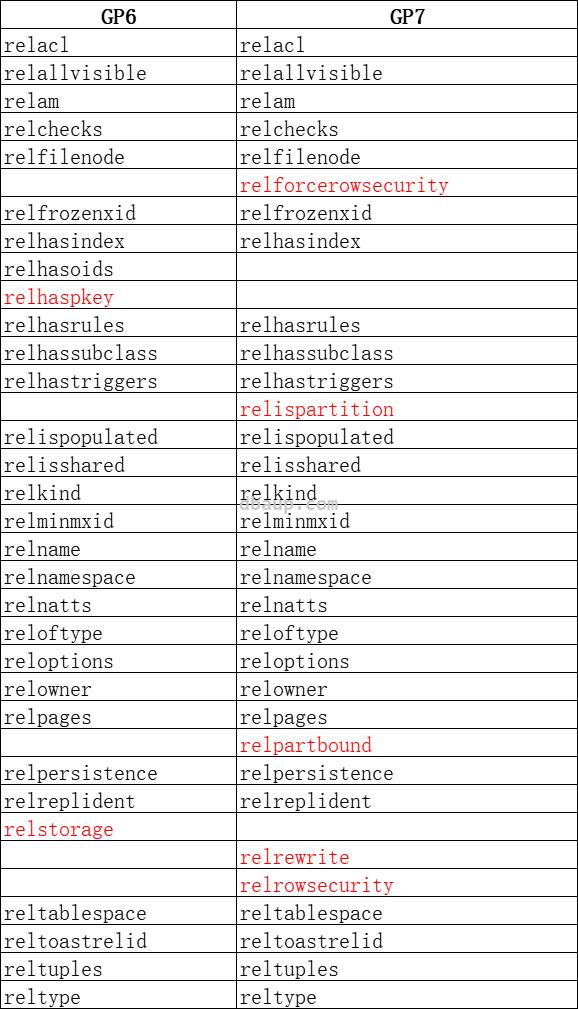
1 2 3 4 | select * from gp_segment_configuration where status='d' or mode <>'s' --查看segment处于down的状态 select * from gp_segment_configuration where status='d' or mode <>'s'--观察数据库是否发生切换 |
修复前负载判定(是否是实例宕机,是否需要kill会话,是否需要重启等)
在查看集群状态为异常后,进一步查看是否存在超过一个小时以上的会话,是否存在锁等情况
1 2 3 4 | select * from gp_segment_configuration; -- 以上语句查询结果中status存在'd'结果,则是存在实例宕机,可以往下继续判断 -- 如果均为'u',可以参考后面的2.6小节 select pid,usename,query_start,client_addr,xact_start,waiting ,waiting_reason,query from pg_stat_activity where state <>'idle' and query_start < now()-interval '1 hour' order by query_start; |
查看节点负载,可以使用1.2中的vmstat命令,也可以使用nmon监控工具(需安装)
c 查看CPU相关信息
m 查看内存相关信息
d 查看磁盘相关信息
n 查看网络相关信息
t 查看相关进程信息
h 查看帮助相关信息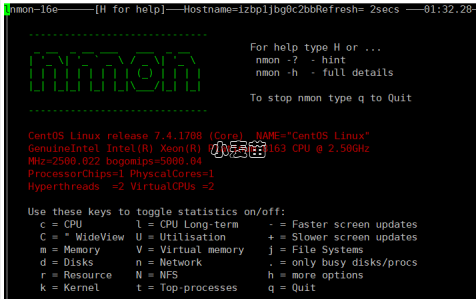

日志备份([可选]判定实例>判定路径>备份日志)
1 2 3 4 5 6 7 8 9 10 | Select con.time, con.dbid, seg.content, seg.status, seg.port, seg.hostname, seg.datadir , con."desc" from gp_segment_configuration seg ,gp_configuration_history con where con.dbid=seg.dbid and seg.status='d' order by con.time desc limit 10; |
集群实例宕机后首要是先恢复集群状态,但这恢复的时候数据节点日志往往会被清理掉,所以可以先备份当天节点日志后,先恢复集群,后面再查看日志寻找宕机的具体原因,根据seg.hostname和seg.datadir,以及 con.time备份对应实例pg_log目录下对应日期的日志
常规修复(以防突然断电或远程断开等情况,一般建议后台运行)
通过gpstate 或gp_configuration 发现有实例down 掉以后,使用该命令进行恢复。
1 | nohup gprecoverseg -a & |
若存在主备切换,则需要在修复完成后进行实例切回
1 | nohup gprecoverseg -ra & |
查看修复进度
1 | gpstate -e |
全量修复方式
1 | nohup gprecoverseg -Fa & |
若存在主备切换,则需要在修复完成后进行实例切回
1 | nohup gprecoverseg -ra & |
非实例宕机的
如果集群状态显示异常,但在2.1中查询结果并不存在实例宕机的情况,可以先查看是否是集群用户存在密码过期导致无法互信的情况

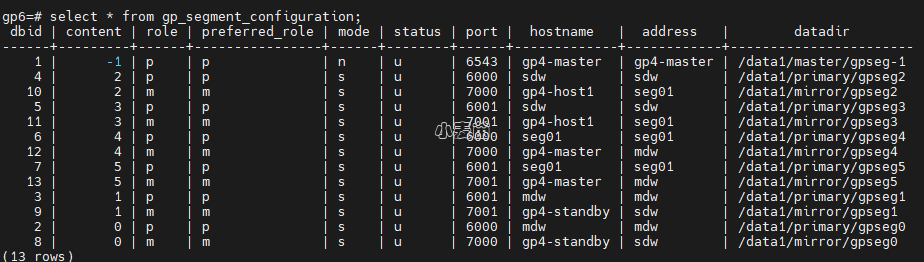
查看互信情况,发现其中一台服务器无法连接,ssh时并提示密码过期
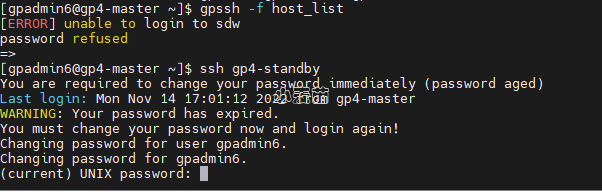
这样就需要重新设置改服务器gpadmin用户的密码或者过期时间即可
用户管理
创建role/schema
创建用户可以使用CREATE USER 或者CREATE ROLE命令,唯一区别是CREATE USER默认情况下假定LOGIN, 而CREATE ROLE默认情况下假定NOLOGIN.
如创建test用户可以登陆资源队列为 pg_default,密码为passwd:
1 | create role test with login resource queue pg_default password 'passwd'; |
创建模式
1 | Create schema test; |
如果是为角色创建一个同名模式:如
1 | Create schema authorization test; |
创建资源队列
本人提供Oracle(OCP、OCM)、MySQL(OCP)、PostgreSQL(PGCA、PGCE、PGCM)等数据库的培训和考证业务,私聊QQ646634621或微信dbaup66,谢谢!