合 OGG之BR(Bounded Recovery )说明
Tags: OGGBR(Bounded Recovery )
- 简介:BR – BOUNDED RECOVERY
- Extract 进程如何恢复未提交的事务
- 1.Extract 按照如下方式执行此恢复过程:
- 2.Bounded Recovery 如何工作的——工作原理
- 3.Bounded Recovery 解决的问题
- 4.Bounded Recovery 示例
- 语法
- 查看BR checkpoint 信息
- Goal
- Solution
- --Version 11.1.1.1
- --Version 11.1.1.0.0
- OGG-01738 BOUNDED RECOVERY
- 1. bug 10368242: transaction loss with BR
- 2. bug 12532428 (base bug 10408077 ): extract hung whenusing BR and new objects are added to extract
- 解决方案
- 配置
- 参考
简介:BR – BOUNDED RECOVERY
适用于 Extract 进程(仅适用于 Oracle数据库)
使用 BR 参数可以控制 GoldenGate 的 Bounded Recovery (BR) 功能。Bounded Recovery 功能仅支持 Oracle 数据库。
Bounded Recovery 是通用 Extract 检查点工具的组件之一,可以保证当Extract 进程出于任何原因(计划停机或意外停机)停止后,无论在进程停止时的时间点上存在多少个未提交的事务还是这些事务持续的时间多么久,Extract 进程都能进行高效地恢复。Bounded Recovery 为 Extract 进程从恢复到其停止的时间点并恢复正常处理所需要的时间设定了一个时间上限。
首先,我们来看两个OGG同步中可能的问题:
oracle在线日志包含已提交的和未提交的事务,但OGG只会将已提交的事务写入到队列文件。因此,针对未提交的事务,特别是未提交的长事务,OGG会怎样处理呢?
有些长事务是在批处理作业中,需要几个小时才能执行完成,比如晚上跑批的作业。OGG在解析过程中,会从这些事务一执行就开始读取在线日志,但这些事务可能会持续很久,在期间,在线日志可能会切换到归档日志,同时这期间也会有其它事务在执行和提交,如果长事务一直未提交,归档日志又因为定期的rman备份而删除,OGG将如何处理?
针对以上情况,OGG有2种处理方式,第一种就是使用正常恢复归档的方式,即恢复OGG需要的所有归档日志,可能是从长事务开始的那个归档开始,这样OGG将从事务开始的检查点开始解析;
第二种方式就是使用Bounded Recovery的方式,下面的内容将讨论这种方式。
简单来说,BR(Bounded Recovery )默认的设置是4小时,即每4小时OGG抽取进程会做一个检查点,在每个检查点的时间点上,OGG会检查长事务,并将超过4小时的长事务的状态写入到磁盘(如果没有达到4小时,则此事务不会被BR写入),默认保存在OGG安装目录的BR目录下。在每个BR的间隔点,这个操作会一直持续,直到事务提交,或事务回滚。The minimum interval is 20 minutes. The maximum is 96 hours. The default interval is 4 hours.
下面的示例中,我们设置BRINTERVAL为20分钟:
1START EXTRACT ext8 BRINTERVAL 20M下面是针对BR的官方文档描述:
使用磁盘持久保存数据,用于恢复长事务,让抽取进程可以确保捕获性能(虽然只有在极端情况下才会发生捕获延迟)。如果抽取进程停止时,有些事务的开始时间远在这个时间点之前,那么系统需要占用大量的日志空间,也有可能这些日志文件不在磁盘上或已被删除。而且,重新从一个很早的日志文件开始读取事务,这种做法是不可接受的,因为这些日志文件中的其它事务已经被解析并被写入到队列文件。
如果通过持久化数据能恢复这些长事务的状态,那么就可以消除这个往返读取的动作。极端的情况下,如果有多个长事务,如果每个事务都要求从起点重新读取,那么OGG的捕获性能将大大降低。
在本示例中,我们将BR的间隔设置为20分钟,然后执行一个insert语句,但不提交。此时,抽取进程会从在线日志的某个点开始读取,在线日志的序号为:#14878。
然后我们切换几组日志,备份并删除序号为14878的日志文件。我们可以看到每隔20分钟,BR checkpoint就会执行,此时,长事务的状态信息及数据就会被写入到磁盘上。即使磁盘上没有对应的归档日志文件,抽取进程也不会再去读取这些日志,而是直接从磁盘上保存的BR数据中进行恢复,如果事务提交,则OGG会直接将BR目录下的数据写入到队列中。
测试步骤如下:
执行下面的INSERT语句,但不提交,用于测试长事务的场景:123SQL> insert into myobjectsselect object_id,object_name,object_type from dba_objects;75372 rows created.通过infor ext1检查当前读取的在线日志序号,本测试中是14878
1234567GGSCI 2> info ext1EXTRACT EXT1 Last Started 2014-06-21 18:07 Status RUNNINGCheckpoint Lag 00:00:00 (updated 00:00:08 ago)Process ID 15190Log Read Checkpoint Oracle Redo Logs2014-06-21 18:10:21 Seqno 14878, RBA 5936128SCN 0.9137531 (9137531)使用SEND EXTRACT SHOWTRANS查看是否有事务是打开状态:
1234567891011121314GGSCI 4> send ext1 showtransSending SHOWTRANS request to EXTRACT EXT1 …Oldest redo log file necessary to restart Extract is:Redo Log Sequence Number 14878, RBA 116752————————————————————XID: 10.16.1533Items: 75372Extract: EXT1Redo Thread: 1Start Time: 2014-06-21:18:10:14SCN: 0.9137521 (9137521)Redo Seq: 14878Redo RBA: 116752Status: RunningINFO EXTRACT SHOWCH会显示抽取进程检查点的更多信息,包括当前事务(日志)中的读取点,写入队列文件的位置等。下面的示例中,第一个检查点是抽取进程启动时的读取点:14861,接着是最早未提交事务的读取点:序号14878,SCN:9137521,最后是抽取进程当前的日志读取检查点,序号仍然是14878,但SCN是9137612,说明在这个未提交的事务之后,DB已经有一些其它操作。
123456789101112131415161718192021222324252627282930313233343536373839GGSCI 5> info ext1 showchEXTRACT EXT1 Last Started 2014-06-21 18:07 Status RUNNINGCheckpoint Lag 00:00:00 (updated 00:00:06 ago)Process ID 15190Log Read Checkpoint Oracle Redo Logs2014-06-21 18:11:41 Seqno 14878, RBA 5977088SCN 0.9137612 (9137612)Current Checkpoint Detail:Read Checkpoint #1Oracle Redo LogStartup Checkpoint (starting position in the data source):Thread #: 1Sequence #: 14861RBA: 5918224Timestamp: 2014-06-21 16:49:33.000000SCN: 0.9129707 (9129707)Redo File: /u01/app/oracle/fast_recovery_area/GGATE1/archivelog/2014_06_21/o1_mf_1_14861_9tbo7pys_.arcRecovery Checkpoint (position of oldest unprocessed transaction in the data source):Thread #: 1Sequence #: 14878RBA: 116752**Timestamp: 2014-06-21 18:10:14.000000SCN: 0.9137521 (9137521)Redo File: /u01/app/oracle/oradata/ggate1/redo03.logCurrent Checkpoint (position of last record read in the data source):Thread #: 1Sequence #: 14878RBA: 5977088**Timestamp: 2014-06-21 18:11:41.000000SCN: 0.9137612 (9137612)Redo File: /u01/app/oracle/oradata/ggate1/redo03.logWrite Checkpoint #1GGS Log TrailCurrent Checkpoint (current write position):Sequence #: 3RBA: 8130790Timestamp: 2014-06-21 18:11:44.414364Extract Trail: ./dirdat/zzTrail Type: RMTTRAIL大约20分钟之后,我们继续使用showch,看看与前面的命令相比,输出有哪些差异:
可以看到,当前读取的在线日志序号已经变为14884(以前是14878)。
但恢复检查点仍然没有变化,与上一个命令执行结果相同。12345678910111213141516171819202122232425262728293031GGSCI 2> info ext1 showchEXTRACT EXT1 Last Started 2014-06-21 18:07 Status RUNNINGCheckpoint Lag 00:00:00 (updated 00:00:04 ago)Process ID 15190Log Read Checkpoint Oracle Redo Logs2014-06-21 18:40:34 Seqno 14884, RBA 72704SCN 0.9139491 (9139491)Current Checkpoint Detail:Read Checkpoint #1Oracle Redo LogStartup Checkpoint (starting position in the data source):Thread #: 1Sequence #: 14861RBA: 5918224Timestamp: 2014-06-21 16:49:33.000000SCN: 0.9129707 (9129707)Redo File: /u01/app/oracle/fast_recovery_area/GGATE1/archivelog/2014_06_21/o1_mf_1_14861_9tbo7pys_.arcRecovery Checkpoint (position of oldest unprocessed transaction in the data source):Thread #: 1Sequence #: 14878RBA: 116752Timestamp: 2014-06-21 18:10:14.000000SCN: 0.9137521 (9137521)Redo File: /u01/app/oracle/oradata/ggate1/redo03.logCurrent Checkpoint (position of last record read in the data source):Thread #: 1Sequence #: 14884RBA: 72704Timestamp: 2014-06-21 18:40:34.000000SCN: 0.9139491 (9139491)Redo File: /u01/app/oracle/oradata/ggate1/redo03.log通过上面的命令,我们看到了BR检查点的相关信息,前面我们把BR间隔从默认4小时改为20分钟,因此,每隔20分钟(本示例中是:18:07,18:27,18:47...),长事务当前的状态信息会被抽取进程写入到磁盘上的BR目录。
因此,我们看到在18:27的BR间隔时间点,BR将在线日志14881的信息持久到磁盘上,如果这个时候extract有错误或重启,extract不再需要从早于14881序号的redo或归档里读取数据。123456789101112131415161718192021BR Previous Recovery Checkpoint:Thread #: 0Sequence #: 0RBA: 0Timestamp: 2014-06-21 18:07:35.982719SCN: Not availableRedo File:BR Begin Recovery Checkpoint:Thread #: 0Sequence #: 14878RBA: 116752Timestamp: 2014-06-21 18:10:14.000000SCN: 0.9137521 (9137521)Redo File:BR End Recovery Checkpoint:Thread #: 1Sequence #: 14881RBA: 139776Timestamp: 2014-06-21 18:27:38.000000SCN: 0.9138688 (9138688)Redo File:在BR目录中我们可以看到抽取进程ext1生成的一些文件:
1234567891011GGSCI 4> info ext1EXTRACT EXT1 Last Started 2014-06-21 18:07 Status RUNNINGCheckpoint Lag 00:00:00 (updated 00:00:06 ago)Process ID 15190Log Read Checkpoint Oracle Redo Logs2014-06-21 18:41:35 Seqno 14884, RBA 131072SCN 0.9139583 (9139583)GGSCI 3> shell ls -l ./BR/EXT1total 20-rw-r—– 1 oracle oinstall 65536 Jun 21 18:27 CP.EXT1.000000015drwxr-x— 2 oracle oinstall 4096 Jun 19 17:07 stale此时,如果我们删除14878的归档日志会怎样呢?因为BR检查点已经将包含长事务的日志序号为14878的信息写入到磁盘,extract进程将不再需要这些旧的归档文件。为了测试这个功能,我们将14878归档备份之后删除,记住,这个序号是长事务开始时的序号,在抽取进程检查点日志中有记录。
123456789101112131415RMAN> backup archivelog sequence 14878 delete input;Starting backup at 21-JUN-14using target database control file instead of recovery catalogallocated channel: ORA_DISK_1channel ORA_DISK_1: SID=24 device type=DISKchannel ORA_DISK_1: starting archived log backup setchannel ORA_DISK_1: specifying archived log(s) in backup setinput archived log thread=1 sequence=14878 RECID=30497 STAMP=850846396channel ORA_DISK_1: starting piece 1 at 21-JUN-14channel ORA_DISK_1: finished piece 1 at 21-JUN-14piece handle=/u01/app/oracle/fast_recovery_area/GGATE1/backupset/2014_06_21/o1_mf_annnn_TAG20140621T234659_9tcb7msp_.bkp tag=TAG20140621T234659 comment=NONEchannel ORA_DISK_1: backup set complete, elapsed time: 00:00:01channel ORA_DISK_1: deleting archived log(s)archived log file name=/u01/app/oracle/fast_recovery_area/GGATE1/archivelog/2014_06_21/o1_mf_1_14878_9tbpowlm_.arc RECID=30497 STAMP=850846396Finished backup at 21-JUN-14好,我们现在来提交这个交易。
12345SQL> insert into myobjects2 select object_id,object_name,object_type from dba_objects;75372 rows created.SQL> commit;Commit complete.在抽取进程ext1的日志报告中,可以看到有长事务的信息、BR检查点的信息,而且每隔20分钟,BR检查点写入的redo日志序号是在增长的,即OGG抽取进程每20分钟会将当前日志序号写入,同时在OGG日志报告中体现出来。
1234567892014-06-21 18:17:42 WARNING OGG-01027 Long Running Transaction: XID 10.16.1533, Items 75372, Extract EXT1, Redo Thread 1, SCN 0.9137521 (9137521), Redo Seq #14878, Redo RBA 116752.2014-06-21 18:27:41 INFO OGG-01971 The previous message, ‘WARNING OGG-01027′, repeated 1 times.2014-06-21 18:27:41 INFO OGG-01738 BOUNDED RECOVERY: CHECKPOINT: for object pool 1: p23540_extr: start=SeqNo: 14878, RBA: 116752, SCN: 0.9137521 (9137521), Timestamp: 2014-06-21 18:10:14.000000, end=SeqNo: 14881, RBA: 139776, SCN: 0.9138688 (9138688), Timestamp: 2014-06-21 18:27:38.000000, Thread: 1.2014-06-21 18:47:50 INFO OGG-01738 BOUNDED RECOVERY: CHECKPOINT: for object pool 1: p23540_extr: start=SeqNo: 14885, RBA: 144912, SCN: 0.9139983 (9139983), Timestamp: 2014-06-21 18:47:47.000000, Thread: 1, end=SeqNo: 14885, RBA: 145408, SCN: 0.9139983 (9139983), Timestamp: 2014-06-21 18:47:47.000000, Thread: 1.2014-06-21 19:07:59 INFO OGG-01738 BOUNDED RECOVERY: CHECKPOINT: for object pool 1: p23540_extr: start=SeqNo: 14889, RBA: 176144, SCN: 0.9141399 (9141399), Timestamp: 2014-06-21 19:07:56.000000, Thread: 1, end=SeqNo: 14889, RBA: 176640, SCN: 0.9141399 (9141399), Timestamp: 2014-06-21 19:07:56.000000, Thread: 1.最后,记住一点:如果使用BR默认的4小时,则当前磁盘上至少要保存过去8小时的归档日志,以便满足任何长事务的要求,当然,在实际生产环境中,往往要求保存的时间会更长。
下面的图示中
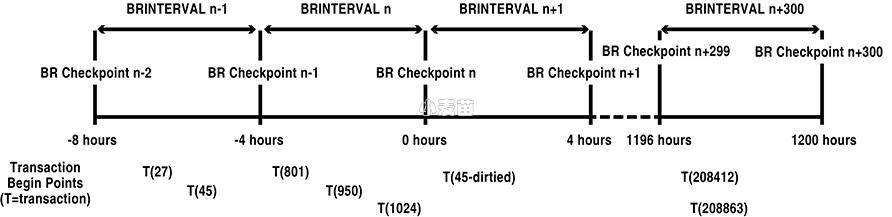
T27, T45开始于BR N-1之前,会在BR N这个检查点上记录状态;而T801是在BR N-1之后开始,在BR N检查点时,由于不满足BR interval的时间要求,因此不会被记录到BR N这个检查点上,而是会记录在BR N+1这个检查点上。
一旦在BR N和BR N+1这个时间范围内,extract当掉,则T801的所有信息丢失,重启extract之后,将会从T801开始的时间点解析日志。
Extract 进程如何恢复未提交的事务
当Extract 进程在 redo log 中遇到某个事务的起点(在 Oracle 中通常为第一个可执行的 sql 语句)时,便会将从该事务中捕获到的所有数据缓存到内存中。即使一开始该事务不包含任何数据,Extract 进程也必须将事务缓存到内存中,因为该事务中后面的操作可能包含要捕获的数据。
当Extract进程在 redo log 中遇到事务的commit 记录,便会将缓存在内存中的整个事务写入trail 文件,并将其从内存中清除。当 Extract 进程遇到事务的rollback 记录时,便会丢弃缓存中所缓存的整个事务。在 Extract 进程处理 commit 或rollback 记录之前,都会视事务为Open状态(未提交或回滚的),并持续不断地收集该事务的信息。
如果Extract 在遇到事务的 commit 或 rollback 记录之前停止,则在Extract 进程重启后,必须对所有缓存在内存中的信息进行恢复。此操作适用于 Extract 进程停止时所有处于 open 状态的事务。
1.Extract 按照如下方式执行此恢复过程:
Ø 如果在 Extract 进程停止时,没有处于 open 状态的事务,则恢复操作从current Extract read checkpoint开始,这是正常的恢复过程。
Ø 如果 redo log 中存在起始点非常接近于 Extract 进程停止时间点的 open事务,则 Extract进程会重新读入redo log,从其中最早的 open事务的起始点开始恢复。此过程需要 Extract 进程对该之前已写入 trail 或 discarded 文件的事务执行重复的工作,但是这项工作只需要处理相对较少的数据,属于可接受的成本范围内。这种恢复也可视为正常恢复。
Ø 如果存在一个或多个 Extract 进程视为长时间运行的 open 事务,则Extract 进程便会通过 BoundedRecovery 进行恢复。
2.Bounded Recovery 如何工作的——工作原理
如果事务处于open 状态的时间超过 BR 参数的BRINTERVAL选项中指定的Bounded
Recovery 间隔,则 OGG 就视该事务为长时间运行的 open 事务。例如,如果 Bounded Recovery 间隔为4小时,则任何持续时间超过4小时的事务都可视为长时间运行的 open 事务。
每隔一个Bounded Recovery 间隔,Extract 都会进行一次Bounded Recovery checkpoint,该检查点操作会将Extract 进程的当前状态和数据写入磁盘,包括任何存在的长时间运行的事务的状态和数据。如果 Extract 进程在一个Bounded Recovery检查点之后停止,则该进程将从上一个Bounded Recovery间隔点或最后一个Bounded Recovery检查点位置进行恢复,而不会从 redo log 或 archived log 中最早的长时间运行open 事务的起始位置开始进行恢复。
Bounded Recovery的最大时间 (Extract恢复到停止时间点的最大时间)永远不会超过当前 Bounded Recovery 检查点间隔的 2 倍。实际的恢复时间将由如下因素决定:
Ø 从 Extract 进程停止开始到最后一个有效的 Bounded Recovery 间隔之间的时间。
Ø 整个恢复期间 Extract 进程的处理情况。
Ø 之前写入磁盘的事务的处理时间比。当首先要进行磁盘写的时候,Bounded Recovery 处理这些事务(丢弃这些事务)要比extract快很多。 大多数事务数据的重新处理都包含此过程。
当Extract 进程进行恢复时,该进程会还原最后一个Bounded Recovery 检查点(包含任何长时间运行的事务)保存的数据和状态。
例如,如果一个事务处于 open 状态的时间有 24 小时,BoundedRecovery 间隔为 4 小时。在这种情况下,Extract 进程最长恢复时间不会超过 8 小时(<=4*2),可能会小于该时间。这取决于 Extract 进程停止的时间点和最后一个有效的 Bounded Recovery 检查点以及 Extract 进程在该期间的活动情况。
3.Bounded Recovery 解决的问题
利用磁盘的持久性来存储和恢复长时间运行的事务,这种情形很少发生,但是一旦发生,这一特性将显著地提高 Extract 进程执行恢复的性能。当 Extract 进程停止时其正在处理的长时间运行的事务在 redo log 中的起始位置通常都在一个非常早(距离当前时间非常久远)的位置。一个长时间运行的事务很可能跨越了大量的老旧的日志文件(online和archived log),这些比较早的日志文件,有些早已通过备份转移到其他的存储设备或者直接删除了。如果通过读取日志从长时间运行的事务在日志当中的起始位置开始进行恢复,则需要大量的时间成本,其实在数据库中长时间运行的事务时非常少的,在此过程中大部分的工作实际上是又捕获了一遍已经写入 trail 或Discarded 文件的其他事务。利用 bounded recovery 可以restore 磁盘上存留的长时间运行的事务信息(同 Oracle 数据库中的 restore 操作类似),可以避免上述的额外重复工作。
4.Bounded Recovery 示例
下图显示的时间轴上,随着时间的推进,一系列的事务开始处理。该图清晰地演示了长时间运行的事务如何以特定的时间间隔持久化(写入或存留)到磁盘,然后在发生故障后进行恢复,它可以帮助我们理解本例中所使用的相关术语:
Ø 持久化对象persisted object是指缓存中已在 Bounded Recovery 检查点过程中持久化的任何对象。通常情况下,此对象就是事务的状态或数据,不过缓存中还应包含一些Extract 进程专用对象。这些对象统称为持久化对象。
Ø 最早的非持久化对象oldest non-persisted object是指当前 Bounded Recovery 检查点之前最近的一个 BR 间隔内,缓存中最早的 open对象。通常情况下,该对象就是该时间间隔内最早的 open 事务。Bounded Recovery 重新开始时,运行时处理就是从最早的非持久化对象的起始位置开始恢复的,在一般的事务处理中,该位置就是该事务在 redo log 中的起始位置。
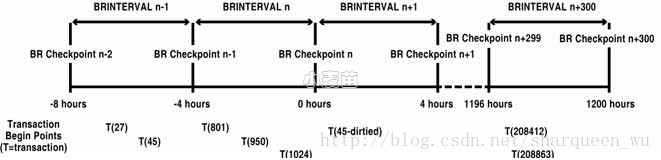
在本例中,BoundedRecovery 间隔为4小时。如果open 事务开始的时间点距离当前的 Bounded Recovery 检查点超过一个 Bounded Recovery 间隔,则该事务就会在当前的 Bounded Recovery 检查点被持久化。
在 BR 检查点 n 处:
● 有 5 个处于open 状态的事务: T(27), T(45), T(801), T(950),T(1024)。所有其他的事务均已提交或回滚。这些事务都从其起始点开始延时间轴不断运行。
● 运行的时间超过一个 Bounded Recovery 间隔的事务有:T(27) 和 T(45),在BR 检查点 n 处,这些事务都会被持久化(写入)磁盘。
● 最早的非持久化对象是 T(801)。该事务不符合持久化到磁盘的条件,因为其运行的时间还没有超过一个 Bounded Recovery 间隔。作为最早的非持久化对象,T(801) 在日志中的起点位置存储在BR 检查点 n的检查点文件中。如果 Extract 进程在 BR 检查点 n 之后意外停止,则该进程将恢复到该日志位置,然后才能重新开始读取解析日志的内容。如果在BR 检查点 n之前的 BoundedRecovery 间隔中没有最早的非持久化的对象,则 Extract 进程就会从当前 Bounded Recovery 检查点的日志位置重新开始读取日志。
在 BR 检查点 n+1 处:
● T(45) 在前一个BoundedRecovery间隔内已经变脏(发生过更新) ,因此该事务将写入到一个新的持久化对象文件中。旧的持久化对象文件将在 BR 检查点 n+1完成后删除。
● 如果 Extract 进程在写 BR检查点 n+1时或在 BR检查点 n 和 BR检查点 n+1 之间的任意BoundedRecovery 检查点间隔内失败,则 Extract 进程将从上一个有效的 BR 检查点 n开始进行恢复。BR检查点 n重新开始的位置就是最早的非持久化事务T(801). 的起点。因此,在最坏情况下,Extract 进程的恢复停止的时间点所需的时间不会超过两个 Bounded Recovery 间隔,在本例中,恢复的最长时间不会超过 8 小时。
在 BR 检查点n+3000 处:
● 系统已经运行了很长时间了。T(27) 和 T(45) 是仅存的持久化事务。T(801) 和 T(950) 已在 BR Checkpoint n+2999 之前的某个时间点提交并写入trail文件。现在仅存的非持久化 open 事务为 T(208412) 和T(208863)。
● BRCheckpoint n+3000已写完。
● 在 BRCheckpoint n+3000 之后的 BR 间隔内,发生了电源故障。
● 新Extract 进程恢复到BRCheckpoint n+3000。 (27) 和T(45) 从包含BRCheckpoint n 的状态的持久化检查点文件还原出来。日志读取从 T(208412) 的起点开始恢复。
语法
1 2 3 4 5 6 7 8 9 10 | Default BR BRINTERVAL 4, BRDIR BR Syntax BR [, BRDIR<directory>] [, BRINTERVAL<interval><unit>] [, BRKEEPSTALEFILES] [, BROFF] [, BROFFONFAILURE] [, BRRESET] |
| Argument | Description |
|---|---|
| BRDIR | Specifies the relative or full path name of the parent directory that will contain the BR directory. The BR directory contains the Bounded Recovery checkpoint files, and the name of this directory cannot be changed. The default parent directory for the BR directory is a directory named BR in the root directory that contains the Oracle GoldenGate installation files. Each Extract group within a given Oracle GoldenGate installation will have its own sub-directory under the directory that is specified with BRDIR. Each of those directories is named for the associated Extract group.For |
| BRINTERVAL | Specifies the time between Bounded Recovery checkpoints. This is known as theBounded Recovery interval. This interval is an integral multiple of the standard Extract checkpoint interval, as controlled by the CHECKPOINTSECS parameter. However, it need not be set exactly. Bounded Recovery will adjust any legal BRINTERVAL parameter internally as it requires.The minimum for <interval>is 20 minutes. The maximum is 96 hours.<unit> can be:◆ M for minutes◆ H for hoursThe default interval is 4 hours. |
| BRKEEPSTALEFILES | Causes old Bounded Recovery checkpoint files to be retained. By default, only current checkpoint files are retained. Extract cannot recover from old Bounded Recovery checkpoint files. Retain old files only at the request of an Oracle support analyst. |
| BROFF | Turns off Bounded Recovery for the run and for recovery. Consult Oracle Support before using this option. In most circumstances, when there is a problem with Bounded Recovery, it turns itself off. |
| BROFFONFAILURE | Disables Bounded Recovery after an error. By default, if Extract encounters an error during Bounded Recovery processing, it reverts to normal recovery, but then enables Bounded Recovery again after recovery completes. BROFFONFAILURE turns Bounded Recovery off for the runtime processing. |
| BRRESET | command line. To run Extract from the command line:replicat paramfile |
Example BR BRDIR /user/checkpt/br specifies that the Bounded Recovery checkpoint files willbe created in the /user/checkpt/br directory.
查看BR checkpoint 信息
Goal
How can the Extract BR (bounded recovery)checkpoint information in Oracle GoldenGate (OGG) be seen?
Solution
The BR checkpoint information is shown inthe SHOWCH output starting with OGG v11.1.1.1
Following is an example showing the BRcheckpoint information on the extract along with the
standard recovery checkpoint details.
--Version 11.1.1.1
GGSCI (cdb2) 3> info ext1, showch
EXTRACT EXT1 Last Started 2014-05-28 09:26 Status RUNNING
CheckpointLag 00:00:00 (updated 00:00:10 ago)
Log ReadCheckpoint Oracle Redo Logs
2014-05-28 14:30:07 Thread 1, Seqno 6115, RBA 58318336
Log ReadCheckpoint Oracle Redo Logs
2014-05-28 14:30:05 Thread 2, Seqno 6260, RBA 2146304
CurrentCheckpoint Detail:
Read Checkpoint #1
Oracle RAC Redo Log
Startup Checkpoint (starting position in thedata source):
Thread #: 1
Sequence #: 6108
RBA: 88603664
Timestamp: 2014-05-28 09:26:38.000000
SCN: Not available
Redo File: /dev/raw/rredo2_3
Recovery Checkpoint (position of oldestunprocessed transaction in the data source):
Thread #: 1
Sequence #: 6115
RBA: 58316816
Timestamp: 2014-05-28 14:30:07.000000
SCN: 0.377889779 (377889779)
Redo File: /dev/raw/rredo1_1
Current Checkpoint (position of last recordread in the data source):
Thread #: 1
Sequence #: 6115
RBA: 58318336
Timestamp: 2014-05-28 14:30:07.000000
SCN: 0.377889779 (377889779)
RedoFile: /dev/raw/rredo1_1
BR Previous RecoveryCheckpoint:
Thread #: 1
Sequence #: 0
RBA: 0
Timestamp: 2014-05-28 09:26:41.285711
SCN: Not available
Redo File:
BR Begin RecoveryCheckpoint:
Thread #: 1
Sequence #: 6108
RBA: 89926672
Timestamp: 2014-05-28 09:26:58.000000
SCN: 0.377259452 (377259452)
Redo File:
BR End RecoveryCheckpoint:
Thread #: 1
Sequence #: 6113
RBA: 93254656
Timestamp: 2014-05-28 13:26:40.000000
SCN: 0.377726964 (377726964)
Redo File:
Read Checkpoint #2
Oracle RAC Redo Log
Startup Checkpoint (starting position in thedata source):
Thread #: 2
Sequence #: 6258
RBA: 162832
Timestamp: 2014-05-28 09:26:38.000000
SCN: Not available
Redo File: /dev/raw/rredo2_3
Recovery Checkpoint (position of oldestunprocessed transaction in the data source):
Thread #: 2
Sequence #: 6260
RBA: 2145808
Timestamp: 2014-05-28 14:30:05.000000
SCN: 0.377889243 (377889243)
Redo File: /dev/raw/rredo2_2
Current Checkpoint (position of last recordread in the data source):